Apache Kafka Tutorial – Door to Gain Expertise in Kafka
Kafka course with real-time projects Start Now!!
Want to know everything about Apache Kafka? Well, you have come to the right place. Here in Apache Kafka tutorial, you will get an explanation of all the aspects that surround Apache Kafka. We will start from its basic concept and cover all the major topics related to Apache Kafka.
Before moving on to this Kafka tutorial, I just wanted you to know that Kafka is gaining huge popularity on Big Data spaces. A lot of companies are demanding Kafka professionals having strong skills and practical knowledge.
You can learn the theory part here and for implementing the concepts through real-time projects, preparing for interviews you must take Kafka Certification Course. Here industry veterans will guide you and help you to become the next Kafka Developer.
So, let’s continue the tutorial.
What is Kafka?
Apache Kafka is a fast, scalable, fault-tolerant messaging system which enables communication between producers and consumers using message-based topics. In simple words, it designs a platform for high-end new generation distributed applications.
Also, it allows a large number of permanent or ad-hoc consumers. One of the best features of Kafka is, it is highly available and resilient to node failures and supports automatic recovery.
This feature makes Apache Kafka ideal for communication and integration between components of large-scale data systems in real-world data systems.
Moreover, this technology takes place of conventional message brokers like JMS, AMQP with the ability to give higher throughput, reliability, and replication.
Before moving forward in Kafka Tutorial, let’s understand the Messaging System in Kafka.
Messaging Systems in Kafka
The main task of managing system is to transfer data from one application to another so that the applications can mainly work on data without worrying about sharing it.
Distributed messaging is based on the reliable message queuing process. Messages are queued non-synchronously between the messaging system and client applications.
There are two types of messaging patterns available:
- Point to point messaging system
- Publish-subscribe messaging system
You must check the concept of Apache Kafka Queuing
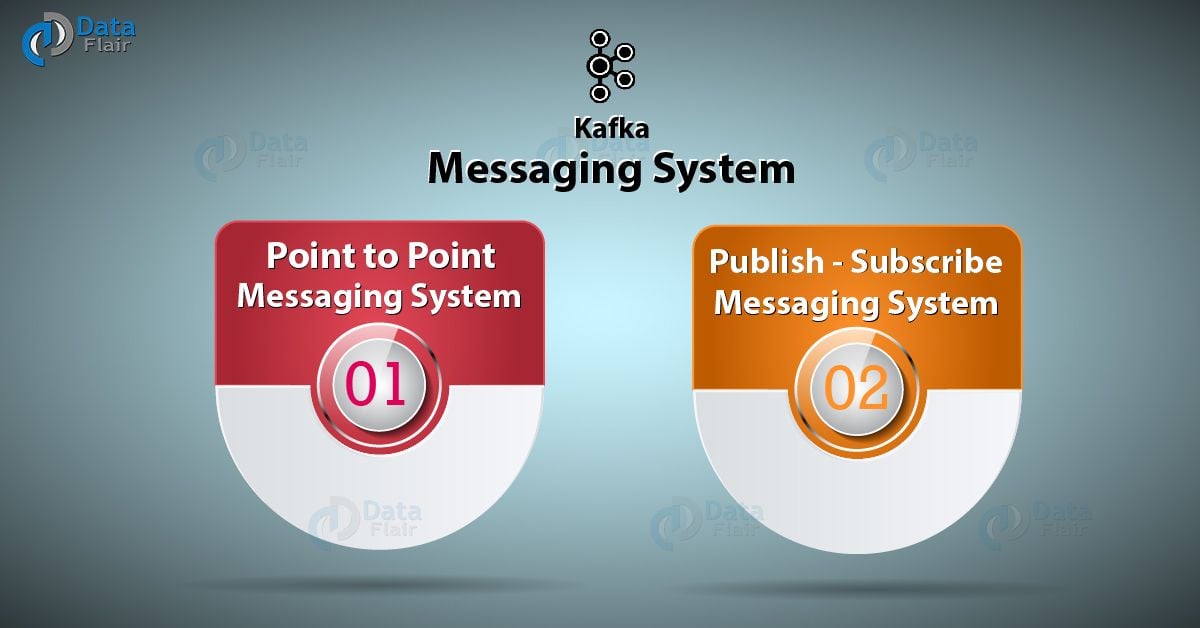
- Point to Point Messaging System
In this messaging system, messages continue to remain in a queue. More than one consumer can consume the messages in the queue but only one consumer can consume a particular message.
After the consumer reads the message in the queue, the message disappears from that queue.
- Publish-Subscribe Messaging System
In this messaging system, messages continue to remain in a Topic. Contrary to Point to point messaging system, consumers can take more than one topic and consume every message in that topic. Message producers are known as publishers and Kafka consumers are known as subscribers.
History of Apache Kafka
Previously, LinkedIn was facing the issue of low latency ingestion of huge amount of data from the website into a lambda architecture which could be able to process real-time events.
As a solution, Apache Kafka was developed in the year 2010, since none of the solutions was available to deal with this drawback, before.
However, there were technologies available for batch processing, but the deployment details of those technologies were shared with the downstream users. Hence, while it comes to Real-time Processing, those technologies were not enough suitable. Then, in the year 2011 Kafka was made public.
Need of Apache Kafka Cluster
As we all know, there is an enormous volume of data used in Big Data. For data, there are two main challenges. One is how to collect and manage a large volume of data and the other one is the analysis of the collected data. For dealing with such challenges, you need to have a messaging system.
There are many benefits of Apache Kafka that justifies the usage of Apache Kafka:
- Tracking web activities by storing/sending the events for real-time processes.
- Alerting and reporting the operational metrics.
- Transforming data into the standard format.
- Continuous processing of streaming data to the topics.
Explore the benefits and limitations of Apache Kafka in detail.
Therefore, this technology is giving a tough competition to some of the most popular applications like ActiveMQ, RabbitMQ, AWS, etc because of its wide use.
Audience for Kafka Tutorial
Professionals who are aspiring to make a career in Big Data Analytics using Apache Kafka messaging system should refer to this Kafka Tutorial. It will give you a complete understanding of Apache Kafka.
Prerequisites to Kafka
You must have a good understanding of Java, Scala, Distributed messaging system, and Linux environment, before proceeding with this Apache Kafka Tutorial.
Kafka Architecture
Below we are discussing four core APIs in this Apache Kafka tutorial:

1. Kafka Producer API
This Kafka Producer API permits an application to publish a stream of records to one or more Kafka topics.
2. Kafka Consumer API
The Consumer API permits an application to take one or more topics and process the continous flow of records produced to them.
3. Kafka Streams API
The Streams API permits an application to behave as a stream processor, consuming an input stream from one or more topics and generating an output stream to one or more output topics, efficiently modifying the input streams to output streams.
4. Kafka Connector API
The Connector API permits creating and running reusable producers or consumers that enables connection between Kafka topics and existing applications or data systems.
Kafka Components
Using the following components, Kafka achieves messaging:
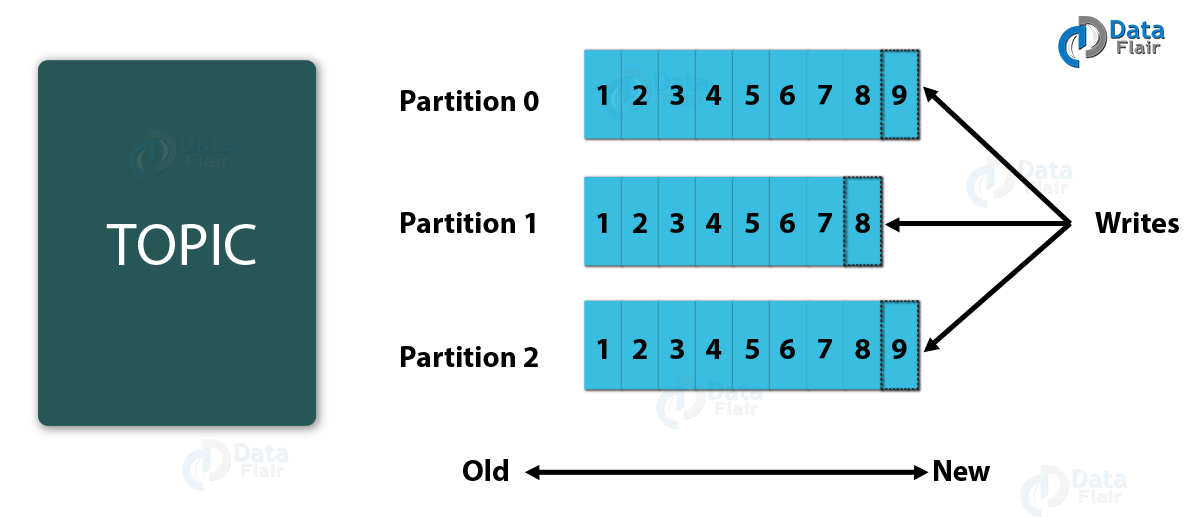
1. Kafka Topic
A bunch of messages that belong to a particular category is known as a Topic. Data stores in topics. In addition, we can replicate and partition Topics. Here, replicate refers to copies and partition refers to the division. Also, visualize them as logs wherein, Kafka stores messages. However, this ability to replicate and partitioning topics is one of the factors that enable Kafka’s fault tolerance and scalability.
2. Kafka Producer
The producers publish the messages on one or more Kafka topics.
3. Kafka Consumer
Consumers take one or more topics and consume messages that are already published through extracting data from the brokers.
4. Kafka Broker
These are basically systems which maintain the published data. A single broker can have zero or more partitions per topic.
5. Kafka Zookeeper
With the help of zookeeper, Kafka provides the brokers with metadata regarding the processes running in the system and grants health checking and broker leadership election.
Log Anatomy
We view log as the partitions. Basically, a data source writes messages to the log. One of the advantages is, at any time one or more consumers can read from the log they select. Here, the below diagram shows a log is being written by the data source and read by consumers at different offsets.
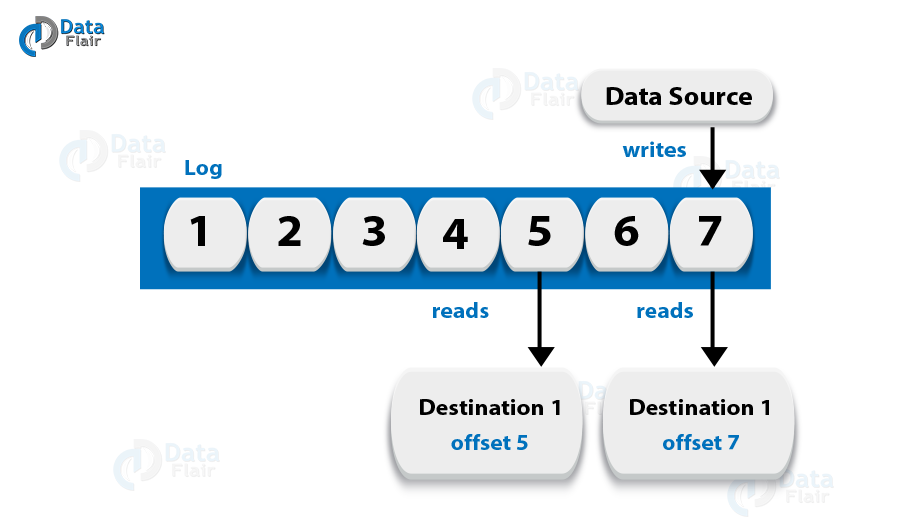
Data Log
By Kafka, messages are retained for a considerable amount of time. Also, consumers can read as per their convenience. However, if Kafka is configured to keep messages for 24 hours and a consumer is down for greater than 24 hours, the consumer will lose messages.
And, messages can be read from last known offset, if the downtime on part of the consumer is just 60 minutes. Kafka doesn’t keep a track on what consumers are reading from a topic.
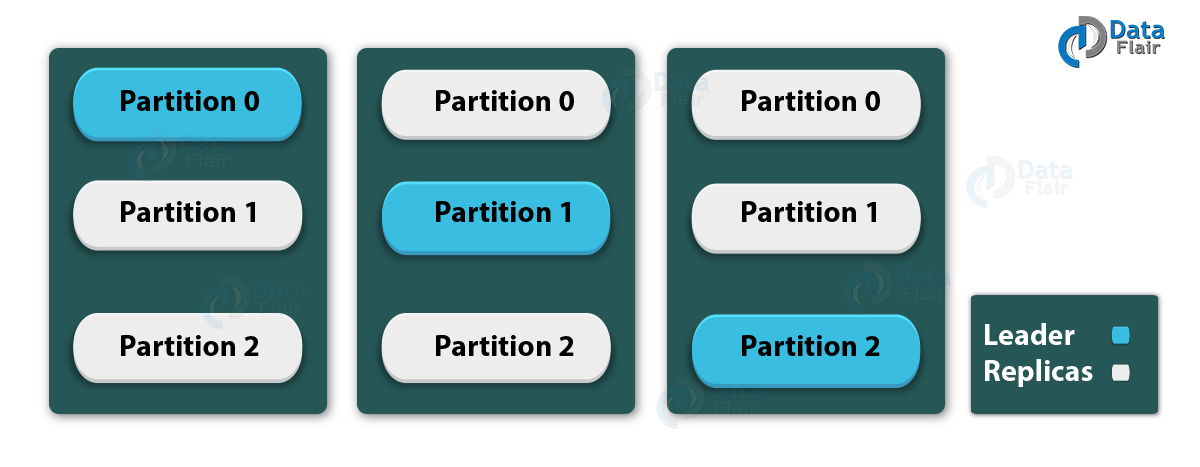
Partition in Kafka
There are few partitions in every Kafka broker. Each partition can be either a leader or a replica of a topic. In addition, along with updating of replicas with new data, Leader is responsible for all writes and reads to a topic. The replica takes over as the new leader if somehow the leader fails.
Importance of Java in Apache Kafka
Apache Kafka is written in pure Java and also Kafka’s native API is java. However, many other languages like C++, Python, .Net, Go, etc. also support Kafka.
Still, a platform where there is no need of using a third-party library is Java. Also, we can say, writing code in languages apart from Java will be a little overhead.
In addition, we can use Java language if we need the high processing rates that come standard on Kafka. Also, Java provides good community support for Kafka consumer clients. Hence, it is the right choice to implement Kafka in Java.
Kafka Use Cases
There are several use cases of Kafka that show why we actually use Apache Kafka.
1. Messaging
Kafka is the best substitute for traditional message brokers. We can say Kafka has better throughput, replication, fault-tolerance and built-in partitioning which makes it a better solution for large-scale message processing applications.
2. Metrics
Kafka is mostly utilized for operational monitoring data. It includes aggregating statistics from distributed applications to generate centralized feeds of operational data.
3. Event Sourcing
Kafka is a great backend for applications of event sourcing since it supports very large stored log data.
Comparisons in Kafka
Many applications offer the same functionality as Kafka like ActiveMQ, RabbitMQ, Apache Flume, Storm, and Spark. Then why should you go for Apache Kafka instead of others?
Let’s see the comparisons below:
1. Apache Kafka vs Apache Flume

i. Types of tool
Apache Kafka – It is a general-purpose tool for various producers and consumers.
Apache Flume – Whereas, it is a special-purpose tool for particular applications.
ii. Replication feature
Apache Kafka – Using ingest pipelines, it replicates the events.
Apache Flume – It does not replicate the events.
2. RabbitMQ vs Apache Kafka

One of the foremost Apache Kafka alternatives is RabbitMQ. So, let’s see how they differ from one another:
i. Features
Apache Kafka – It is distributed. The data is shared and replicated with assured durability and availability.
RabbitMQ – It offers comparatively less support for these features.
ii. Performance rate
Apache Kafka – Its performance rate is high, up to 100,000 messages/second.
RabbitMQ – Whereas, the performance rate of RabbitMQ is around 20,000 messages/second.
iii. Processing
Apache Kafka – It allows reliable log distributed processing. Also, there exist stream processing semantics built into the Kafka Streams.
RabbitMQ – The consumer is just FIFO based, reading from the HEAD and processing sequentially.
3. Traditional Queuing Systems vs Apache Kafka

i. Messages Retaining
Traditional Queuing Systems – Most queueing systems discard the messages after it has been processed from the end of the queue.
Apache Kafka – Here, messages persist even after being processed. They don’t get removed as consumers receive them.
ii. Logic-based processing
Traditional Queuing Systems – It does not allow to process logic based on similar messages or events.
Apache Kafka – It allows to process logic based on identical messages or events.
Summary
In this Kafka Tutorial, we have seen the basic concept of Apache Kafka, Kafka components, use cases, and Kafka architecture. At last, we saw the comparison between Kafka vs other messaging tools.
Any queries in the Kafka Tutorial? Enter in the comment section. We are waiting for your response.
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google





I am really sorry to say that sometime, your content in English is difficult to understand. Articles are very useful but you need to verify the content inside.
Thank You, Raakesh, We are glad for your Honest opinion. We assure that we will work on our content and also we will try to simplify our language to make it more understandable.
Nice content, perfectly understanding, including from the stranger of English language like me. Thank you!
Thank you for this study
thank you , great job !
Was looking for a good book on kafka and accidentally reached your site.
So now i need not buy the book.
Glad to hear that you are liking Kafka Tutorials at DataFlair. Do let us know if you are looking for any other technology, will be glad to help you.
Thank you so much for making Kafka Tutorials
Thank you so much for making Kafka Tutorials and Please add previous button and next button so easily go to the next page and previous page
like data flair very much
Apache Kafka’s core code is developed in scala but you mentioned java.
Merci beaucoup pour cette excellente explication sur Apache Kafka ! J’aimerais savoir comment Apache Kafka gère la tolérance aux pannes et assure la haute disponibilité des données ?
this tutorial helped me a lot to understand Kafka even better… thanks buddy.