Kafka Streams | Stream, Real-Time Processing & Features
Kafka course with real-time projects Start Now!!
In our previous Kafka tutorial, we discussed ZooKeeper in Kafka. Today, in this Kafka Streams tutorial, we will learn the actual meaning of Streams in Kafka.
Also, we will see Kafka Stream architecture, use cases, and Kafka streams feature. Moreover, we will discuss stream processing topology in Apache Kafka.
Kafka Streams is a client library for building applications and microservices, especially, where the input and output data are stored in Apache Kafka Clusters.
Basically, with the benefits of Kafka’s server-side cluster technology, Kafka Streams combines the simplicity of writing and deploying standard Java and Scala applications on the client side.
So, let’s begin with Apache Kafka Streams.
First, let’s discuss a little about Stream and Real-Time Kafka Processing
Stream & Real-Time Processing in Kafka
The real-time processing of data continuously, concurrently, and in a record-by-record fashion is what we call Kafka Stream processing.
Real-time processing in Kafka is one of the applications of Kafka.
Basically, Kafka Real-time processing includes a continuous stream of data. Hence, after the analysis of that data, we get some useful data out of it.
Now, while it comes to Kafka, real-time processing typically involves reading data from a topic (source), doing some analysis or transformation work, and then writing the results back to another topic (sink). To do this type of work, there are several options.
Either we can write our own custom code with a Kafka Consumer to read the data and write that data via a Kafka Producer.
Or we use a full-fledged stream processing framework like Spark Streaming, Flink, Storm, etc.
However, there is an alternative to the above options, i.e. Kafka Streams. So, let’s learn about Kafka Streams.
What is Kafka Streams?
Kafka Streams, a client library, we use it to process and analyze data stored in Kafka.
It relied on important streams processing concepts like properly distinguishing between event time and processing time, windowing support, and simple yet efficient management and real-time querying of application state.
In addition, Kafka Streams has a low barrier to entry that means we can quickly write and run a small-scale proof-of-concept on a single machine. For that, we only need to run additional instances of our application on multiple machines to scale up to high-volume production workloads.
Moreover, by leveraging Kafka’s parallelism model, it transparently handles the load balancing of multiple instances of the same application.
Some key points related to Kafka Streams:
- Kafka Stream can be easily embedded in any Java application and integrated with any existing packaging, deployment and operational tools that users have for their streaming applications because it is a simple and lightweight client library.
- There are no external dependencies on systems other than Apache Kafka itself as the internal messaging layer.
- In order to enable very fast and efficient stateful operations (windowed joins and aggregations), it supports the fault-tolerant local state.
- To guarantee that each record will be processed once and only once even when there is a failure on either Streams clients or Kafka brokers in the middle of processing, it offers exactly-once processing semantics.
- In order to achieve millisecond processing latency, employs one-record-at-a-time processing. Also, with the late arrival of records, it supports event-time based windowing operations.
- Along with a high-level Streams DSL and a low-level Processor API, it offers necessary stream processing primitives.
Stream Processing Topology in Kafka
- Kafka Streams most important abstraction is a stream. Basically, it represents an unbounded, continuously updating data set. In other words, on order, replayable, and fault-tolerant sequence of immutable data records, where a data record is defined as a key-value pair, is what we call a stream.
- Moreover, any program that makes use of the Kafka Streams library, is a stream processing application. Through one or more processor topologies, it defines its computational logic, especially where a processor topology is a graph of stream processors (nodes) that are connected by streams (edges).
- In the Stream processor topology, there is a node we call a stream processor. It represents a processing step to transform data in streams by receiving one input record at a time from its upstream processors in the topology, applying its operation to it. Also, may subsequently produce one or more output records to its downstream processors.
Two special processors in the topology of Kafka Streams are:
a. Source Processor
It is a special type of stream processor which does not have any upstream processors. By consuming records from one or multiple Kafka topics and forwarding them to its down-stream processors it produces an input stream to its topology.
b. Sink Processor
Unlike, Source Processor, this stream processor does not have down-stream processors. Basically, it sends any received records from its up-stream processors to a specified Kafka topic.
Note: While processing the current record, other remote systems can also be accessed in normal processor nodes. Thus, the processed results can either be streamed back into Kafka or written to an external system.
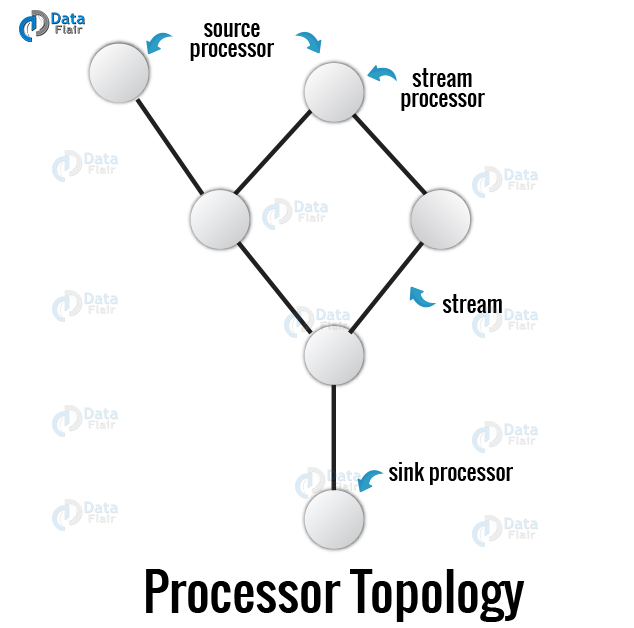
Kafka stream Processor Topology
Kafka Streams Architecture
Basically, by building on the Kafka producer and consumer libraries and leveraging the native capabilities of Kafka to offer data parallelism, distributed coordination, fault tolerance, and operational simplicity, Kafka Streams simplifies application development.
Below image describes the anatomy of an application that uses the Kafka Streams library.
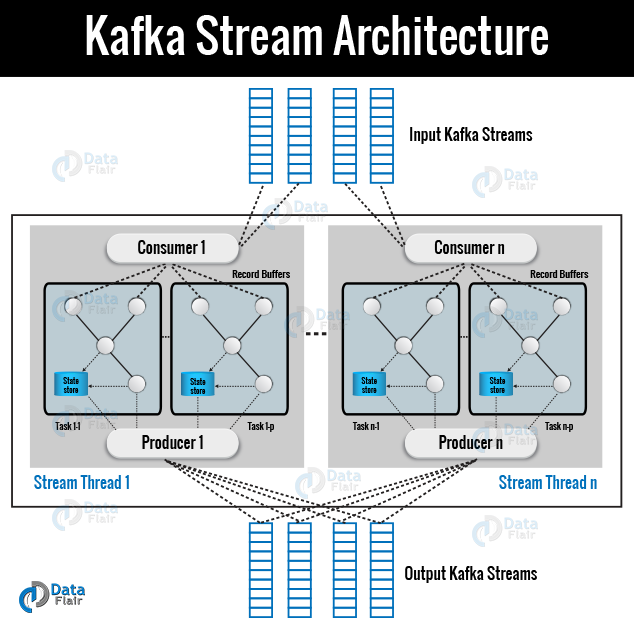
Kafka Streams Architecture
a. Streams Partitions and Tasks
However, for storing and transporting, the messaging layer of Kafka partitions data. Similarly, for processing data Kafka Streams partitions it.
So, we can say partitioning is what enables data locality, elasticity, scalability, high performance, and fault tolerance. In the context of parallelism there are close links between Kafka Streams and Kafka:
- Each Kafka streams partition is a sequence of data records in order and maps to a Kafka topic partition.
- A data record in the stream maps to a Kafka message from that topic.
- In both Kafka and Kafka Streams, the keys of data records determine the partitioning of data, i.e., keys of data records decide the route to specific partitions within topics.
Moreover, by breaking an application’s processor topology into multiple tasks, it gets scaled. However, on the basis of input stream partitions for the application, Kafka Streams creates a fixed number of tasks, with each task assigned a list of partitions from the input streams in Kafka (i.e., Kafka topics).
Also, without manual intervention, Kafka stream tasks can be processed independently as well as in parallel.
Below image describes two tasks each assigned with one partition of the input streams.
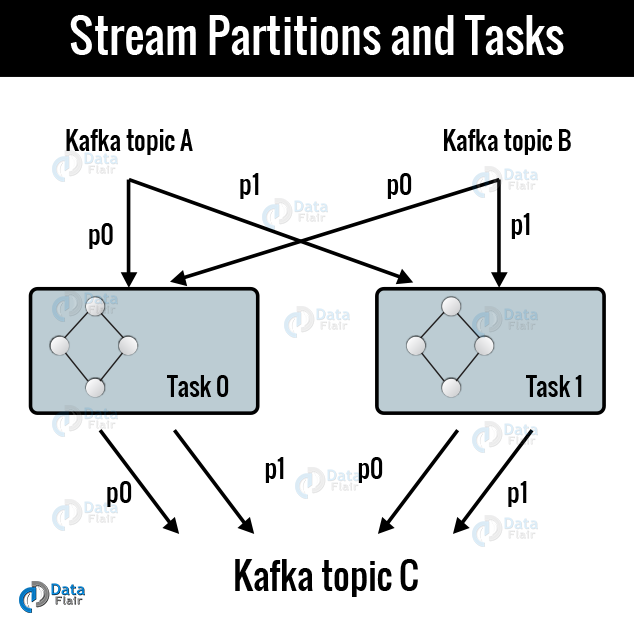
Kafka stream Architecture- Streams Partitions and Tasks
b. Threading Model
Kafka Streams allows the user to configure the number of threads that the library can use for parallelizing process within an application instance.
However, with their processor topologies independently, each thread can execute one or more tasks. For example, below image describes one stream thread running two-stream tasks.
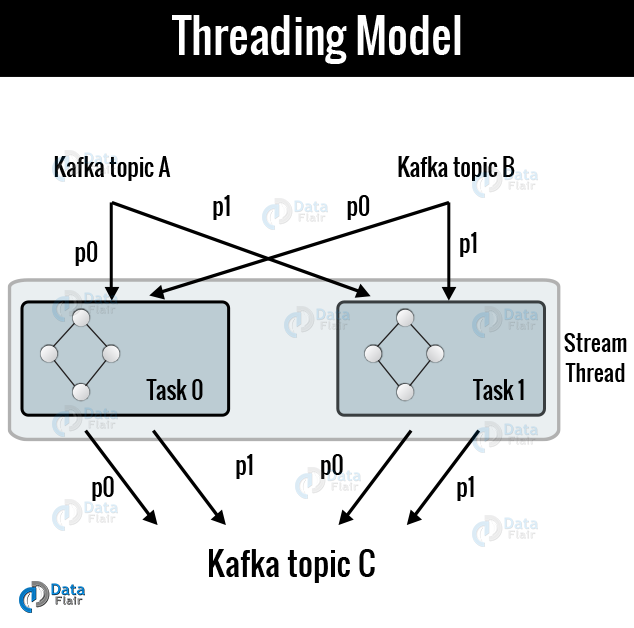
Kafka stream architecture- Threading Model
c. Local State Stores
Kafka Streams offers so-called state stores. Basically, we use it to store and query data by stream processing applications, which is an important capability while implementing stateful operations.
For example, the Kafka Streams DSL automatically creates and manages such state stores when you are calling stateful operators such as join() or aggregate(), or when you are windowing a stream.
In Kafka Streams application, every stream task may embed one or more local state stores that even APIs can access to the store and query data required for processing. Moreover, such local state stores Kafka Streams offers fault-tolerance and automatic recovery.
Below image describes two stream tasks with their dedicated local state stores.
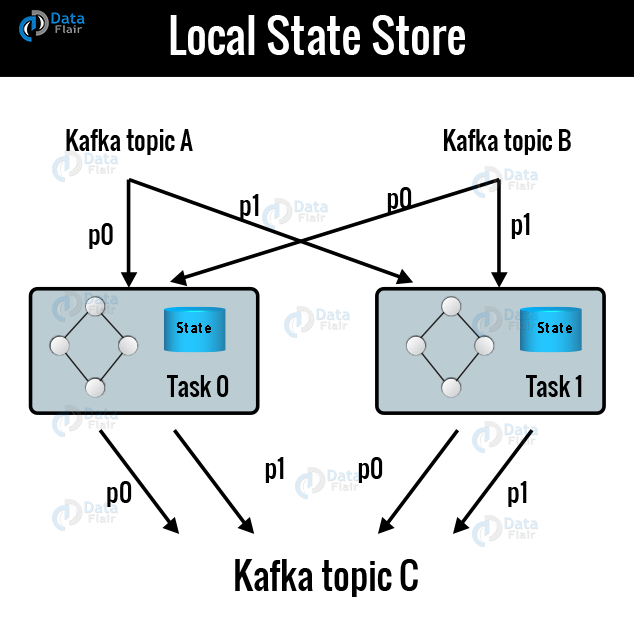
Kafka streams- Local State Store
d. Fault Tolerance
However, integrated natively within Kafka, it is built on fault-tolerance capabilities. While stream data is persisted to Kafka it is available even if the application fails and needs to re-process it.
Moreover, to handle failures, tasks in Kafka Streams leverage the fault-tolerance capability offered by the Kafka consumer client.
In addition, here local state stores are also robust to failures. Hence, it maintains a replicated changelog Kafka topic in which it tracks any state updates, for each state store.
Kafka Streams guarantees to restore their associated state stores to the content before the failure by replaying the corresponding changelog topics prior to resuming the processing on the newly started tasks if tasks run on a machine that fails and is restarted on another machine.
Hence, failure handling is completely transparent to the end-user.
Implementing Kafka Streams
Basically, built with Kafka Streams, a stream processing application looks like:
a. Providing Stream Configurations
Properties streamsConfiguration = new Properties();
streamsConfiguration.put(StreamsConfig.APPLICATION_ID_CONFIG, “Streaming-QuickStart”);
streamsConfiguration.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, “localhost:9092”);
streamsConfiguration.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
streamsConfiguration.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
b. Getting Topic and Serdes
String topic = configReader.getKStreamTopic();
String producerTopic = configReader.getKafkaTopic();
final Serde stringSerde = Serdes.String();
final Serde longSerde = Serdes.Long();
c. Building the Stream and Fetching Data
KStreamBuilder builder = new KStreamBuilder();
KStream<String, String> inputStreamData = builder.stream(stringSerde, stringSerde, producerTopic);
d. Processing of Kafka Stream
KStream<String, Long> processedStream = inputStreamData.mapValues(record -> record.length() )
There is a list of other transformation operations provided for KStream, apart from join and aggregate operations. Hence, each of these operations may generate either one or more KStream objects. Also, can be translated into one or more connected processors into the underlying processor topology.
Moreover, to compose a complex processor topology, all of these transformation methods can be chained together.
Among these transformations, filter, map, mapValues, etc., are stateless transformation operations with which users can pass a customized function as a parameter, such as a predicate for the filter, KeyValueMapper for the map, etc. as per their usage in a language.
e. Writing Streams Back to Kafka
processedStream.to(stringSerde, longSerde, topic);
Here, even after initialization of internal structures, the processing doesn’t start. So, by calling the start() method, we have to explicitly start the Kafka Streams thread:
KafkaStreams streams = new KafkaStreams(builder, streamsConfiguration);
streams.start();
Hence, the last step is closing the Stream.
Features of Kafka Streams
- The best features are elasticity, high scalability, and fault-tolerance.
- Deploy to containers, VMs, bare metal, cloud.
- For small, medium, & large use cases, it is equally viable.
- It is fully in integration with Kafka security.
- Write standard Java applications.
- Exactly-once processing semantics.
- There is no need of separate processing cluster.
- It is developed on Mac, Linux, Windows.
Kafka Streams Use Cases
a. The New York Times
In order to store and distribute, in real-time, published content to the various applications and systems that make it available to the readers, it uses Apache Kafka and the Kafka Streams.
b. Zalando
Zalando uses Kafka as an ESB (Enterprise Service Bus) as the leading online fashion retailer in Europe. That helps them in transitioning from a monolithic to a micro-services architecture. Moreover, using Kafka for processing event streams their technical team does near-real-time business intelligence.
c. LINE
To communicate to one another LINE uses Apache Kafka as a central data hub for their services. As in Line, hundreds of billions of messages are produced daily and are used to execute various business logic, threat detection, search indexing and data analysis.
Also, Kafka helps LINE to reliably transform and filter topics enabling sub-topics consumers can efficiently consume and meanwhile retains easy maintainability.
d. Pinterest
In order to power the real-time, predictive budgeting system of their advertising infrastructure, Pinterest uses Apache Kafka and the Kafka Streams at large scale. There spend predictions are more accurate than ever, with Kafka Streams.
e. Rabobank
Apache Kafka powers digital nervous system, the Business Event Bus of the Rabobank. It is one of the 3 largest banks in the Netherlands. By using Kafka Streams, this service alerts customers in real-time on financial events.
Conclusion
Hence, we have learned the concept of Apache Kafka Streams in detail. We discussed Stream Processing and Real-Time Processing. Moreover, we saw Stream Processing Topology and its special processor.
Afterward, we move on to Kafka Stream architecture and implementing Kafka Streams. Finally, we looked at features and use cases of Kafka Streams. Still, if any doubt occurs feel free to ask. We will definitely respond to you back.
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google




