Apache Kafka + Spark Streaming Integration
Kafka course with real-time projects Start Now!!
In order to build real-time applications, Apache Kafka – Spark Streaming Integration are the best combinations. So, in this article, we will learn the whole concept of Spark Streaming Integration in Kafka in detail. Moreover, we will look at Spark Streaming-Kafka example.
After this, we will discuss a receiver-based approach and a direct approach to Kafka Spark Streaming Integration. Also, we will look advantages of direct approach to receiver-based approach in Kafka Spark Streaming Integration.
So, let’s start Kafka Spark Streaming Integration
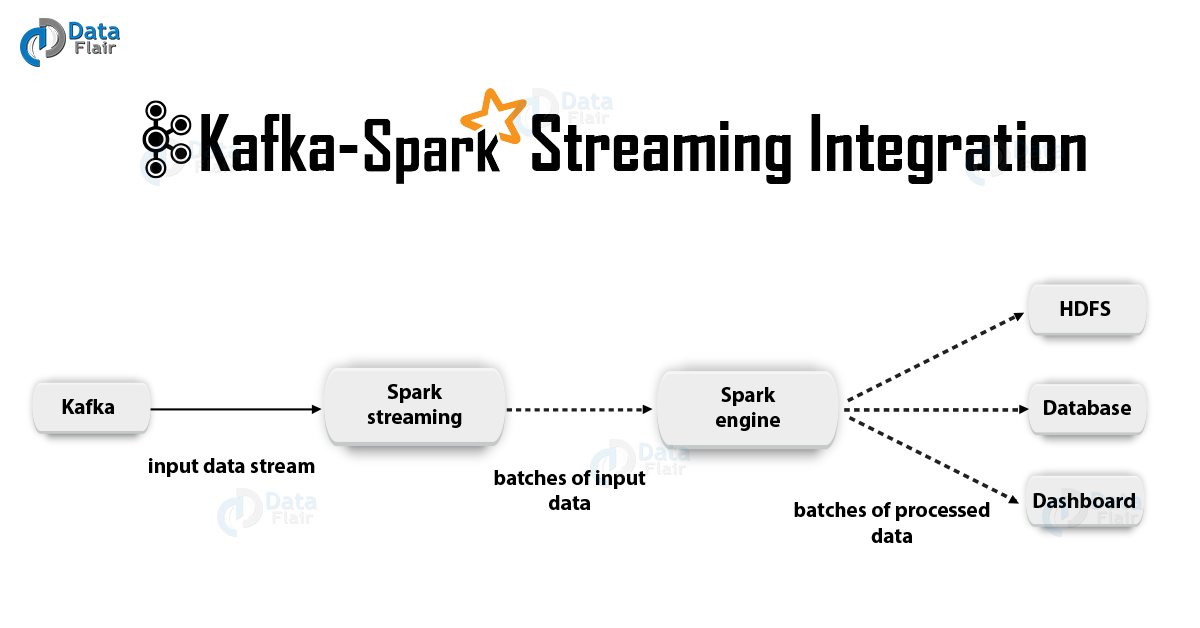
What is Kafka Spark Streaming Integration?
In Apache Kafka Spark Streaming Integration, there are two approaches to configure Spark Streaming to receive data from Kafka i.e. Kafka Spark Streaming Integration.
First is by using Receivers and Kafka’s high-level API, and a second, as well as a new approach, is without using Receivers. There are different programming models for both the approaches, such as performance characteristics and semantics guarantees.
What is Kafka-Spark Streaming Integration
Let’s study both approaches in detail.
a. Receiver-Based Approach
Here, we use a Receiver to receive the data. So, by using the Kafka high-level consumer API, we implement the Receiver. Further, the received data is stored in Spark executors. Then jobs launched by Kafka – Spark Streaming processes the data.
Although, it is a possibility that this approach can lose data under failures under default configuration. Hence, we have to additionally enable write-ahead logs in Kafka Spark Streaming, to ensure zero-data-loss.
That saves all the received Kafka data into write-ahead logs on a distributed file system synchronously. In this way, it is possible to recover all the data on failure.
Further, we will discuss how to use this Receiver-Based Approach in our Kafka Spark Streaming application.
i. Linking
Now, link your Kafka streaming application with the following artifact, for Scala/Java applications using SBT/Maven project definitions.
groupId = org.apache.spark artifactId = spark-streaming-kafka-0-8_2.11 version = 2.2.0
However, we will have to add this above library and its dependencies when deploying our application, for Python applications.
ii. Programming
Afterward, create an input DStream by importing KafkaUtils, in the streaming application code:
import org.apache.spark.streaming.kafka._
val kafkaStream = KafkaUtils.createStream(streamingContext,
[ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])Also, using variations of createStream, we can specify the key and value classes and their corresponding decoder classes.
iii. Deploying
As with any Spark applications, spark-submit is used to launch your application. However, the details are slightly different for Scala/Java applications and Python applications.
Moreover, using –packages spark-streaming-Kafka-0-8_2.11 and its dependencies can be directly added to spark-submit, for Python applications, which lack SBT/Maven project management.
./bin/spark-submit --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.2.0 ...
Also, we can also download the JAR of the Maven artifact spark-streaming-Kafka-0-8-assembly from the Maven repository. Then add it to spark-submit with –jars.
b. Direct Approach (No Receivers)
After Receiver-Based Approach, new receiver-less “direct” approach has been introduced. It ensures stronger end-to-end guarantees. This approach periodically queries Kafka for the latest offsets in each topic+partition, rather than using receivers to receive data.
Also, defines the offset ranges to process in each batch, accordingly. Moreover, to read the defined ranges of offsets from Kafka, it’s simple consumer API is used, especially when the jobs to process the data are launched. However, it is similar to read files from a file system.
Note: This feature was introduced in Spark 1.3 for the Scala and Java API, in Spark 1.4 for the Python API.
Now, let’s discuss how to use this approach in our streaming application.
To learn more about Consumer API follow the below link:
i. Linking
However, this approach is supported only in Scala/Java application. With the following artifact, link the SBT/Maven project.
groupId = org.apache.spark artifactId = spark-streaming-kafka-0-8_2.11 version = 2.2.0
ii. Programming
Further, import KafkaUtils and create an input DStream, in the streaming application code:
import org.apache.spark.streaming.kafka._
val directKafkaStream = KafkaUtils.createDirectStream[
[key class], [value class], [key decoder class], [value decoder class] ](
streamingContext, [map of Kafka parameters], [set of topics to consume])
We must specify either metadata.broker.list or bootstrap.servers, in the Kafka parameters. Hence, it will start consuming from the latest offset of each Kafka partition, by default. Although, it will start consuming from the smallest offset if you set configuration auto.offset.reset in Kafka parameters to smallest.
Moreover, using other variations of KafkaUtils.createDirectStream we can start consuming from an arbitrary offset. Afterward, do the following to access the Kafka offsets consumed in each batch.
// Hold a reference to the current offset ranges, so downstream can use it
var offsetRanges = Array.empty[OffsetRange]
directKafkaStream.transform { rdd =>
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}.map {
...
}.foreachRDD { rdd =>
for (o <- offsetRanges) {
println(s"${o.topic} ${o.partition} ${o.fromOffset} ${o.untilOffset}")
}
...
}If we want Zookeeper-based Kafka monitoring tools to show the progress of the streaming application, we can use this to update Zookeeper ourself.
iii. Deploying
Here, deploying process is similar to deploying process of Receiver-Based Approach.
Advantages of Direct Approach
There are following advantages of 2nd approach over 1st approach in Spark Streaming Integration with Kafka:

Advantages of Direct Approach in Spark Streaming Integration with Kafka
a. Simplified Parallelism
There is no requirement to create multiple input Kafka streams and union them. However, Kafka – Spark Streaming will create as many RDD partitions as there are Kafka partitions to consume, with the direct stream.
That will read data from Kafka in parallel. Hence, we can say, it is a one-to-one mapping between Kafka and RDD partitions, which is easier to understand and tune.
b. Efficiency
Achieving zero-data-loss in the first approach required the data to be stored in a write-ahead log, which further replicated the data. This is actually inefficient as the data effectively gets replicated twice – once by Kafka, and a second time by the write-ahead log.
The second approach eliminates the problem as there is no receiver, and hence no need for write-ahead logs. As long as we have sufficient Kafka retention, it is possible to recover messages from Kafka.
c. Exactly-Once Semantics
Basically, we used Kafka’s high-level API to store consumed offsets in Zookeeper in the first approach. However, to consume data from Kafka this is a traditional way. Even if it can ensure zero data loss, there is a small chance some records may get consumed twice under some failures.
It happens due to inconsistencies between data reliably received by Kafka – Spark Streaming and offsets tracked by Zookeeper. Therefore, we use a simple Kafka API that does not use Zookeeper, in this second approach.
Thus each record is received by Spark Streaming effectively exactly once despite failures.
Hence, make sure our output operation that saves the data to an external data store must be either idempotent or an atomic transaction that saves results and offsets. That helps to achieve exactly-once semantics for the output of our results.
Although, there is one disadvantage also, that it does not update offsets in Zookeeper, thus Zookeeper-based Kafka monitoring tools will not show progress. But still, we can access the offsets processed by this approach in each batch and update Zookeeper yourself.
So, this was all about Apache Kafka Spark Streaming Integration. Hope you like our explanation.
Conclusion
Hence, in this Kafka- Spark Streaming Integration, we have learned the whole concept of Spark Streaming Integration with Apache Kafka in detail. Also, we discussed two different approaches for Kafka Spark Streaming configuration and that are Receiving Approach and Direct Approach.
Moreover, we discussed the advantages of the Direct Approach. Furthermore, if any doubt occurs, feel free to ask in the comment section.
If you are Happy with DataFlair, do not forget to make us happy with your positive feedback on Google





Question is if I will run createstream job for one topic with 3 partitions with 6 executors and each executor having 2 cores. How many Receivers will be used on how many executors?
I though 3 receiver will run on 3 executors and will use one CPU each. Additional available CPU will be used to process task. Adition 3 executors available with 2 CPU each wont be used until we repartition rdd() to process the data.