Kafka Performance Tuning – Ways for Kafka Optimization
Kafka course with real-time projects Start Now!!
In our last Kafka Tutorial, we discussed Kafka load test. Today, we will discuss Kafka Performance Tuning.
In this article “Kafka Performance tuning”, we will describe the configuration we need to take care in setting up the cluster configuration. Also, we will discuss Tuning Kafka Producers, Tuning Kafka Consumers, and Tuning Kafka Brokers.
So, let’s start with Kafka Performance Tuning.
What is Kafka Performance Tuning?
There are few configuration parameters to be considered while we talk about Kafka Performance tuning. Hence, to improve performance, the most important configurations are the one, which controls the disk flush rate.
Also, we can divide these configurations on the component basis. So, let’s talk about Producer first. Hence, most important configurations which need to be taken care at Producer side are –
- Compression
- Batch size
- Sync or Async
And, at Consumer side the important configuration is –
- Fetch size
Although, it’s always confusing what batch size will be optimal when we think about batch size. We can say, large batch size may be great to have high throughput, it comes with latency issue. That implies latency and throughput is inversely proportional to each other.
It is possible to have low latency with high throughput where we have to choose a proper batch-size for that use queue-time or refresh-interval to find the required right balance.
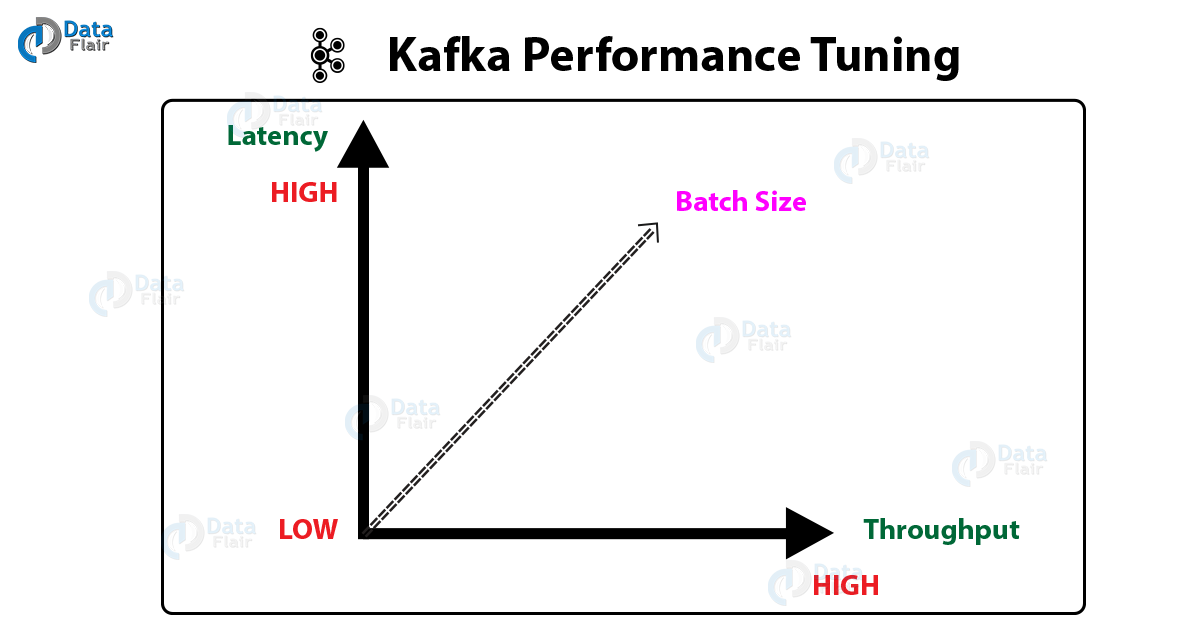
Kafka Performance Tuning Graph
Tuning Kafka for Optimal Performance
To be more specific, tuning involves two important metrics: Latency measures and throughput measures. Latency measures mean how long it takes to process one event, and similarly, how many events arrive within a specific amount of time, that means throughput measures.
So, most systems are optimized for either latency or throughput, while Apache Kafka balances both. Moreover, we can say, a well-tuned Kafka system has just enough brokers to handle topic throughput, given the latency required to process information as it is received.
a. Tuning Kafka Producers
As we know, Kafka uses an asynchronous publish/subscribe model. While our producer calls the send() command, the result returned is a future. That future offers methods to check the status of the information in the process.
Moreover, as the batch is ready, the producer sends it to the broker. Basically, the broker waits for an event, then, receives the result, and further responds that the transaction is complete.
For latency and throughput, two parameters are particularly important for Kafka performance Tuning:
i. Batch Size
Instead of the number of messages, batch.size measures batch size in total bytes. That means it controls how many bytes of data to collect, before sending messages to the Kafka broker. So, without exceeding available memory, set this as high as possible. Make sure the default value is 16384.
However, it might never get full, if we increase the size of our buffer. On the basis of other triggers, such as linger time in milliseconds, the Producer sends the information eventually. Although by setting the buffer batch size too high, we can impair memory usage, that does not impact latency.
Moreover, we are probably getting the best throughput possible, if our producer is sending all the time. Also, we might not be writing enough data to warrant the current allocation of resources, if the producer is often idle.
ii. Linger Time
In order to buffer data in asynchronous mode, linger.ms sets the maximum time. Let’s understand it with an example, a setting of 100 batches 100ms of messages to send at once. Here, the buffering adds message delivery latency but this improves throughput.
However, the producer does not wait, by default. Hence, it sends the buffer any time data is available.
Also, we can set linger.ms to 5 and send more messages in one batch, rather than sending immediately.
This would add up to 5 milliseconds of latency to records sent, but also reduce the number of requests sent, even if the load on the system does not warrant the delay.
So, for higher latency and higher throughput in our producer, increase linger.ms.
b. Tuning Kafka Brokers
As we know, Topics are divided into partitions. Further, each partition has a leader. Also, with multiple replicas, most partitions are written into leaders. However, if the leaders are not balanced properly, it might be possible that one might be overworked, compared to others.
So, on the basis of our system or how critical our data is, we want to be sure that we have sufficient replication sets to preserve our data. It is recommended that starting with one partition per physical storage disk and one consumer per partition.
c. Tuning Kafka Consumers
Basically, Kafka Consumers can create throughput issues. It is must that the number of consumers for a topic is equal to the number of partitions. Because, to handle all the consumers needed to keep up with the producers, we need enough partitions.
In the same consumer group, consumers split the partitions among them. Hence, adding more consumers to a group can enhance performance, also adding more consumer groups does not affect performance.
Moreover, the way we use the -replica.high.watermark.checkpoint.interval.ms property, can affect throughput. Also, we can mark the last point where we read information while reading from a partition.
In this way, we have a checkpoint from which to move forward without having to reread prior data, if we have to go back and locate the missing data.
So, we will never lose a message, if we set the checkpoint watermark for every event, but it significantly impacts performance. Also, we have a margin of safety with much less impact on throughput, if, instead, we set it to check the offset every hundred messages.
Production Server Configurations in Kafka Tuning
As per the availability of the cluster environment and machine configuration, here are some of the configurations parameter and their values which we can modify –
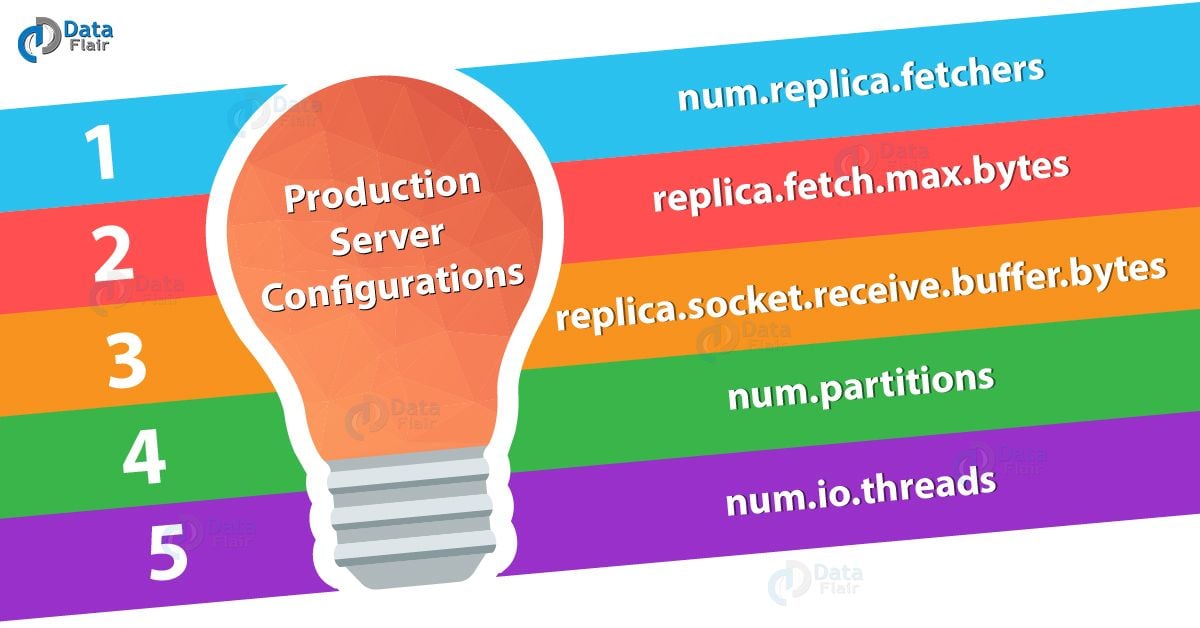
Kafka Performance Tuning- Production Server Configurations
a. num.replica.fetchers
This parameter defines the number of threads which will be replicating data from leader to the follower. As per availability of thread, we can modify the value of this parameter. It is important to have the number of replica fetchers to complete replication in parallel if we have threads available.
b. replica.fetch.max.bytes
This parameter is all about how much data we want to fetch from any partition in each fetch request. It’s good to increase value for this parameter so, that it helps to create replica fast in the followers.
c. replica.socket.receive.buffer.bytes
We can increase the size of a buffer if we have less thread available for creating the replica. Also, if replication thread is slow as compared to the incoming message rate, it will help to hold more data.
d. num.partitions
While having Kafka in live, we should take care of this configuration. We can have the level of parallelism and write data in parallel, that will automatically increase the throughput.
However, if the system configuration is not capable to handle then increasing the number of the partition can slow down our performance and throughput. Basically, if a system does not have sufficient threads or just have single disk then it does not make sense in creating lots of partition for better throughput.
So, we can say, the creation of more partition for a topic is directly dependent on available threads and disk.
e. num.io.threads
Basically, how much disk we have in our cluster, that decides setting value for I/O threads. Moreover, a server uses these threads for executing the request. Hence, a number of threads must depend on a number of the disk.
So, this was all about Kafka Performance Tuning. Hope you like our explanation.
Conclusion: Kafka Performance Tuning
Hence, we have seen the whole concept of Kafka Performance tuning. Moreover, we studied Tuning Kafka Producer, Tuning Kafka Broker, tuning Kafka Consumer.
In addition, we discussed 5 production server configuration. Still, if any doubt occurs, regarding Kafka Performance tuning, feel free to ask in the comment section.
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google





Hi Folk,
I am making a async call in Producer, at present i am getting perforamce of 4 secs, i need to reduce it to 1 sec, i have no idea what properties need to set to get high performance out of it.
If i am using fire and forget am not getting any way to trace failed messages in case of connection timeout.
Suggest me which will be better, as i have to use async as well as no loss of message, with 1 sec of performance.
w.r.t. ‘This would add up to 5 milliseconds of latency to records sent, but also reduce the number of requests sent’, I wonder if there was typo for the 5 milliseconds.
Since 5 ms < 100 ms, I think the number of requests sent shouldn't be lower compared to the 100 ms linger.ms
For consuming lakh records itself it takes 12 mins.how to make it faster
You are not covering the Kafka producer with spark streaming
Hi DataFlair Team,
First of all thank you for such a nice blog. It is very useful for beginners like me.
I have the below questions on Kafka Consumer:
1. Can we have a minimum batch size ?
2. Can we have a minimum wait time to be configured, in case the no. of messages never reach the minimum batch size configured?
Awaiting your response, thanks in advance