Apache Kafka Connect – A Complete Guide
Kafka course with real-time projects Start Now!!
Today, we are going to discuss Apache Kafka Connect. This Kafka Connect article carries information about types of Kafka Connector, features and limitations of Kafka Connect.
Moreover, we will learn the need for Kafka Connect and its configuration. Along with this, we will discuss different modes and Rest API.
In this Kafka Connect Tutorial, we will study how to import data from external systems into Apache Kafka topics, and also to export data from Kafka topics into external systems, we have another component of the Apache Kafka project, that is Kafka Connect.
However, there is much more to learn about Kafka Connect.
So, let’s start Kafka Connect.
What is Kafka Connect?
We use Apache Kafka Connect for streaming data between Apache Kafka and other systems, scalably as well as reliably. Moreover, connect makes it very simple to quickly define Kafka connectors that move large collections of data into and out of Kafka.
Kafka Connect collects metrics or takes the entire database from application servers into Kafka Topic. It can make available data with low latency for Stream processing.
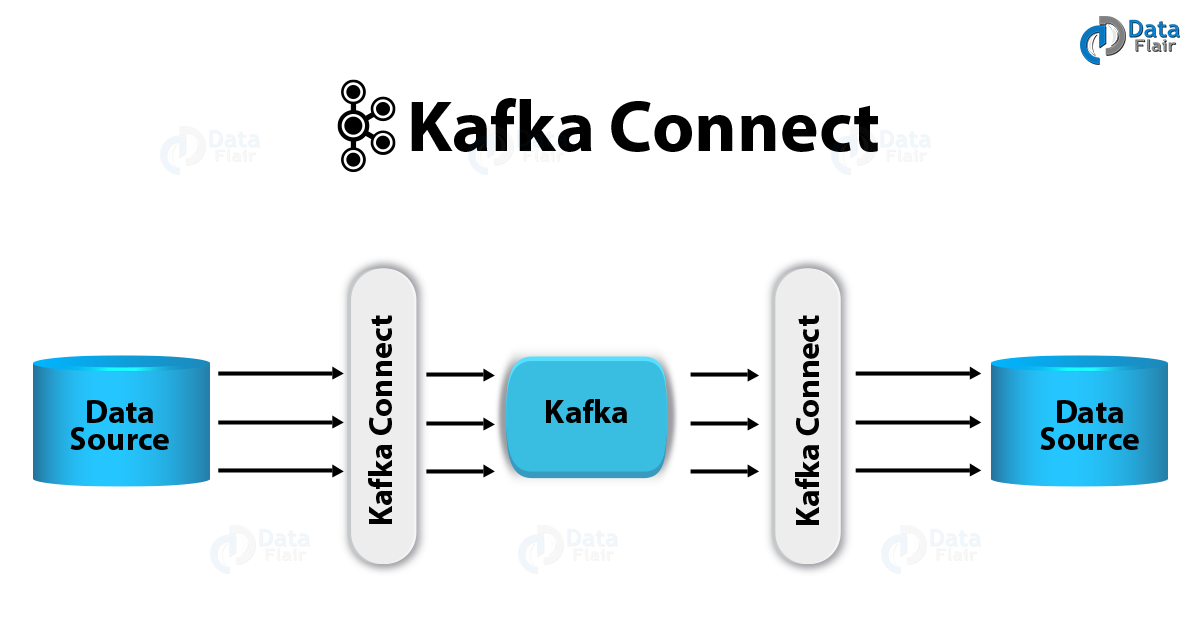
Working – Apache Kafka Connect
Kafka Connect Features
There are following features of Kafka Connect:
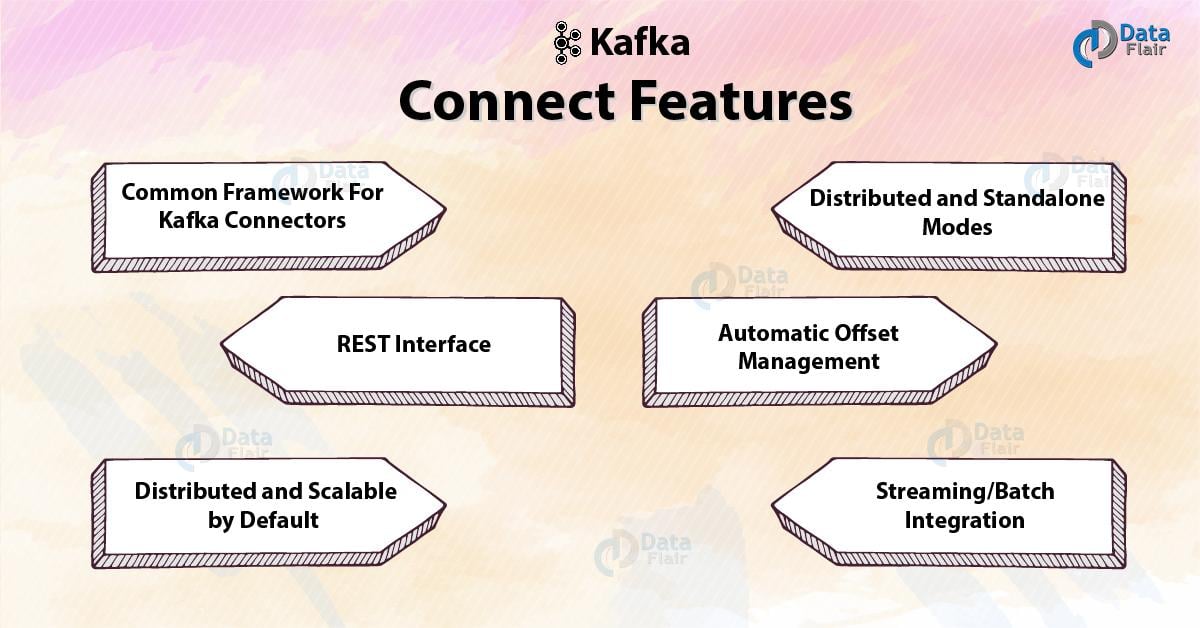
Kafka Connect – Features
a. A common framework for Kafka connectors
It standardizes the integration of other data systems with Kafka. Also, simplifies connector development, deployment, and management.
b. Distributed and standalone modes
Scale up to a large, centrally managed service supporting an entire organization or scale down to development, testing, and small production deployments.
c. REST interface
By an easy to use REST API, we can submit and manage connectors to our Kafka Connect cluster.
d. Automatic offset management
However, Kafka Connect can manage the offset commit process automatically even with just a little information from connectors. Hence, connector developers do not need to worry about this error-prone part of connector development.
e. Distributed and scalable by default
It builds upon the existing group management protocol. And to scale up a Kafka Connect cluster we can add more workers.
f. Streaming/batch integration
We can say for bridging streaming and batch data systems, Kafka Connect is an ideal solution.
Why Kafka Connect?
As we know, like Flume, there are many tools which are capable of writing to Kafka or reading from Kafka or also can import and export data. So, the question occurs, why do we need Kafka Connect. Hence, here we are listing the primary advantages:
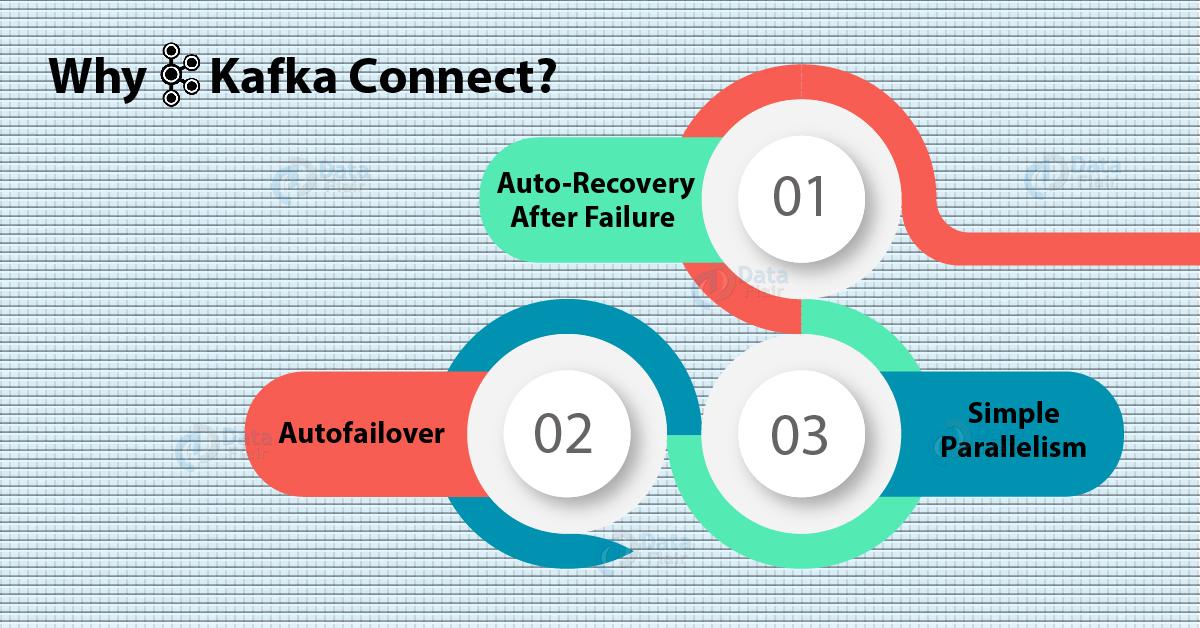
Why Kafka Connect- Need for Kafka
a. Auto-recovery After Failure
To each record, a “source” connector can attach arbitrary “source location” information which it passes to Kafka Connect.
Hence, at the time of failure Kafka Connect will automatically provide this information back to the connector. In this way, it can resume where it failed. Additionally, auto recovery for “sink” connectors is even easier.
b. Auto-failover
Auto-failover is possible because the Kafka Connect nodes build a Kafka cluster. That means if suppose one node fails the work that it is doing is redistributed to other nodes.
c. Simple Parallelism
A connector can define data import or export tasks, especially which execute in parallel.
Kafka Connect Concepts
- An operating-system process (Java-based) which executes connectors and their associated tasks in child threads, is what we call a Kafka Connect worker.
- Also, there is an object that defines parameters for one or more tasks which should actually do the work of importing or exporting data, is what we call a connector.
- To read from some arbitrary input and write to Kafka, a source connector generates tasks.
- In order to read from Kafka and write to some arbitrary output, a sink connector generates tasks.
However, we can say Kafka Connect is not an option for significant data transformation. In spite of all, to define basic data transformations, the most recent versions of Kafka Connect allow the configuration parameters for a connector.
Whereas, for “source” connectors, this function considers that the tasks transform their input into AVRO or JSON format; the transformation is applied just before writing the record to a Kafka topic.
And, while it comes to “sink” connectors, this function considers that data on the input Kafka topic is already in AVRO or JSON format.
Dependencies of Kafka Connect
Kafka Connect nodes require a connection to a Kafka message-broker cluster, whether run in stand-alone or distributed mode.
Basically, there are no other dependencies, for distributed mode. Even when the connector configuration settings are stored in a Kafka message topic, Kafka Connect nodes are completely stateless. Due to this, Kafka Connect nodes, it becomes very suitable for running via technology.
Although to store the “current location” and the connector configuration, we need a small amount of local disk storage, for standalone mode.
Distributed Mode
By using a Kafka Broker address, we can start a Kafka Connect worker instance (i.e. a java process), the names of several Kafka topics for “internal use” and a “group id” parameter.
By the “internal use” Kafka topics, each worker instance coordinates with other worker instances belonging to the same group-id. Here, everything is done via the Kafka message broker, no other external coordination mechanism is needed (no Zookeeper, etc).
The workers negotiate between themselves (via the topics) on how to distribute the set of connectors and tasks across the available set of workers.
If a worker process dies, the cluster is rebalanced to distribute the work fairly over the remaining workers. If a new worker starts work, a rebalance ensures it takes over some work from the existing workers.
Standalone Mode
We can say, it is simply distributed-mode, where a worker instance uses no internal topics within the Kafka message broker. This process runs all specified connectors, and their generated tasks, itself (as threads).
Because standalone mode stores current source offsets in a local file, it does not use Kafka Connect “internal topics” for storage. As a command line option, information about the connectors to execute is provided, in standalone mode.
Moreover, in this mode, running a connector can be valid for production systems; through this way, we execute most ETL-style workloads traditionally since the past.
So, here again, we are managing failover in the traditional way – e.g by scripts starting an alternate instance.
a. Launching a Worker
A worker instance is simply a Java process. Usually, it is launched via a provided shell-script. Then, from its CLASSPATH the worker instance loads whichever custom connectors are specified by the connector configuration.
For standalone mode, the configuration is provided on the command line and for distributed mode read from a Kafka topic.
For launching a Kafka Connect worker, there is also a standard Docker container image. So, any number of instances of this image can be launched and also will automatically federate together as long as they are configured with the same Kafka message broker cluster and group-id.
REST API
Basically, each worker instance starts an embedded web server. So, through that, it exposes a REST API for status-queries and configuration.
Moreover, configuration uploaded via this REST API is saved in internal Kafka message broker topics, for workers in distributed mode. However, the configuration REST APIs are not relevant, for workers in standalone mode.
By wrapping the worker REST API, the Confluent Control Center provides much of its Kafka-connect-management UI.
To periodically obtain system status, Nagios or REST calls could perform monitoring of Kafka Connect daemons potentially.
Kafka Connector Types
By implementing a specific Java interface, it is possible to create a connector. We have a set of existing connectors, or also a facility that we can write custom ones for us.
Its worker simply expects the implementation for any connector and task classes it executes to be present in its classpath. However, without the benefit of child classloaders, this code is loaded directly into the application, an OSGi framework, or similar.
There are several connectors available in the “Confluent Open Source Edition” download package, they are:
- JDBC
- HDFS
- S3
- Elasticsearch
However, there is no way to download these connectors individually, but we can extract them from Confluent Open Source as they are open-source, also we can download and copy it into a standard Kafka installation.
Configuring Kafka Connect
Generally, with a command line option pointing to a config-file containing options for the worker instance, each worker instance starts. For example Kafka message broker details, group-id.
However, a worker is also given a command line option pointing to a config-file defining the connectors to be executed, in a standalone mode. Whereas, each worker instead retrieves connector/task configuration from a Kafka topic (specified in the worker config file), in distributed mode.
Also, a worker process provides a REST API for status-checks etc, in standalone mode.
Moreover, to pause and resume connectors, we can use the REST API.
It is very important to note that Configuration options “key.converter” and “value.converter” options are not connector-specific, they are worker-specific.
Connections from Kafka Connect Workers to Kafka Brokers
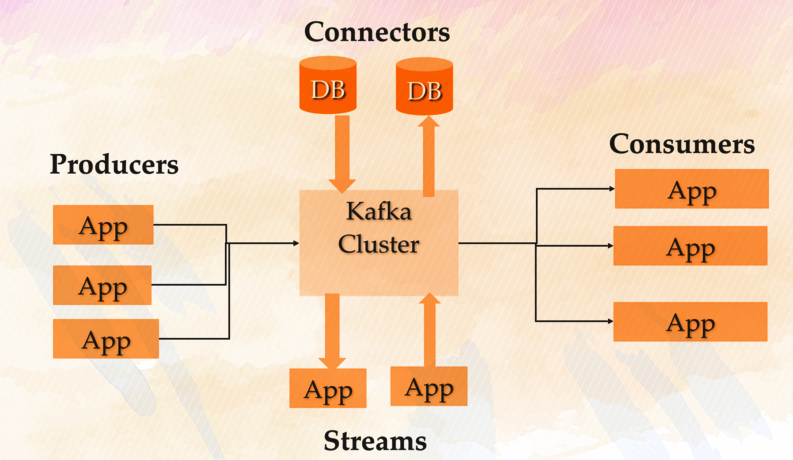
For administrative purposes, each worker establishes a connection to the Kafka message broker cluster in distributed mode. However, in the worker configuration file, we define these settings as “top level” settings.
Moreover, a separate connection (set of sockets) to the Kafka message broker cluster is established, for each connector.
Many of the settings are inherited from the “top level” Kafka settings, but they can be overridden with config prefix “consumer.” (used by sinks) or “producer.” (used by sources) in order to use different Kafka message broker network settings for connections carrying production data vs connections carrying admin messages.
The Standard JDBC Source Connector
The connector hub site lists a JDBC source connector, and this connector is part of the Confluent Open Source download.
Also, make sure we cannot download it separately, so for users who have installed the “pure” Kafka bundle from Apache instead of the Confluent bundle, must extract this connector from the Confluent bundle and copy it over.
There are various configuration options for it:
- A database to scan, specified as a JDBC URL.
- A poll interval.
- A regular expression specifying which tables to watch; for each table, a separate Kafka topic is there.
- An SQL column which has an “incrementing id”, in which case the connector can detect new records (select where id > last-known-id).
- An SQL column with an updated-timestamp in which case the connector can detect new/modified records (select where timestamp > last-known-timestamp).
Strangely, although the connector is apparently designed with the ability to copy, multiple tables, the “incrementing id” and “timestamp” column-names are global – i.e. when multiple tables are being copied then they must all follow the same naming convention for these columns.
Kafka Connect Security
Basically, with Kerberos-secured Kafka message brokers, Kafka Connect (v0.10.1.0) works very fine. Also works fine with SSL-encrypted connections to these brokers.
However, via either Kerberos or SSL, it is not possible to protect the REST API which Kafka Connect nodes expose; though, there is a feature-request for this.
Hence, it is essential to configure an external proxy (eg Apache HTTP) to act as a secure gateway to the REST services, when configuring a secure cluster.
Limitations of Kafka Connect
Apart from all, Kafka Connect has some limitations too:
- At the current time, there is a very less selection of connectors.
- Separation of commercial and open-source features is very poor.
- Also, it lacks configuration tools.
- To deploying custom connectors (plugins), there is a poor/primitive approach.
- It is very much Java/Scala centric.
Hence, currently, it feels more like a “bag of tools” than a packaged solution at the current time – at least without purchasing commercial tools.
So, this was all about Apache Kafka Connect. Hope you like our explanation.
Summary
Hence, we have seen the whole concept of Kafka Connect. Also, we have learned the benefits of Kafka connect. However, if any doubt occurs, feel free to ask in the comment section.
Your opinion matters
Please write your valuable feedback about DataFlair on Google





Hi Auther,
We have a requirement that calls no. of APIs (producer) to get bulk of data and send to the consumer in different formats like json/csv/excel etc after some transformation. It’s a scheduler based, not live streaming. So will kafka connect be a suited one for this requirement?
Kafka connect should not be used for the listed case. Either opt in for any cloud service like msk to move data.