Apache Kafka Consumer | Kafka Consumer Group
Kafka course with real-time projects Start Now!!
In our last article, we discussed Kafka Producer. Today, we will discuss Kafka Consumer. Firstly, we will see what is Kafka Consumer and example of Kafka Consumer. Afterward, we will learn Kafka Consumer Group.
Moreover, we will see Consumer record API and configurations setting for Kafka Consumer.
After creating a Kafka Producer to send messages to Apache Kafka cluster. Now, we are creating a Kafka Consumer to consume messages from the Kafka cluster.
So, let’s discuss Kafka Consumer in detail.
What is Kafka Consumer?
An application that reads data from Kafka Topics is what we call a Consumer. Basically, Kafka Consumer subscribes to one or more topics in the Kafka cluster then further feeds on tokens or messages from the Kafka Topics.
In addition, using Heartbeat we can know the connectivity of Consumer to Kafka Cluster. However, let’s define Heartbeat. It is set up at Consumer to let Zookeeper or Broker Coordinator know if the Consumer is still connected to the Cluster.
So, Kafka Consumer is no longer connected to the Cluster, if the heartbeat is absent. In that case, the Broker Coordinator has to re-balance the load.
Moreover, Heartbeat is an overhead to the cluster. Also, by keeping the data throughput and overhead in consideration, we can configure the interval at which the heartbeat is at Consumer.
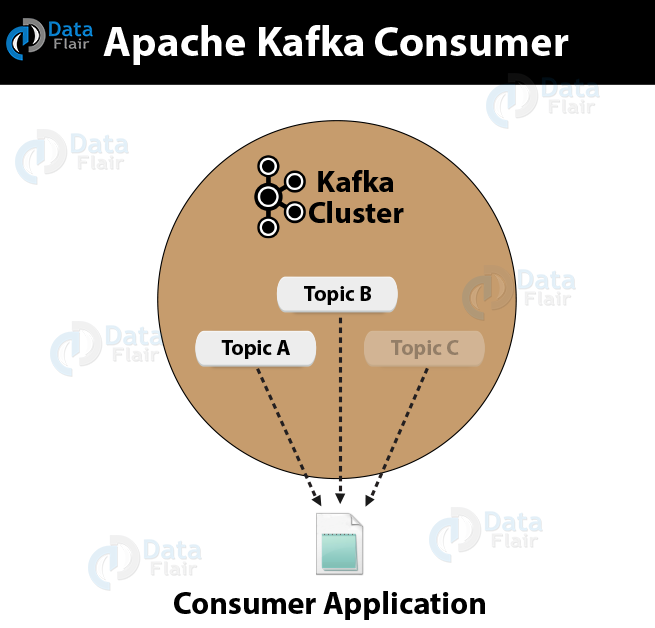
What is Apache Kafka Consumer
Moreover, we can group the consumers, and the consumers in the Consumer Group in Kafka could share the partitions of the Kafka Topics they subscribed to. T
o understand see, if there are N partitions in a Topic, N consumers in the Kafka Consumer Group and the group has subscribed to a Topic, each consumer would read data from a partition of the topic.
Hence, we can say, this is just a heads up that Consumers could be in groups.
To be specific, to connect to the Kafka cluster and consume the data streams, the Consumer API from Kafka helps.
Below is the picture showing Apache Kafka Consumer:
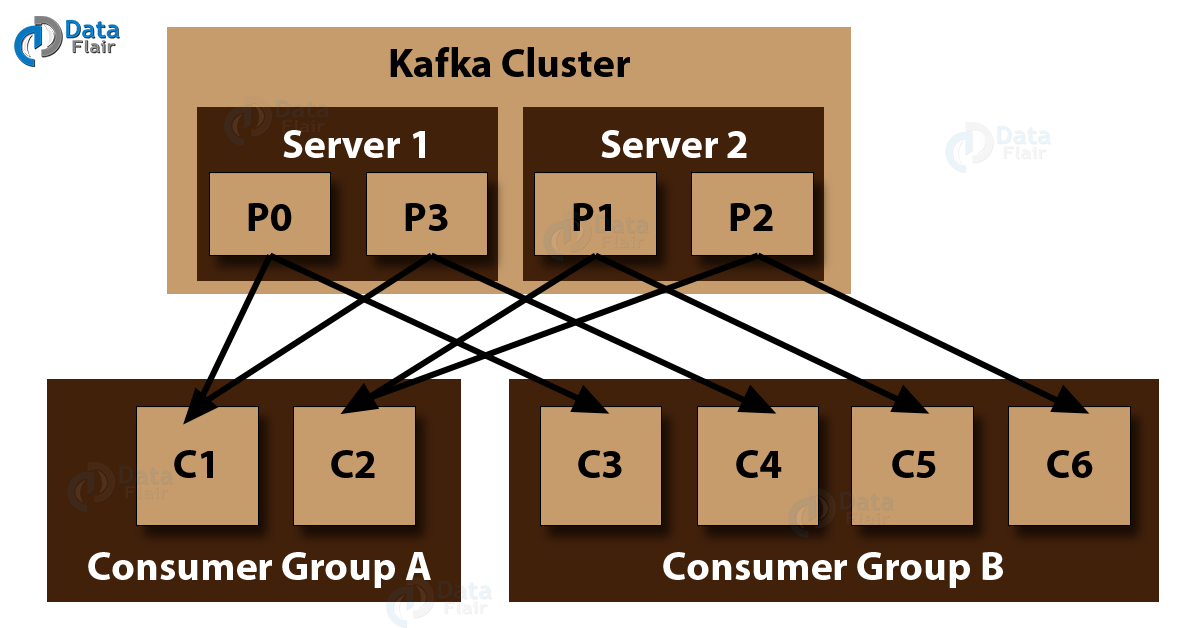
Working of Apache Kafka Consumer
To subscribe to one or more topics and process the stream of records produced to them in an application, we use this Kafka Consumer API. In order words, we use KafkaConsumer API to consume messages from the Kafka cluster. Moreover, below see the KafkaConsumer class constructor.
public KafkaConsumer(java.util.Map<java.lang.String,java.lang.Object> configs)
- configs
Return a map of consumer configs.
There are following significant methods of KafkaConsumer class:
1. public java.util.Set<TopicPar-tition> assignment()
To get the set of partitions currently assigned by the consumer.
2. public string subscription()
In order to subscribe to the given list of topics to get dynamically assigned partitions.
3. public void sub-scribe(java.util.List<java.lang.String> topics, ConsumerRe-balanceListener listener)
Further, to subscribe to the given list of topics to get dynamically assigned partitions.
4. public void unsubscribe()
Now, to unsubscribe the topics from the given list of partitions.
5. public void sub-scribe(java.util.List<java.lang.String> topics)
In order to subscribe to the given list of topics to get dynamically assigned partitions. If the given list of topics is empty, it is treated the same as unsubscribe().
6. public void subscribe(java.util.regex.Pattern pattern, ConsumerRebalanceLis-tener listener)
Here, argument pattern refers to the subscribing pattern in the format of regular expression and the listener argument gets notifications from the subscribing pattern.
7. public void as-sign(java.util.List<TopicParti-tion> partitions)
To manually assign a list of partitions to the customer.
8. poll()
Fetch data for the topics or partitions specified using one of the subscribe/assign APIs. This will return the error if the topics are not subscribed before the polling for data.
9. public void commitSync()
In order to commit offsets returned in the last poll() for all the subscribed list of topics and partitions. The same operation is applied to commitAsyn().
10. public void seek(TopicPartition partition, long offset)
To fetch the current offset value that consumer will use in the next poll() method.
11. public void resume()
In order to resume the paused partitions.
12. public void wakeup()
To wake Up the consumer.
ConsumerRecord API
Basically, to receive records from the Kafka cluster, we use the ConsumerRecord API. It includes a topic name, partition number, from which the record is being received also an offset that points to the record in a Kafka partition.
Moreover, to create a consumer record with specific topic name, partition count and <key, value> pairs, we use consumerRecord class. Its signature is:
public ConsumerRecord(string topic,int partition, long offset,K key, V value)
- Topic
The topic name for consumer record received from the Kafka cluster.
- Partition
Partition for the topic.
- Key
The key of the record, if no key exists null will be returned.
- Value
Record contents.
ConsumerRecords API
Basically, it is a container for ConsumerRecord. To keep the list of ConsumerRecord per partition for a particular topic we use this API. Its Constructor is:
public ConsumerRecords(java.util.Map<TopicPartition,java.util.List <Consumer-Record>K,V>>> records)
- TopicPartition
To return a map of partition for a particular topic.
- Records
To return the list of ConsumerRecord.
These are the following methods of a ConsumerRecords class:
1. public int count()
The number of records for all the topics.
2. public Set partitions()
The set of partitions with data in this recordset (if no data was returned then the set is empty).
3. public Iterator iterator()
Generally, iterator enables you to cycle through a collection, obtaining or removing elements.
4. public List records()
Basically, get the list of records for the given partition.
ConsumerRecord API vs ConsumerRecords API
a. ConsumerRecord API
ConsumerRecord API is a key/value pair to be received from Kafka. It contains a topic name and a partition number, from which the record is being received and an offset that points to the record in a Kafka partition.
b. ConsumerRecords API
Whereas, ConsumerRecords API is a container that holds the list ConsumerRecord per partition for a particular topic. Basically, there is one ConsumerRecord list for every topic partition returned by a Consumer.poll(long) operation.
Configuration Settings
Here, we are listing the configuration settings for the Consumer client API −
1. bootstrap.servers
It bootstraps list of brokers.
2. group.id
To assign an individual consumer to a group.
3. enable.auto.commit
Basically, it enables auto-commit for offsets if the value is true, otherwise not committed.
4. auto.commit.interval.ms
Basically, it returns how often updated consumed offsets are written to ZooKeeper.
5. session.timeout.ms
It indicates how many milliseconds Kafka will wait for the ZooKeeper to respond to a request (read or write) before giving up and continuing to consume messages.
SimpleConsumer Application
Make sure the producer application steps remain the same here. Here also start your ZooKeeper and Kafka broker. Further, create a SimpleConsumer application with the java class named SimpleCon-sumer.java. Then type the following code:
import java.util.Properties;
import java.util.Arrays;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class SimpleConsumer {
public static void main(String[] args) throws Exception {
if(args.length == 0){
System.out.println("Enter topic name");
return;
}
//Kafka consumer configuration settings
String topicName = args[0].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer
<String, String>(props);
//Kafka Consumer subscribes list of topics here.
consumer.subscribe(Arrays.asList(topicName))
//print the topic name
System.out.println("Subscribed to topic " + topicName);
int i = 0;
while (true) {
ConsumerRecords<String, String> records = con-sumer.poll(100);
for (ConsumerRecord<String, String> record : records)
// print the offset,key and value for the consumer records.
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
}
}
}a. Compilation
By using the following command we can compile the application.
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*” *.java
b. Execution
Moreover, using the following command we can execute the application.
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*”:. SimpleConsumer <topic-name>
c. Input
Further, open the producer CLI and send some messages to the topic. We can put the simple input as ‘Hello Consumer’.
d. Output
The output is
Subscribed to topic Hello-Kafka offset = 3, key = null, value = Hello Consumer
Kafka Consumer Group
Basically, Consumer group in Kafka is a multi-threaded or multi-machine consumption from Kafka topics.
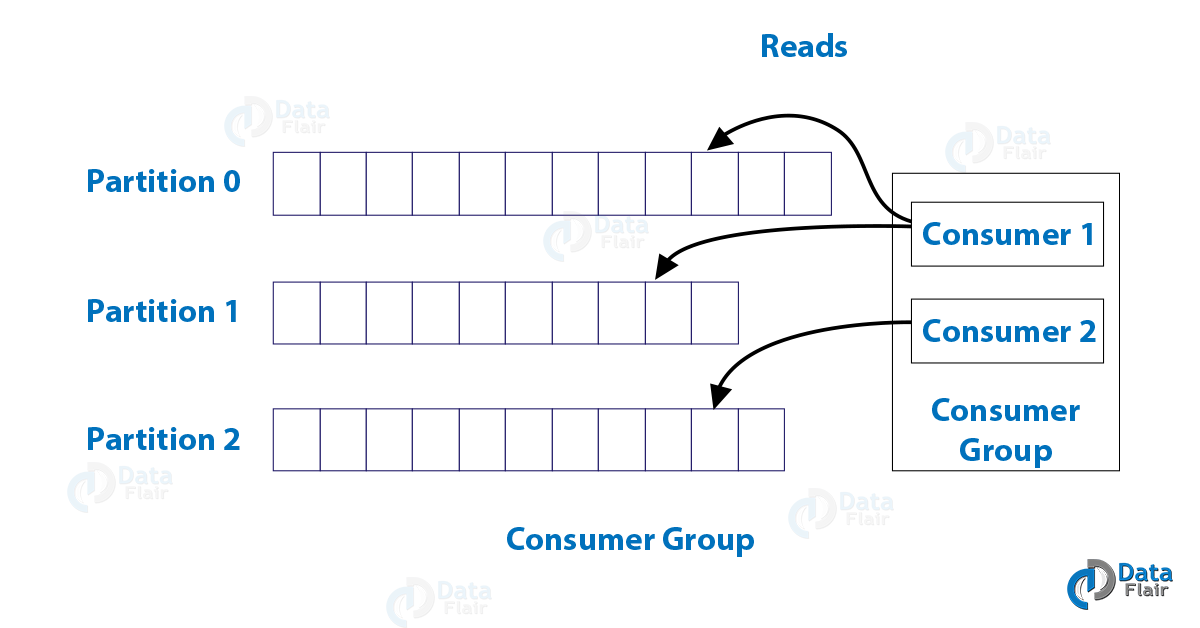
Kafka Consumer- Kafka Consumer Group
- By using the same group.id, Consumers can join a group.
- The maximum parallelism of a group is that the number of consumers in the group ← numbers of partitions.
- Moreover, Kafka assigns the partitions of a topic to the consumer in a group. Hence, each partition is consumed by exactly one consumer in the group.
- Also, Kafka guarantees that a message is only ever read by a single consumer in the group.
- Consumers can see the message in the order they were stored in the log.
a. Re-balancing of a Consumer
Basically, an addition of more processes/threads will cause Kafka to re-balance. Basically, if somehow any consumer or broker fails to send heartbeat to ZooKeeper, then it can be re-configured via the Kafka cluster. Also, Kafka will assign available partitions to the available threads, possibly moving a partition to another process, during this re-balance.
import java.util.Properties;
import java.util.Arrays;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class ConsumerGroup {
public static void main(String[] args) throws Exception {
if(args.length < 2){
System.out.println("Usage: consumer <topic> <groupname>");
return;
}
String topic = args[0].toString();
String group = args[1].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", group);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(topic));
System.out.println("Subscribed to topic " + topic);
int i = 0;
while (true) {
ConsumerRecords<String, String> records = con-sumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
}
}
}
ii. Compilation
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*" ConsumerGroup.java
iii. Execution
>>java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*":.
ConsumerGroup <topic-name> my-group
>>java -cp "/home/bala/Workspace/kafka/kafka_2.11-0.9.0.0/libs/*":.
ConsumerGroup <topic-name> my-groupHence, we can see the sample group we have created the name, my-group with two consumers.
b. Input
Now, after opening producer CLI, send some messages like-
Test consumer group 01 Test consumer group 02
c. The output of the First Process
Subscribed to topic Hello-kafka offset = 3, key = null, value = Test consumer group 01
d. Further, the output of the Second Process
Subscribed to topic Hello-kafka offset = 3, key = null, value = Test consumer group 02
So, this was all about Apache Kafka Consumer and Consumer group in Kafka with examples. Hope you like our explanation.
Conclusion: Kafka Consumer
Hence, we have seen Kafka Consumer and ConsumerGroup by using the Java client demo in detail. Also, by this, we have an idea about how to send and receive messages using a Java client.
Moreover, we discussed Kafka Consumer record API and Consumer Records API and also the comparison of both. In addition, we have learned configuration setting for Kafka Consumer client API. However, if any doubt occurs, feel free to ask in the comment section.
We work very hard to provide you quality material
Could you take 15 seconds and share your happy experience on Google




