HTML Entities – Character Entities and Diacritical Marks
Full Stack Web Development Courses with Real-time projects Start Now!!
An HTML entity is a string that is used to display reserved and invisible characters, which would otherwise be treated as HTML code. HTML entities begin with an ampersand(&) and end with a semicolon(;). They are written as-
&entityName; or &#entityNumber;
HTML reserves some characters, and it is possible that the browser may misinterpret them as mark-up elements. There are also some characters that are not present on a standard keyboard but are desired on a web-page. For such situations, HTML entities prove to be highly beneficial. It is easier to remember an entity name than type from a standard keyboard.
For example, The less than sign,<, is written as < or <.
Knowledge and application of HTML entities is significant so as to improve on a good display of Web page contents to the user and browser without an erroneous interpretation. It is widely used in web development when working with user input data to avoid cross-site scripting (XSS). Furthermore, with the use of HTML entities, special characters and symbols are made possible in web design which adds to the readiness of the page and thus making the web page more user-friendly.

When to use HTML Entities?
- When the editor does not support unicode, HTML entities are useful.
- We can use the HTML entities for displaying characters such as ‘<’ or ‘>’ which may otherwise be interpreted as code while displaying.
- For displaying specific characters such as ‘<’ or ‘>’, we use HTML entities. These characters may otherwise be interpreted as code while displaying on the browser.
Let us suppose we want to write and display <p id= “character”> on our webpage. We can write the characters ‘<’ and ‘>’ using the entity name or the numerical character reference.
<!DOCTYPE html>
<html>
<head>
<title>HTML Entities</title>
</head>
<body>
<p id = "character">
</body>
</html>
Output-
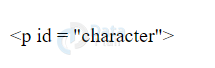
HTML Non-Breaking Space
We can use the   entity name to represent non-breaking space in HTML. This is useful when breaking text into new lines is not desirable and text-display should be compact. This also prevents the browser from truncating spaces.
The browser truncates 9 out of 10 spaces that have been given by the developer. In such a case,   comes handy.
<!DOCTYPE html> <html> <head> <title>non-breaking space</title> </head> <body> 10 PM<br> 10 km/hr </body> </html>
Output-

HTML Reserved Characters
| Character | Entity | Description |
| & | & | This marks the start of an entity or character reference. |
| < | < | The beginning of tag |
| > | > | The ending of a tag |
| “ | " | This marks the end of an attribute value. |
HTML Character Entities
| Result | Description | Entity Name | Entity Number |
| non-breaking space | | ||
| < | less than | < | < |
| > | greater than | > | > |
| & | ampersand | & | & |
| “ | double quotation mark | " | “ |
| ‘ | single quotation mark (apostrophe) | ' | ‘ |
| ¢ | cent | ¢ | ¢ |
| £ | pound | £ | £ |
| ¥ | yen | ¥ | ¥ |
| € | euro | € | € |
| © | copyright | © | © |
| ® | registered trademark | ® | ® |
Note- Please note that entity names are case-sensitive.
HTML Diacritical Marks
Diacritical marks are typical symbols that lay stress on the pronunciation of a particular word. Grave( ̀) and acute( ́) are the commonly used diacritical marks. We can use diacritical marks with alphanumeric characters to produce new characters unavailable in the character set.
Some examples-
| Mark | Character | Code | Result |
| ̀ | a | à | à |
| ́ | a | á | á |
| ̂ | a | â | â |
| ̃ | a | ã | ã |
| ̀ | O | Ò | Ò |
| ́ | O | Ó | Ó |
| ̂ | O | Ô | Ô |
| ̃ | O | Õ | Õ |
Note- It is a good practice to use entity numbers than names as some browsers may not support the names.
Summary
HTML consists of some reserved characters that have a unique meaning when used in HTML. In this article, we’ve discussed some of these reserved characters such as &, <, >, &apos, ". These HTML entities could be an entity name or an entity number. We’ve also tabulated some of the commonly used entities in HTML.
If you are Happy with DataFlair, do not forget to make us happy with your positive feedback on Google




