Kafka Architecture and Its Fundamental Concepts
Kafka course with real-time projects Start Now!!
In our last Kafka Tutorial, we discussed Kafka Use Cases and Applications. Today, in this Kafka Tutorial, we will discuss Kafka Architecture. In this Kafka Architecture article, we will see API’s in Kafka.
Moreover, we will learn about Kafka Broker, Kafka Consumer, Zookeeper, and Kafka Producer. Also, we will see some fundamental concepts of Kafka.
So, let’s start Apache Kafka Architecture.
Kafka Architecture – Apache Kafka APIs
Apache Kafka Architecture has four core APIs, producer API, Consumer API, Streams API, and Connector API. Let’s discuss them one by one:
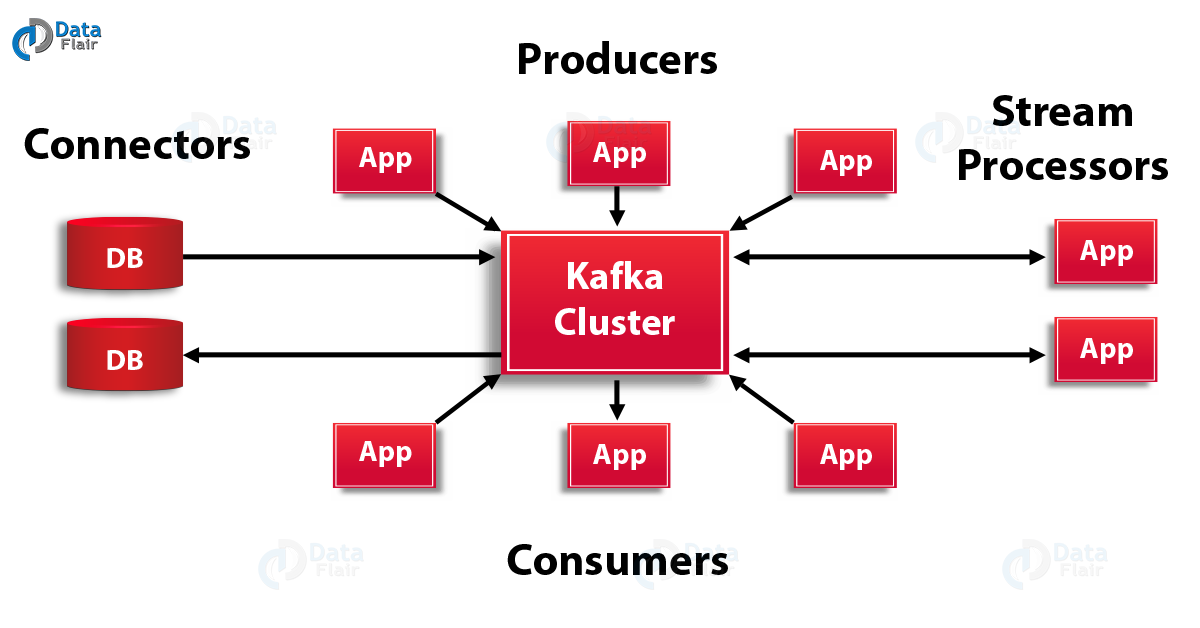
Kafka Architecture – Apache Kafka APIs
a. Producer API
In order to publish a stream of records to one or more Kafka topics, the Producer API allows an application.
b. Consumer API
This API permits an application to subscribe to one or more topics and also to process the stream of records produced to them.
c. Streams API
Moreover, to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams, the streams API permits an application.
d. Connector API
While it comes to building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems, we use the Connector API. For example, a connector to a relational database might capture every change to a table.
Apache Kafka Architecture – Cluster
The below diagram shows the cluster diagram of Apache Kafka:
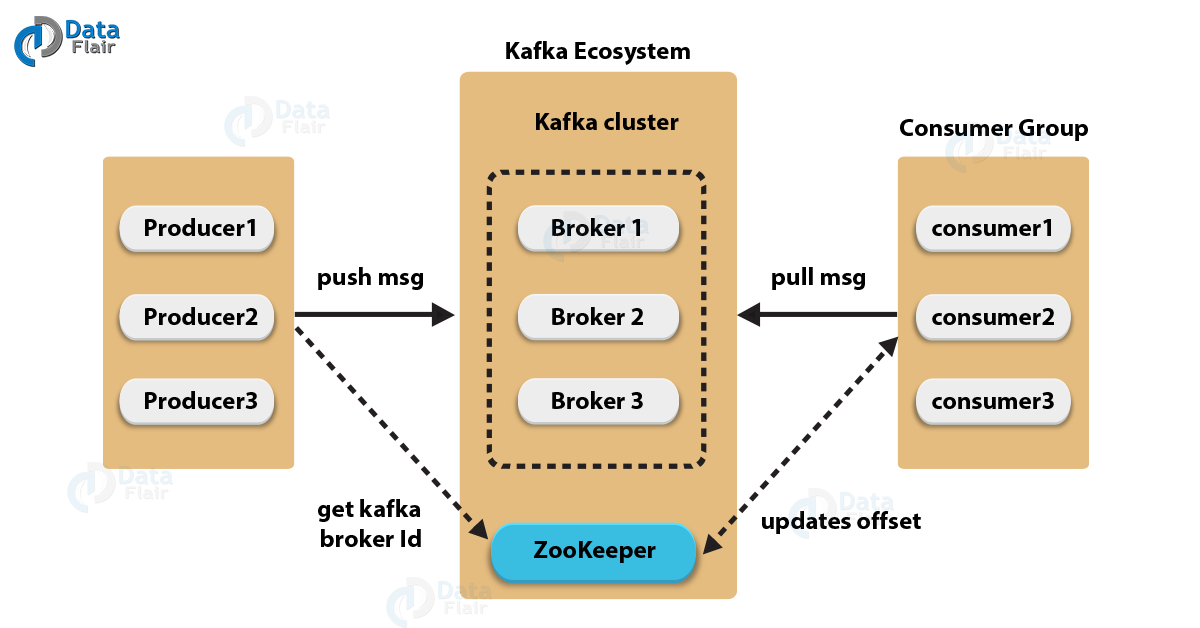
Kafka Architecture – Kafka Cluster
Let’s describe each component of Kafka Architecture shown in the above diagram:
a. Kafka Broker
Basically, to maintain load balance Kafka cluster typically consists of multiple brokers. However, these are stateless, hence for maintaining the cluster state they use ZooKeeper. Although, one Kafka Broker instance can handle hundreds of thousands of reads and writes per second.
Whereas, without performance impact, each broker can handle TB of messages. In addition, make sure ZooKeeper performs Kafka broker leader election.
b. Kafka – ZooKeeper
For the purpose of managing and coordinating, Kafka broker uses ZooKeeper. Also, uses it to notify producer and consumer about the presence of any new broker in the Kafka system or failure of the broker in the Kafka system.
As soon as Zookeeper send the notification regarding presence or failure of the broker then producer and consumer, take the decision and starts coordinating their task with some other broker.
c. Kafka Producers
Further, Producers in Kafka push data to brokers. Also, all the producers search it and automatically sends a message to that new broker, exactly when the new broker starts.
However, keep in mind that the Kafka producer sends messages as fast as the broker can handle, it doesn’t wait for acknowledgments from the broker.
d. Kafka Consumers
Basically, by using partition offset the Kafka Consumer maintains that how many messages have been consumed because Kafka brokers are stateless. Moreover, you can assure that the consumer has consumed all prior messages once the consumer acknowledges a particular message offset.
Also, in order to have a buffer of bytes ready to consume, the consumer issues an asynchronous pull request to the broker. Then simply by supplying an offset value, consumers can rewind or skip to any point in a partition. In addition, ZooKeeper notifies Consumer offset value.
Kafka Architecture – Fundamental Concepts
Here, we are listing some of the fundamental concepts of Kafka Architecture that you must know:
a. Kafka Topics
The topic is a logical channel to which producers publish message and from which the consumers receive messages.
- A topic defines the stream of a particular type/classification of data, in Kafka.
- Moreover, here messages are structured or organized. A particular type of messages is published on a particular topic.
- Basically, at first, a producer writes its messages to the topics. Then consumers read those messages from topics.
- In a Kafka cluster, a topic is identified by its name and must be unique.
- There can be any number of topics, there is no limitation.
- We can not change or update data, as soon as it gets published.
Below is the image which shows the relationship between Kafka Topics and Partitions:
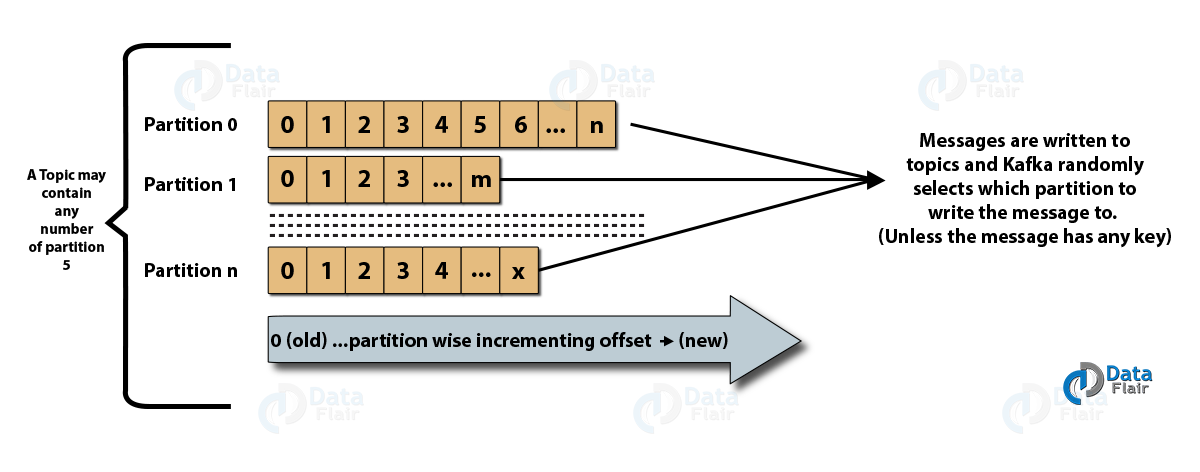
Kafka Architecture – Relation between Kafka Topics and Partitions
b. Partitions in Kafka
In a Kafka cluster, Topics are split into Partitions and also replicated across brokers.
- However, to which partition a published message will be written, there is no guarantee about that.
- Also, we can add a key to a message. Basically, we will get ensured that all these messages (with the same key) will end up in the same partition if a producer publishes a message with a key. Due to this feature, Kafka offers message sequencing guarantee. Though, unless a key is added to it, data is written to partitions randomly.
- Moreover, in one partition, messages are stored in the sequenced fashion.
- In a partition, each message is assigned an incremental id, also called offset.
- However, only within the partition, these offsets are meaningful. Moreover, in a topic, it does not have any value across partitions.
- There can be any number of Partitions, there is no limitation.
c. Topic Replication Factor in Kafka
While designing a Kafka system, it’s always a wise decision to factor in topic replication. As a result, its topics’ replicas from another broker can solve the crisis, if a broker goes down. For example, we have 3 brokers and 3 topics.
Broker1 has Topic 1 and Partition 0, its replica is in Broker2, so on and so forth. It has got a replication factor of 2; it means it will have one additional copy other than the primary one. Below is the image of Topic Replication Factor:
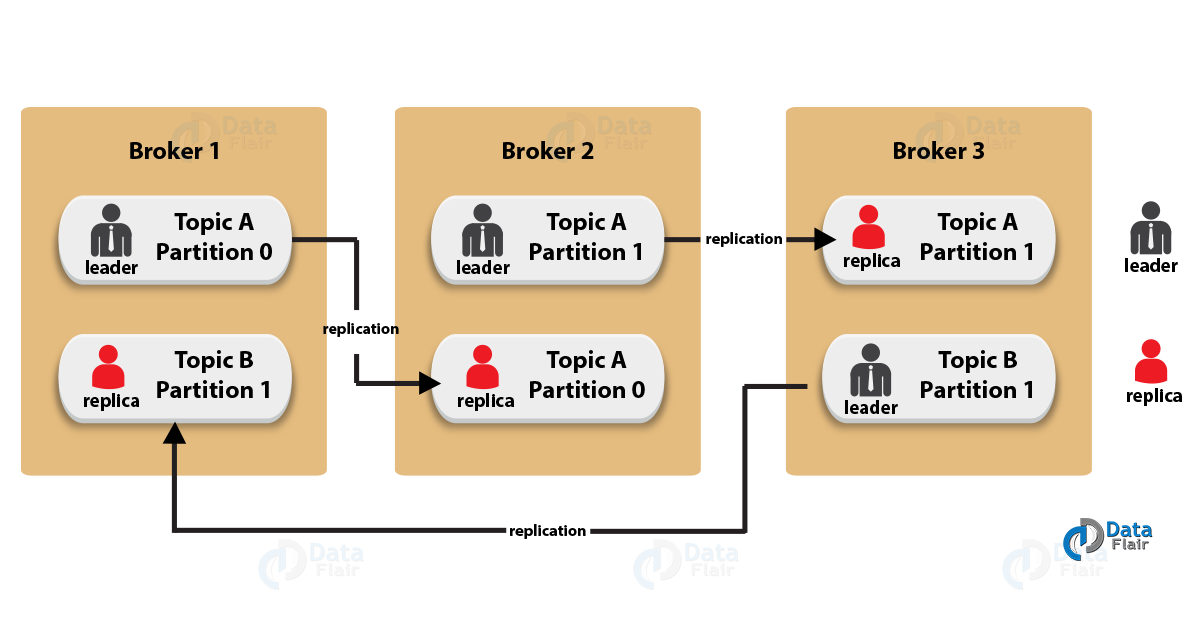
Kafka Architecture – Topic Replication Factor
Some key points –
- Replication takes place in the partition level only.
- For a given partition, only one broker can be a leader, at a time. Meanwhile, other brokers will have in-sync replica; what we call ISR.
- It is not possible to have the number of replication factor more than the number of available brokers.
d. Consumer Group
- It can have multiple consumer process/instance running.
- Basically, one consumer group will have one unique group-id.
- Moreover, exactly one consumer instance reads the data from one partition in one consumer group, at the time of reading.
- Since, there is more than one consumer group, in that case, one instance from each of these groups can read from one single partition.
- However, there will be some inactive consumers, if the number of consumers exceeds the number of partitions. Let’s understand it with an example if there are 8 consumers and 6 partitions in a single consumer group, that means there will be 2 inactive consumers.
So, this was all about Apache Kafka Architecture. Hope you like our explanation.
Summary
We have seen the concept of Kafka Architecture. Moreover, we discussed Kafka components and basic concept. Also, we saw a brief pf Kafka Broker, Consumer, Producer.
Along with this, we discussed Kafka Architecture API. Furthermore, for any query regarding Architecture of Kafka, feel free to ask in the comment section.
If you are Happy with DataFlair, do not forget to make us happy with your positive feedback on Google





English is off in many places. Complex sentences make a simple thing hard to understand. Otherwise, it is a pretty good read!