Hadoop MapReduce Tutorial – A Complete Guide to Mapreduce
1. Hadoop MapReduce Tutorial
This Hadoop MapReduce tutorial describes all the concepts of Hadoop MapReduce in great details. In this tutorial, we will understand what is MapReduce and how it works, what is Mapper, Reducer, shuffling, and sorting, etc. This Hadoop MapReduce Tutorial also covers internals of MapReduce, DataFlow, architecture, and Data locality as well. So lets get started with the Hadoop MapReduce Tutorial.
Hdaoop MapReduce Tutorial
2. What is MapReduce?
MapReduce is the processing layer of Hadoop. MapReduce programming model is designed for processing large volumes of data in parallel by dividing the work into a set of independent tasks. You need to put business logic in the way MapReduce works and rest things will be taken care by the framework. Work (complete job) which is submitted by the user to master is divided into small works (tasks) and assigned to slaves.
MapReduce programs are written in a particular style influenced by functional programming constructs, specifical idioms for processing lists of data. Here in MapReduce, we get inputs from a list and it converts it into output which is again a list. It is the heart of Hadoop. Hadoop is so much powerful and efficient due to MapRreduce as here parallel processing is done.
This is what MapReduce is in Big Data. In the next step of Mapreduce Tutorial we have MapReduce Process, MapReduce dataflow how MapReduce divides the work into sub-work, why MapReduce is one of the best paradigms to process data:
learn Big data Technologies and Hadoop concepts.
i. High-level Understanding of Hadoop MapReduce Tutorial
Now in this Hadoop Mapreduce Tutorial let’s understand the MapReduce basics, at a high level how MapReduce looks like, what, why and how MapReduce works?
Map-Reduce divides the work into small parts, each of which can be done in parallel on the cluster of servers. A problem is divided into a large number of smaller problems each of which is processed to give individual outputs. These individual outputs are further processed to give final output.
Hadoop Map-Reduce is scalable and can also be used across many computers. Many small machines can be used to process jobs that could not be processed by a large machine. Next in the MapReduce tutorial we will see some important MapReduce Traminologies.
ii. Apache MapReduce Terminologies
Let’s now understand different terminologies and concepts of MapReduce, what is Map and Reduce, what is a job, task, task attempt, etc.
Map-Reduce is the data processing component of Hadoop. Map-Reduce programs transform lists of input data elements into lists of output data elements. A Map-Reduce program will do this twice, using two different list processing idioms-
- Map
- Reduce
In between Map and Reduce, there is small phase called Shuffle and Sort in MapReduce.
Let’s understand basic terminologies used in Map Reduce.
- What is a MapReduce Job?
MapReduce Job or a A “full program” is an execution of a Mapper and Reducer across a data set. It is an execution of 2 processing layers i.e mapper and reducer. A MapReduce job is a work that the client wants to be performed. It consists of the input data, the MapReduce Program, and configuration info. So client needs to submit input data, he needs to write Map Reduce program and set the configuration info (These were provided during Hadoop setup in the configuration file and also we specify some configurations in our program itself which will be specific to our map reduce job).
- What is Task in Map Reduce?
A task in MapReduce is an execution of a Mapper or a Reducer on a slice of data. It is also called Task-In-Progress (TIP). It means processing of data is in progress either on mapper or reducer.
- What is Task Attempt?
Task Attempt is a particular instance of an attempt to execute a task on a node. There is a possibility that anytime any machine can go down. For example, while processing data if any node goes down, framework reschedules the task to some other node. This rescheduling of the task cannot be infinite. There is an upper limit for that as well. The default value of task attempt is 4. If a task (Mapper or reducer) fails 4 times, then the job is considered as a failed job. For high priority job or huge job, the value of this task attempt can also be increased.
Install Hadoop and play with MapReduce. Next topic in the Hadoop MapReduce tutorial is the Map Abstraction in MapReduce.
iii. Map Abstraction
Let us understand the abstract form of Map in MapReduce, the first phase of MapReduce paradigm, what is a map/mapper, what is the input to the mapper, how it processes the data, what is output from the mapper?
The map takes key/value pair as input. Whether data is in structured or unstructured format, framework converts the incoming data into key and value.
- Key is a reference to the input value.
- Value is the data set on which to operate.
Map Processing:
- A function defined by user – user can write custom business logic according to his need to process the data.
- Applies to every value in value input.
Map produces a new list of key/value pairs:
- An output of Map is called intermediate output.
- Can be the different type from input pair.
- An output of map is stored on the local disk from where it is shuffled to reduce nodes.
Next in Hadoop MapReduce Tutorial is the Hadoop Abstraction
iv. Reduce Abstraction
Now let’s discuss the second phase of MapReduce – Reducer in this MapReduce Tutorial, what is the input to the reducer, what work reducer does, where reducer writes output?
Reduce takes intermediate Key / Value pairs as input and processes the output of the mapper. Usually, in the reducer, we do aggregation or summation sort of computation.
- Input given to reducer is generated by Map (intermediate output)
- Key / Value pairs provided to reduce are sorted by key
Reduce processing:
- A function defined by user – Here also user can write custom business logic and get the final output.
- Iterator supplies the values for a given key to the Reduce function.
Reduce produces a final list of key/value pairs:
- An output of Reduce is called Final output.
- It can be a different type from input pair.
- An output of Reduce is stored in HDFS.
Let us understand in this Hadoop MapReduce Tutorial How Map and Reduce work together.
v. How Map and Reduce work Together?
Let us understand how Hadoop Map and Reduce work together?

Hadoop MapReduce Tutorial: Combined working of Map and Reduce
Input data given to mapper is processed through user defined function written at mapper. All the required complex business logic is implemented at the mapper level so that heavy processing is done by the mapper in parallel as the number of mappers is much more than the number of reducers. Mapper generates an output which is intermediate data and this output goes as input to reducer.
This intermediate result is then processed by user defined function written at reducer and final output is generated. Usually, in reducer very light processing is done. This final output is stored in HDFS and replication is done as usual.
vi. MapReduce DataFlow
Now let’s understand in this Hadoop MapReduce Tutorial complete end to end data flow of MapReduce, how input is given to the mapper, how mappers process data, where mappers write the data, how data is shuffled from mapper to reducer nodes, where reducers run, what type of processing should be done in the reducers?
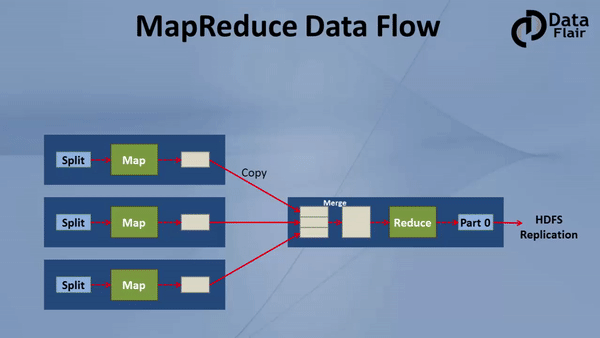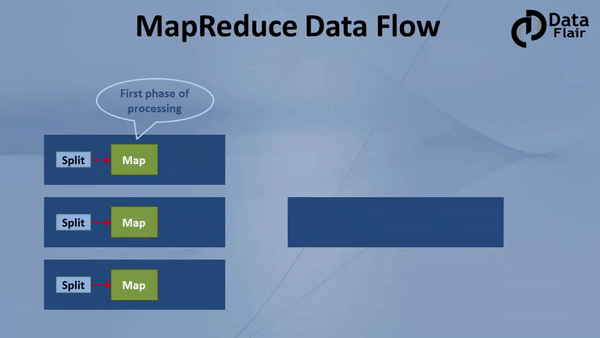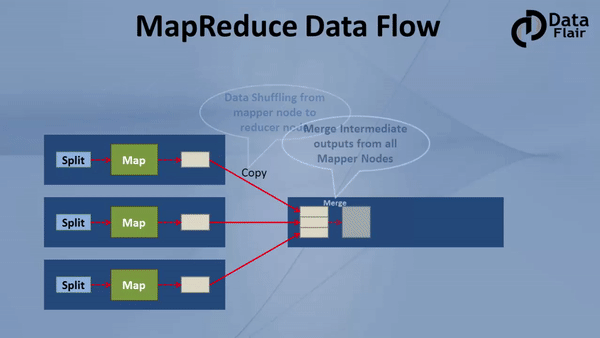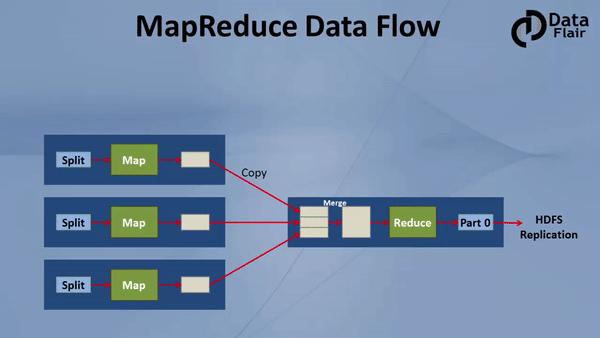
Hadoop MapReduce Tutorial: Hadoop MapReduce Dataflow Process
As seen from the diagram of mapreduce workflow in Hadoop, the square block is a slave. There are 3 slaves in the figure. On all 3 slaves mappers will run, and then a reducer will run on any 1 of the slave. For simplicity of the figure, the reducer is shown on a different machine but it will run on mapper node only.
Let us now discuss the map phase:
An input to a mapper is 1 block at a time. (Split = block by default)
An output of mapper is written to a local disk of the machine on which mapper is running. Once the map finishes, this intermediate output travels to reducer nodes (node where reducer will run).
Reducer is the second phase of processing where the user can again write his custom business logic. Hence, an output of reducer is the final output written to HDFS.
By default on a slave, 2 mappers run at a time which can also be increased as per the requirements. It depends again on factors like datanode hardware, block size, machine configuration etc. We should not increase the number of mappers beyond the certain limit because it will decrease the performance.
Mapper in Hadoop Mapreduce writes the output to the local disk of the machine it is working. This is the temporary data. An output of mapper is also called intermediate output. All mappers are writing the output to the local disk. As First mapper finishes, data (output of the mapper) is traveling from mapper node to reducer node. Hence, this movement of output from mapper node to reducer node is called shuffle.
Reducer is also deployed on any one of the datanode only. An output from all the mappers goes to the reducer. All these outputs from different mappers are merged to form input for the reducer. This input is also on local disk. Reducer is another processor where you can write custom business logic. It is the second stage of the processing. Usually to reducer we write aggregation, summation etc. type of functionalities. Hence, Reducer gives the final output which it writes on HDFS.
Map and reduce are the stages of processing. They run one after other. After all, mappers complete the processing, then only reducer starts processing.
Though 1 block is present at 3 different locations by default, but framework allows only 1 mapper to process 1 block. So only 1 mapper will be processing 1 particular block out of 3 replicas. The output of every mapper goes to every reducer in the cluster i.e every reducer receives input from all the mappers. Hence, framework indicates reducer that whole data has processed by the mapper and now reducer can process the data.
An output from mapper is partitioned and filtered to many partitions by the partitioner. Each of this partition goes to a reducer based on some conditions. Hadoop works with key value principle i.e mapper and reducer gets the input in the form of key and value and write output also in the same form. Follow this link to learn How Hadoop works internally? MapReduce DataFlow is the most important topic in this MapReduce tutorial. If you have any query regading this topic or ant topic in the MapReduce tutorial, just drop a comment and we will get back to you. Now, let us move ahead in this MapReduce tutorial with the Data Locality principle.
viii. Data Locality in MapReduce
Let’s understand what is data locality, how it optimizes Map Reduce jobs, how data locality improves job performance?
“Move computation close to the data rather than data to computation”. A computation requested by an application is much more efficient if it is executed near the data it operates on. This is especially true when the size of the data is very huge. This minimizes network congestion and increases the throughput of the system. The assumption is that it is often better to move the computation closer to where the data is present rather than moving the data to where the application is running. Hence, HDFS provides interfaces for applications to move themselves closer to where the data is present.
Since Hadoop works on huge volume of data and it is not workable to move such volume over the network. Hence it has come up with the most innovative principle of moving algorithm to data rather than data to algorithm. This is called data locality.
This was all about the Hadoop MapReduce Tutorial.
3. Conclusion: Hadoop MapReduce Tutorial
Hence, MapReduce empowers the functionality of Hadoop. Since it works on the concept of data locality, thus improves the performance. In the next tutorial of mapreduce, we will learn the shuffling and sorting phase in detail.
This was all about the Hadoop Mapreduce tutorial. I Hope you are clear with what is MapReduce like the Hadoop MapReduce Tutorial.
See Also-
If you have any question regarding the Hadoop Mapreduce Tutorial OR if you like the Hadoop MapReduce tutorial please let us know your feedback in the comment section.
Your opinion matters
Please write your valuable feedback about DataFlair on Google


Thanks! That was really very informative blog on Hadoop MapReduce Tutorial. Can you please elaborate more on what is mapreduce and abstraction and what does it actually mean? Otherwise, overall it was a nice MapReduce Tutorial and helped me understand Hadoop Mapreduce in detail.
Great Hadoop MapReduce Tutorial. Now I understand what is MapReduce and MapReduce programming model completely. Hadoop and MapReduce are now my favorite topics. ☺
The output of every mapper goes to every reducer in the cluster i.e every reducer receives input from all the mappers.
Can you explain above statement, Please ?
As output of mappers goes to 1 reducer ( like wise many reducer’s output we will get )
and then finally all reducer’s output merged and formed final output.
But you said each mapper’s out put goes to each reducers, How and why ?
Reducer does not work on the concept of Data Locality so, all the data from all the mappers have to be moved to the place where reducer resides. There is a middle layer called combiners between Mapper and Reducer which will take all the data from mappers and groups data by key so that all values with similar key will be one place which will further given to each reducer.
It is good tutorial. Now I understood all the concept clearly. But I want more information on big data and data analytics.please help me for big data and data analytics.
The output of every mapper goes to every reducer in the cluster i.e every reducer receives input from all the mappers.
what does this mean ?? there are many reducers??please explain
You have mentioned “Though 1 block is present at 3 different locations by default, but framework allows only 1 mapper to process 1 block.” Can you please elaborate on why 1 block is present at 3 locations by default ?
It is replication policy of the hadoop (hdfs) to maintain the high availability of data .Default replication factor is 3 this replication factor and it is configurable. So in order to maintain this policy (rule) namenode creates 3 copies of each and every block and stores it on different datanodes.Again to store this copies there another one policy rack awarness policy.
On which node does the shuffling, sorting and partitioning takes place? Mapper node or Reducer node?