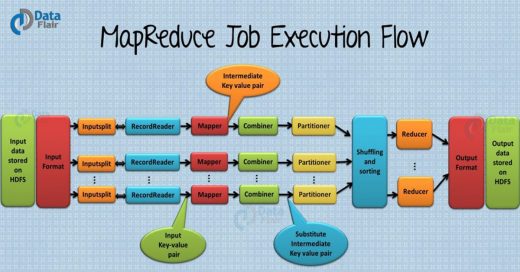
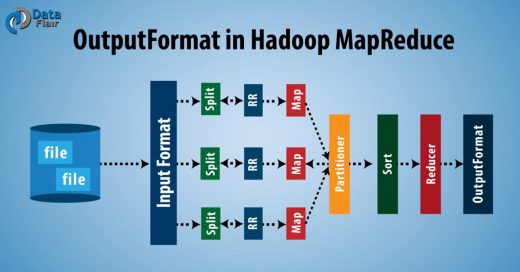
MapReduce Practice Test – Unlock it in 5 Minutes and 9 Seconds
Given below the Hadoop MapReduce practice test includes many questions, which will help you to crack Hadoop developer interview, Hadoop admin interview, Big Data Hadoop Interview and many more. So, are you ready for...