Apache Kafka Topic – Architecture & Partitions
Kafka course with real-time projects Start Now!!
In this Kafka article, we will learn the whole concept of a Kafka Topic along with Kafka Architecture. Where architecture in Kafka includes replication, Failover as well as Parallel Processing.
In addition, we will also see the way to create a Kafka topic and example of Apache Kafka Topic to understand Kafka well. Moreover, we will see Kafka partitioning and Kafka log partitioning.
So, let’s begin with the Kafka Topic.
What is Kafka Topic?
Simply put, a named stream of records is what we call Kafka Topic. Basically, in logs Kafka stores topics. However, a topic log in Apache Kafka is broken up into several partitions.
And, further, Kafka spreads those log’s partitions across multiple servers or disks. In other words, we can say a topic in Kafka is a category, stream name or a feed.
What is the Topic in Kafka
In addition, we can say Topics in Apache Kafka are inherently published as well as subscribe style messaging.
Moreover, there can be zero or many subscribers called Kafka Consumer Groups in a Kafka Topic. Basically, these Topics in Kafka are broken up into partitions for speed, scalability, as well as size.
How to Create a Kafka Topic
At very first, run kafka-topics.sh and specify the topic name, replication factor, and other attributes, to create a topic in Kafka:
/bin/kafka-topics.sh --create \ --zookeeper <hostname>:<port> \ --topic <topic-name> \ --partitions <number-of-partitions> \ --replication-factor <number-of-replicating-servers>
Now, with one partition and one replica, below example creates a topic named “test1”:
bin/kafka-topics.sh --create \ --zookeeper localhost:2181 \ --replication-factor 1 \ --partitions 1 \ --topic text
Further, run the list topic command, to view the topic:
> bin/kafka-topics.sh --list --zookeeper localhost:2181 test1
Make sure, when applications attempt to produce, consume, or fetch metadata for a nonexistent topic, the auto.create.topics.enable property, when set to true, automatically creates topics.
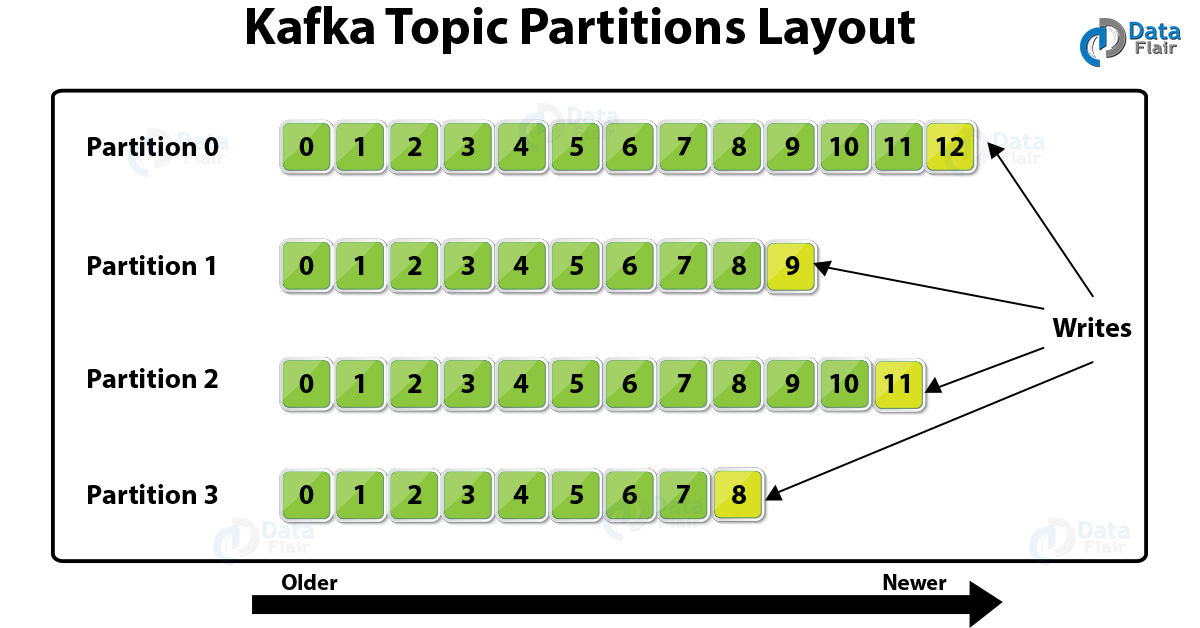
Kafka Topic Partitions
Further, Kafka breaks topic logs up into several partitions. So, usually by record key if the key is present and round-robin, a record is stored on a partition while the key is missing (default behavior).
By default, the key which helps to determines that which partition a Kafka Producer sends the record is the Record Key.
Basically, to scale a topic across many servers for producer writes, Kafka uses partitions. Also, in order to facilitate parallel consumers, Kafka uses partitions. Moreover, while it comes to failover, Kafka can replicate partitions to multiple Kafka Brokers.
Kafka Topic Log Partition’s Ordering and Cardinality
Well, we can say, only in a single partition, Kafka does maintain record order. As a partition is also an ordered, immutable record sequence. And, by using the partition as a structured commit log, Kafka continually appended to partitions.
In partitions, all records are assigned one sequential id number which we further call an offset. That offset further identifies each record location within the partition.
In addition, in order to scale beyond a size that will fit on a single server, Topic partitions permits to Kafka log. As topics can span many partitions hosted on many servers but Topic partitions must fit on servers which host it. Moreover, topic partitions in Apache Kafka are a unit of parallelism.
That says, at a time, a partition can only be worked on by one Kafka Consumer in a consumer group. Basically, a Consumer in Kafka can only run in their own process or their own thread. Although, Kafka spreads partitions across the remaining consumer in the same consumer group, if a consumer stops.
Kafka Topic Partition Replication
For the purpose of fault tolerance, Kafka can perform replication of partitions across a configurable number of Kafka servers. Basically, there is a leader server and zero or more follower servers in each partition. Also, for a partition, leaders are those who handle all read and write requests.
However, if the leader dies, the followers replicate leaders and take over. Additionally, for parallel consumer handling within a group, Kafka uses also uses partitions.
Replication: Kafka Partition Leaders, Followers, and ISRs.
However, by using ZooKeeper, Kafka chooses one broker’s partition’s replicas as the leader. Also, we can say, for the partition, the broker which has the partition leader handles all reads and writes of records.
Moreover, to the leader partition to followers (node/partition pair), Kafka replicates writes. On defining the term ISR, a follower which is in-sync is what we call an ISR (in-sync replica). Although, Kafka chooses a new ISR as the new leader if a partition leader fails.
Kafka Architecture: Kafka Replication – Replicating to Partition 0
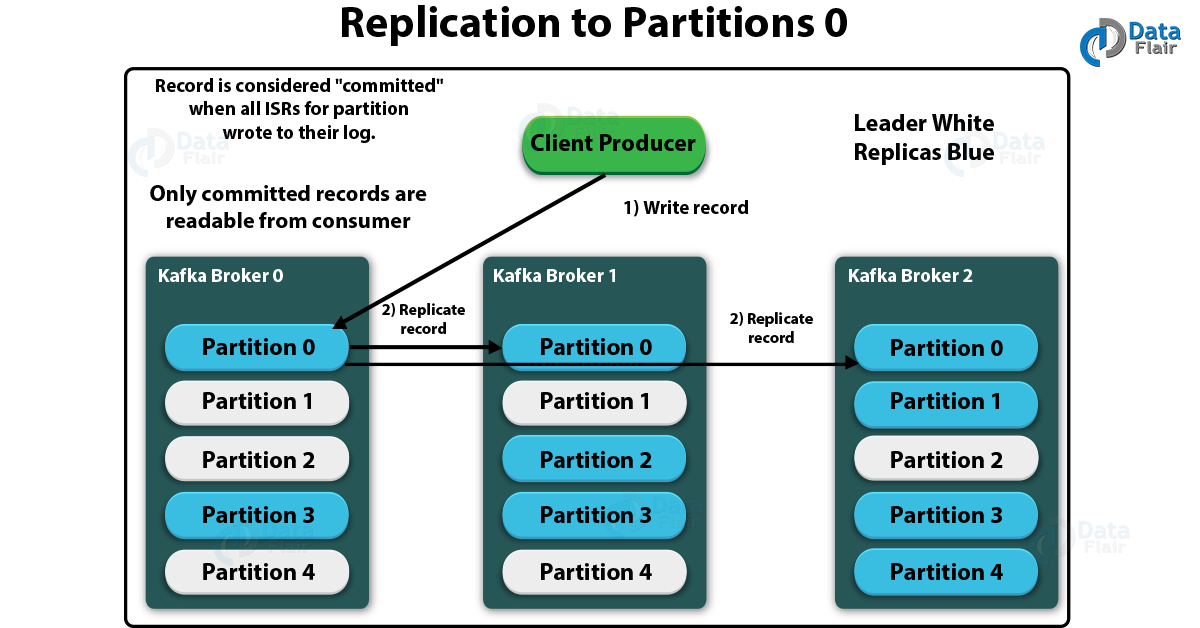
Kafka Architecture: Kafka Replication – Replicating to Partition 0
Although, when all ISRs for partition wrote to their log, the record is considered “committed”. However, we can only read the committed records from the consumer.
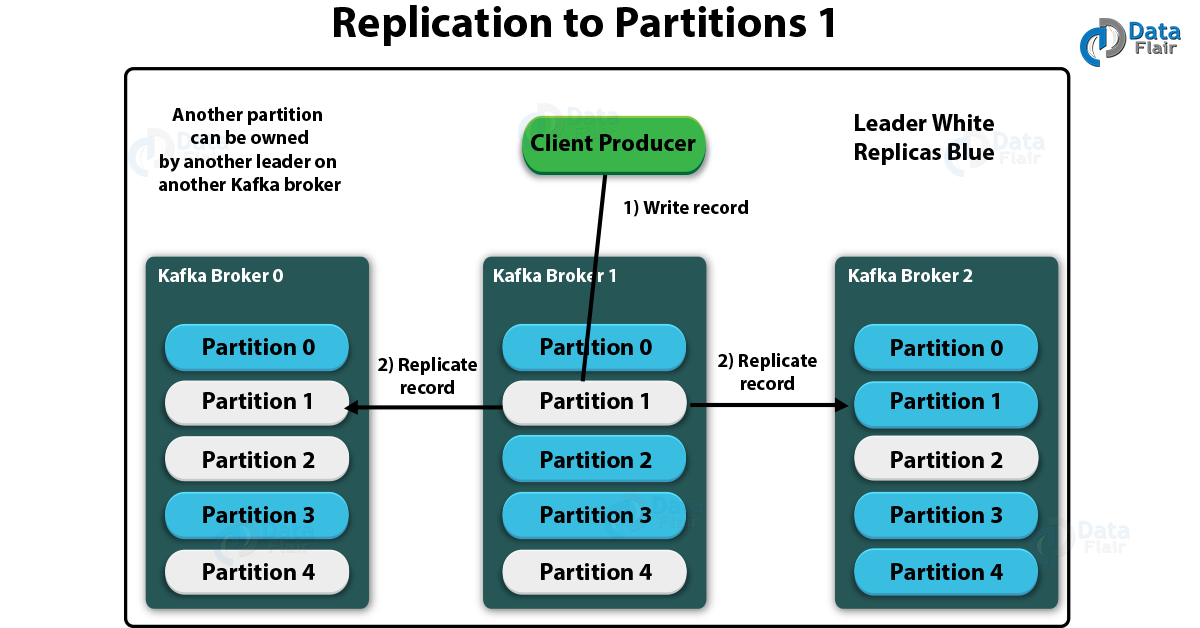
Kafka Topic – Replication to Partition 1
So, this was all about Kafka Topic. Hope you like our explanation.
Conclusion
Hence, we have seen the whole concept of Kafka Topic in detail. Moreover, we discussed Kafka Topic partitions, log partitions in Kafka Topic, and Kafka replication factor.
Also, we saw Kafka Architecture and creating a Topic in Kafka. Still, if any doubt occurs regarding Topics in Kafka, feel free to ask in the comment section. We are happy to help.
Your 15 seconds will encourage us to work even harder
Please share your happy experience on Google





Leader white, replicas blue. Is that true? Both pictures have blue color for all instances of parttion 0 and partition 3. In other partitions, I think, leader has blue color and replicas have white one
Buenas tardes, ante todo excelente artiulo y muchas gracias por el aporte a quienes queremos iniciarnos en este mundo de Kafka. Disculpen mi ignorancia. ¿Como puede llevar una tabla de BBDD relacional a un topic de Kafka?…Si siempre en las definiciones que se dan de topics y de mensajeria es de el Par (Clave, Valor) y una tabla contiene muchos mas columnas o campos?….. y ¿Como se asignan claves de multiples columnas?….
Muchas gracias.. y Saludos…
Nos alegra que te haya gustado el tutorial.
Sí, Kafka necesita datos en forma de clave-valor, aunque el valor puede ser un registro completo (que puede contener varias columnas de la tabla RDBMS).
Leader blue and replica white