Kafka Schema Registry | Learn Avro Schema
Kafka course with real-time projects Start Now!!
In this Kafka Schema Registry tutorial, we will learn what the Schema Registry is and why we should use it with Apache Kafka.
Also, we will see the concept of Avro schema evolution and set up and using Schema Registry with Kafka Avro Serializers. Moreover, we will learn to manage Avro Schemas with the REST interface of the Schema Registry.
So, let’s discuss Apache Kafka Schema Registry.
What is Kafka Schema Registry?
Basically, for both Kafka Producers and Kafka Consumers, Schema Registry in Kafka stores Avro Schemas.
- It offers a RESTful interface for managing Avro schemas.
- It permits for the storage of a history of schemas that are versioned.
- Moreover, it supports checking schema compatibility for Kafka.
- Using Avro Schema, we can configure compatibility settings to support the evolution of Kafka schemas.
Basically, the Kafka Avro serialization project offers serializers. With the help of Avro and Kafka Schema Registry, both the Kafka Producers and Kafka Consumers that use Kafka Avro serialization handles the schema management as well as the serialization of records.
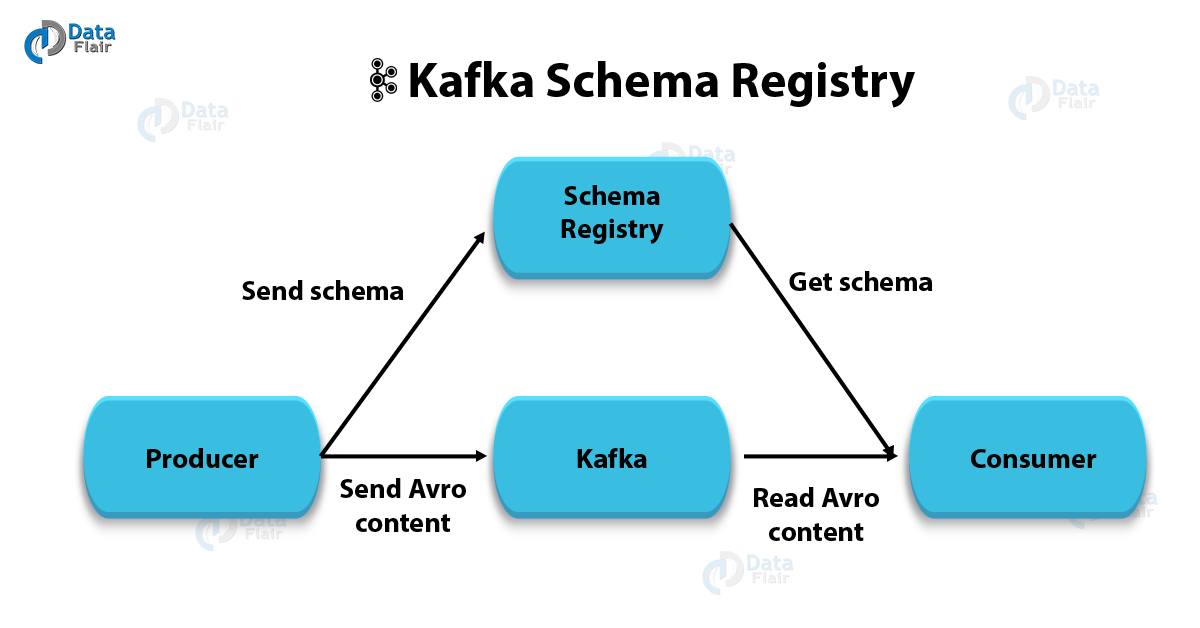
Introduction to Kafka Schema Registry
Moreover, producers don’t have to send schema, while using the Confluent Schema Registry in Kafka, — just the unique schema ID.
So, in order to look up the full schema from the Confluent Schema Registry if it’s not already cached, the consumer uses the schema ID. That implies don’t have to send the schema with each set of records, that results in saving the time as well.
However, also the Kafka producer creates a record/message, that is an Avro record. That record contains a schema ID and data. Also, the schema is registered if needed and then it serializes the data and schema ID, with the Kafka Avro Serializer.
Why Use Schema Registry in Kafka?
The consumer’s schema could differ from the producer’s. On defining a consumer schema, it is what the consumer is expecting the record/message to conform to.
As the check is performed, the payload transformation happens via Avro Schema Evolution, with the Schema Registry, if the two schemas don’t match but are compatible. In addition, Kafka records can have a key and a value and both can have a schema.
Kafka Schema Registry Operations
However, for keys and values of Kafka records, the Schema Registry can store schemas. Also, it lists schemas by subject. Moreover, it can list all versions of a subject (schema). Also, it can retrieve a schema by version or ID. And can get the latest version of a schema.
Some compatibility levels for the Apache Kafka Schema Registry are backward, forward, full, none. In addition, we can manage schemas via a REST API with the Schema registry.
Kafka Schema Compatibility Settings
Let’s understand all compatibility levels. Basically, Backward compatibility, refers to data written with an older schema that is readable with a newer schema. Moreover, Forward compatibility refers to data written with a newer schema is readable with old schemas.
Further, Full compatibility refers to a new version of a schema is backward- and forward-compatible. And, “none” status, means it disables schema validation and it is not recommended. Hence, Schema Registry just stores the schema and it will not be validated for compatibility if we set the level to “none”.
a. Schema Registry Configuration
Either globally or per subject.
The compatibility value will be:
A. None
It means don’t check for schema compatibility.
B. Forward
That says, check to make sure the last schema version is forward-compatible with new schemas.
C. Backward (default)
It means making sure the new schema is backward-compatible with the latest.
D. Full
“Full,” says to make sure the new schema is forward- and backward-compatible from the latest to newest and from the newest to latest.
Schema Evolution
Although, if using an older version of that schema, an Avro schema is changed after data has been written to store, then it is a possibility that Avro does a schema evolution when we try to read that data.
However, schema evolution happens only during deserialization at the consumer (read), from Kafka perspective.
And, if possible then the value or key is automatically modified during deserialization to conform to the consumer’s read schema if the consumer’s schema is different from the producer’s schema.
In simple words, it is an automatic transformation of Avro schemas between the consumer schema version and what schema the producer put into the Kafka log.
However, a data transformation is performed on the Kafka record’s key or value, when the consumer schema is not identical to the producer schema which used to serialize the Kafka record. Although, there is no need to do a transformation if the schemas match.
a. Allowed Modification During Schema Evolution
It is possible to add a field with a default to a schema. we can remove a field that had a default value. Also, we can change a field’s order attribute. Moreover, we can change a field’s default value to another value or add a default value to a field that did not have one.
However, it is possible to remove or add a field alias, but that may result in breaking some consumers that depend on the alias. Also, we can change a type to a union that contains original type. These above changes will result as our schema can use Avro’s schema evolution when reading with an old schema.
b. Rules of the Road for Modifying Schemas
We have to follow these guidelines if we want to make our schema evolvable. At first, we need to provide a default value for fields in our schema, because that allows us to delete the field later. Keep in mind that never change a field’s data type.
Also, we have to provide a default value for the field, when adding a new field to your schema. And, make sure don’t rename an existing field (use aliases instead).
For Example:
- Employee example Avro schema:
{"namespace": "com.dataflair.phonebook",
"type": "record",
"name": "Employee",
"doc" : "Represents an Employee at a company",
"fields": [
{"name": "firstName", "type": "string", "doc": "The persons given name"},
{"name": "nickName", "type": ["null", "string"], "default" : null},
{"name": "lastName", "type": "string"},
{"name": "age", "type": "int", "default": -1},
{"name": "emails", "default":[], "type":{"type": "array", "items": "string"}},
{"name": "phoneNumber", "type":
[ "null",
{ "type": "record", "name": "PhoneNumber",
"fields": [
{"name": "areaCode", "type": "string"},
{"name": "countryCode", "type": "string", "default" : ""},
{"name": "prefix", "type": "string"},
{"name": "number", "type": "string"}
]
}
]
},
{"name":"status", "default" :"SALARY", "type": { "type": "enum", "name": "Status",
"symbols" : ["RETIRED", "SALARY", "HOURLY", "PART_TIME"]}
}
]
}Avro Schema Evolution Scenario
Assume in version 1 of the schema, our Employee record did not have an age factor. But now we want to add an age field with a default value of -1. So, let’s suppose we have a consumer using version 1 with no age and a producer using version 2 of the schema with age
Now, by using version 2 of the Employee schema the Producer, creates a com.dataflair.Employee record sets age field to 42, then sends it to Kafka topic new-Employees. Afterwards, using version 1 the consumer consumes records from new-Employees of the Employee schema.
Hence, the age field gets removed during deserialization just because the consumer is using version 1 of the schema.
Furthermore, the same consumer modifies some records and then writes the record to a NoSQL store. As a result, the age field is missing from the record that it writes to the NoSQL store. Now, using version 2 of the schema another client, which has the age, reads the record from the NoSQL store.
Hence, because the Consumer wrote it with version 1, the age field is missing from the record, thus the client reads the record and the age is set to default value of -1.
So, the Schema Registry could reject the schema and the producer could never add it to the Kafka log, if we added the age and it was not optional, i.e. the age field did not have a default.
Using the Schema Registry REST API
Moreover, by using the following operations, the Schema Registry in Kafka allows us to manage schemas:
- Store schemas for keys and values of Kafka records
- List schemas by subject
- List all versions of a subject (schema)
- Retrieves a schema by version
- Retrieves a schema by ID
- Retrieve the latest version of a schema
- Perform compatibility checks
- Set compatibility level globally
However, all of this is available via a REST API with the Schema Registry in Kafka.
We can do the following, in order to post a new schema:
a. Posting a new schema
curl -X POST -H "Content-Type:
application/vnd.schemaregistry.v1+json" \
--data '{"schema": "{\"type\": …}’ \
http://localhost:8081/subjects/Employee/versionsb. To list all of the schemas
curl -X GET http://localhost:8081/subjects
We can basically perform all of the above operations via the REST interface for the Schema Registry, only if you have a good HTTP client. For example, Schema Registry a little better using the OkHttp client from Square (com.squareup.okhttp3:okhttp:3.7.0+) as follows:
Using REST endpoints to try out all of the Schema Registry options:
package com.dataflair.kafka.schema;
import okhttp3.*;
import java.io.IOException;
public class SchemaMain {
private final static MediaType SCHEMA_CONTENT =
MediaType.parse("application/vnd.schemaregistry.v1+json");
private final static String Employee_SCHEMA = "{\n" +
" \"schema\": \"" +
" {" +
" \\\"namespace\\\": \\\"com.dataflair.phonebook\\\"," +
" \\\"type\\\": \\\"record\\\"," +
" \\\"name\\\": \\\"Employee\\\"," +
" \\\"fields\\\": [" +
" {\\\"name\\\": \\\"fName\\\", \\\"type\\\": \\\"string\\\"}," +
" {\\\"name\\\": \\\"lName\\\", \\\"type\\\": \\\"string\\\"}," +
" {\\\"name\\\": \\\"age\\\", \\\"type\\\": \\\"int\\\"}," +
" {\\\"name\\\": \\\"phoneNumber\\\", \\\"type\\\": \\\"string\\\"}" +
" ]" +
" }\"" +
"}";
public static void main(String... args) throws IOException {
System.out.println(Employee_SCHEMA);
final OkHttpClient client = new OkHttpClient();
//POST A NEW SCHEMA
Request request = new Request.Builder()
.post(RequestBody.create(SCHEMA_CONTENT, Employee_SCHEMA))
.url("http://localhost:8081/subjects/Employee/versions")
.build();
String output = client.newCall(request).execute().body().string();
System.out.println(output);
//LIST ALL SCHEMAS
request = new Request.Builder()
.url("http://localhost:8081/subjects")
.build();
output = client.newCall(request).execute().body().string();
System.out.println(output);
//SHOW ALL VERSIONS OF Employee
request = new Request.Builder()
.url("http://localhost:8081/subjects/Employee/versions/")
.build();
output = client.newCall(request).execute().body().string();
System.out.println(output);
//SHOW VERSION 2 OF Employee
request = new Request.Builder()
.url("http://localhost:8081/subjects/Employee/versions/2")
.build();
output = client.newCall(request).execute().body().string();
System.out.println(output);
//SHOW THE SCHEMA WITH ID 3
request = new Request.Builder()
.url("http://localhost:8081/schemas/ids/3")
.build();
output = client.newCall(request).execute().body().string();
System.out.println(output);
//SHOW THE LATEST VERSION OF Employee 2
request = new Request.Builder()
.url("http://localhost:8081/subjects/Employee/versions/latest")
.build();
output = client.newCall(request).execute().body().string();
System.out.println(output);
//CHECK IF SCHEMA IS REGISTERED
request = new Request.Builder()
.post(RequestBody.create(SCHEMA_CONTENT, Employee_SCHEMA))
.url("http://localhost:8081/subjects/Employee")
.build();
output = client.newCall(request).execute().body().string();
System.out.println(output);
//TEST COMPATIBILITY
request = new Request.Builder()
.post(RequestBody.create(SCHEMA_CONTENT, Employee_SCHEMA))
.url("http://localhost:8081/compatibility/subjects/Employee/versions/latest")
.build();
output = client.newCall(request).execute().body().string();
System.out.println(output);
// TOP LEVEL CONFIG
request = new Request.Builder()
.url("http://localhost:8081/config")
.build();
output = client.newCall(request).execute().body().string();
System.out.println(output);
// SET TOP LEVEL CONFIG
// VALUES are none, backward, forward and full
request = new Request.Builder()
.put(RequestBody.create(SCHEMA_CONTENT, "{\"compatibility\": \"none\"}"))
.url("http://localhost:8081/config")
.build();
output = client.newCall(request).execute().body().string();
System.out.println(output);
// SET CONFIG FOR Employee
// VALUES are none, backward, forward and full
request = new Request.Builder()
.put(RequestBody.create(SCHEMA_CONTENT, "{\"compatibility\": \"backward\"}"))
.url("http://localhost:8081/config/Employee")
.build();
output = client.newCall(request).execute().body().string();
System.out.println(output);
}
}We suggest to run the example to try to force incompatible schemas to the Schema Registry, and also to note the behavior for the various compatibility settings.
c. Running Kafka Schema Registry:
$ cat ~/tools/confluent-3.2.1/etc/schema-registry/schema-registry.properties
listeners=http://0.0.0.0:8081
kafkastore.connection.url=localhost:2181
kafkastore.topic=_schemas
debug=false
~/tools/confluent-3.2.1/bin/schema-registry-start ~/tools/confluent-3.2.1/etc/schema-registry/schema-registry.properties
Writing Consumers and Producers
Here, we will require to start up the Schema Registry server pointing to our ZooKeeper cluster. Further, we may require importing the Kafka Avro Serializer and Avro JARs into our Gradle project. Afterwards, we will require configuring the producer to use Schema Registry and the KafkaAvroSerializer.
Also, we will require to configure it to use Schema Registry and to use the KafkaAvroDeserializer, to write the consumer.
Hence, this build file shows the Avro JAR files and such that we need.
- Gradle build file for Kafka Avro Serializer examples:
plugins {
id "com.commercehub.gradle.plugin.avro" version "0.9.0"
}
group 'dataflair'
version '1.0-SNAPSHOT'
apply plugin: 'java'
sourceCompatibility = 1.8
dependencies {
compile "org.apache.avro:avro:1.8.1"
compile 'com.squareup.okhttp3:okhttp:3.7.0'
testCompile 'junit:junit:4.11'
compile 'org.apache.kafka:kafka-clients:0.10.2.0'
compile 'io.confluent:kafka-avro-serializer:3.2.1'
}
repositories {
jcenter()
mavenCentral()
maven {
url "http://packages.confluent.io/maven/"
}
}
avro {
createSetters = false
fieldVisibility = "PRIVATE"
}Remember to include the Kafka Avro Serializer lib (io.confluent:kafka-avro-serializer:3.2.1) and the Avro lib (org.apache.avro:avro:1.8.1).
a. Writing a Producer
Further, let’s write the producer as follows.
- Producer that uses Kafka Avro Serialization and Kafka Registry:
package com.dataflair.kafka.schema;
import com.dataflair.phonebook.Employee;
import com.dataflair.phonebook.PhoneNumber;
import io.confluent.kafka.serializers.KafkaAvroSerializerConfig;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.LongSerializer;
import io.confluent.kafka.serializers.KafkaAvroSerializer;
import java.util.Properties;
import java.util.stream.IntStream;
public class AvroProducer {
private static Producer<Long, Employee> createProducer() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.CLIENT_ID_CONFIG, "AvroProducer");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class.getName());
// Configure the KafkaAvroSerializer.
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
KafkaAvroSerializer.class.getName());
// Schema Registry location.
props.put(KafkaAvroSerializerConfig.SCHEMA_REGISTRY_URL_CONFIG,
"http://localhost:8081");
return new KafkaProducer<>(props);
}
private final static String TOPIC = "new-Employees";
public static void main(String... args) {
Producer<Long, Employee> producer = createProducer();
Employee bob = Employee.newBuilder().setAge(35)
.setFirstName("Bob")
.setLastName("Jones")
.setPhoneNumber(
PhoneNumber.newBuilder()
.setAreaCode("301")
.setCountryCode("1")
.setPrefix("555")
.setNumber("1234")
.build())
.build();
IntStream.range(1, 100).forEach(index->{
producer.send(new ProducerRecord<>(TOPIC, 1L * index, bob));
});
producer.flush();
producer.close();
}
}Also, make sure we configure the Schema Registry and the KafkaAvroSerializer as part of the producer setup.
// Configure the KafkaAvroSerializer.
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
KafkaAvroSerializer.class.getName());
// Schema Registry location. props.put(KafkaAvroSerializerConfig.SCHEMA_REGISTRY_URL_CONFIG,
"http://localhost:8081");
Further, we use the producer as expected
b. Writing a Consumer
Afterward, we will write to the consumer.
- Kafka Consumer that uses Kafka Avro Serialization and Schema Registry:
package com.dataflair.kafka.schema;
import com.dataflair.phonebook.Employee;
import io.confluent.kafka.serializers.KafkaAvroDeserializer;
import io.confluent.kafka.serializers.KafkaAvroDeserializerConfig;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.LongDeserializer;
import java.util.Collections;
import java.util.Properties;
import java.util.stream.IntStream;
public class AvroConsumer {
private final static String BOOTSTRAP_SERVERS = "localhost:9092";
private final static String TOPIC = "new-Employee";
private static Consumer<Long, Employee> createConsumer() {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "KafkaExampleAvroConsumer");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
LongDeserializer.class.getName());
//Use Kafka Avro Deserializer.
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
KafkaAvroDeserializer.class.getName()); //<----------------------
//Use Specific Record or else you get Avro GenericRecord.
props.put(KafkaAvroDeserializerConfig.SPECIFIC_AVRO_READER_CONFIG, "true");
//Schema registry location.
props.put(KafkaAvroDeserializerConfig.SCHEMA_REGISTRY_URL_CONFIG,
"http://localhost:8081"); //<----- Run Schema Registry on 8081
return new KafkaConsumer<>(props);
}
public static void main(String... args) {
final Consumer<Long, Employee> consumer = createConsumer();
consumer.subscribe(Collections.singletonList(TOPIC));
IntStream.range(1, 100).forEach(index -> {
final ConsumerRecords<Long, Employee> records =
consumer.poll(100);
if (records.count() == 0) {
System.out.println("None found");
} else records.forEach(record -> {
Employee EmployeeRecord = record.value();
System.out.printf("%s %d %d %s \n", record.topic(),
record.partition(), record.offset(), EmployeeRecord);
});
});
}
}Make sure, we have to tell the consumer where to find the Registry, as same as the producer, and we have to configure the Kafka Avro Deserializer.
- Configuring Schema Registry for the consumer:
//Use Kafka Avro Deserializer.
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
KafkaAvroDeserializer.class.getName());
//Use Specific Record or else you get Avro GenericRecord.
props.put(KafkaAvroDeserializerConfig.SPECIFIC_AVRO_READER_CONFIG, "true");
//Schema registry location. props.put(KafkaAvroDeserializerConfig.SCHEMA_REGISTRY_URL_CONFIG,
"http://localhost:8081"); //<----- Run Schema Registry on 8081In addition, use the generated version of the Employee object. Because, if we did not, instead of our generated Employee object, then it would use the Avro GenericRecord, which is a SpecificRecord.
Moreover, we need to start up Kafka and ZooKeeper, to run the above example:
- Running ZooKeeper and Kafka:
kafka/bin/zookeeper-server-start.sh kafka/config/zookeeper.properties & kafka/bin/kafka-server-start.sh kafka/config/server.properties
So, this was all about Kafka Schema Registry. Hope you like our explanation.
Conclusion
As a result, we have seen that Kafka Schema Registry manages Avro Schemas for Kafka consumers and Kafka producers. Also, Avro offers schema migration, which is important for streaming and big data architectures.
Hence, we have learned the whole concept to Kafka Schema Registry. Here, we discussed the need of Schema registry in Kafka.
In addition, we have learned schema Registry Operations and Compatability Settings. At last, we saw Kafka Avro Schema and use of Schema Registry Rest API.
Finally, we moved on to Writing Kafka Consumers and Producers using Schema registry and Avro Serialization. Furthermore, if you have any query, feel free to ask through the comment section.
Your 15 seconds will encourage us to work even harder
Please share your happy experience on Google





I am getting a null pointer exception in producer code while avro tries to serialize the Employee Class? What can be the problem?