Hadoop Output Format – Types of Output Format in Mapreduce
1. Hadoop Output Format – Objective
The Hadoop Output Format checks the Output-Specification of the job. It determines how RecordWriter implementation is used to write output to output files. In this blog, we are going to see what is Hadoop Output Format, what is Hadoop RecordWriter, how RecordWriter is used in Hadoop?
In this Hadoop Reducer Output Format guide, will also discuss various types of Output Format in Hadoop like textOutputFormat, sequenceFileOutputFormat, mapFileOutputFormat, sequenceFileAsBinaryOutputFormat, DBOutputFormat, LazyOutputForma, and MultipleOutputs.
Learn How to install Cloudera Hadoop CDH5 on CentOS.
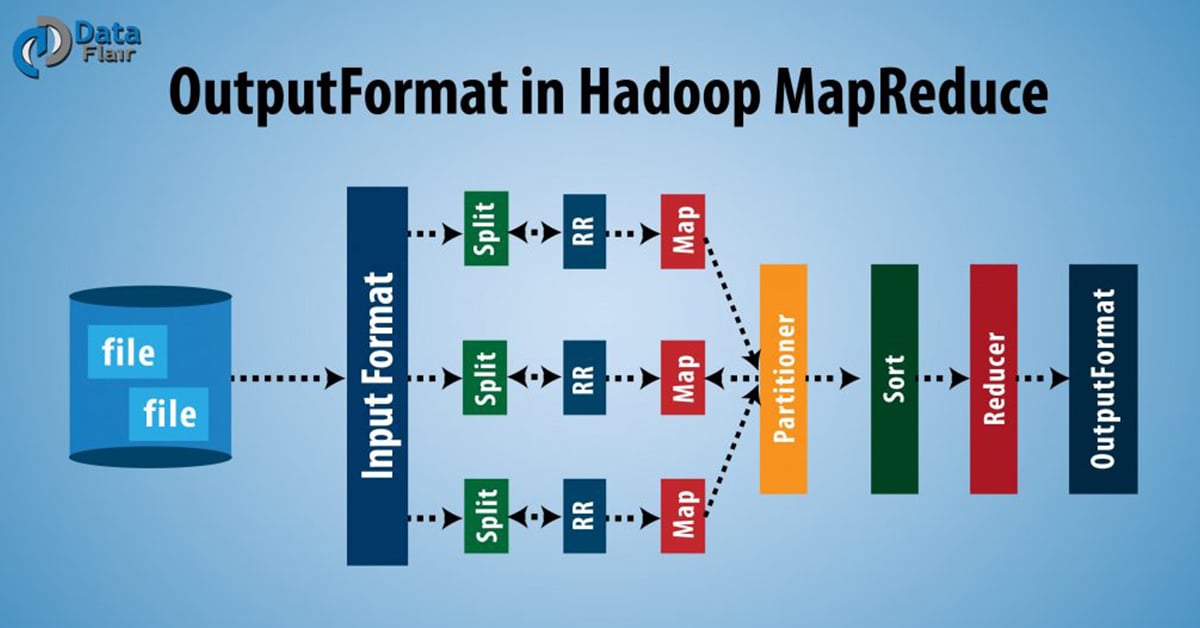
Hadoop Output Format – Types of Output Format in Mapreduce
2. What is Hadoop Output Format?
Before we start with Hadoop Output Format in MapReduce, let us first see what is a RecordWriter in MapReduce and what is its role in MapReduce?
i. Hadoop RecordWriter
As we know, Reducer takes as input a set of an intermediate key-value pair produced by the mapper and runs a reducer function on them to generate output that is again zero or more key-value pairs.
RecordWriter writes these output key-value pairs from the Reducer phase to output files.
Read: MapReduce Input Format
ii. Hadoop Output Format
As we saw above, Hadoop RecordWriter takes output data from Reducer and writes this data to output files. The way these output key-value pairs are written in output files by RecordWriter is determined by the Output Format. The Output Format and InputFormat functions are alike. OutputFormat instances provided by Hadoop are used to write to files on the HDFS or local disk. OutputFormat describes the output-specification for a Map-Reduce job. On the basis of output specification;
- MapReduce job checks that the output directory does not already exist.
- OutputFormat provides the RecordWriter implementation to be used to write the output files of the job. Output files are stored in a FileSystem.
FileOutputFormat.setOutputPath() method is used to set the output directory. Every Reducer writes a separate file in a common output directory.
3. Types of Hadoop Output Formats
There are various types of Hadoop OutputFormat. Let us see some of them below:
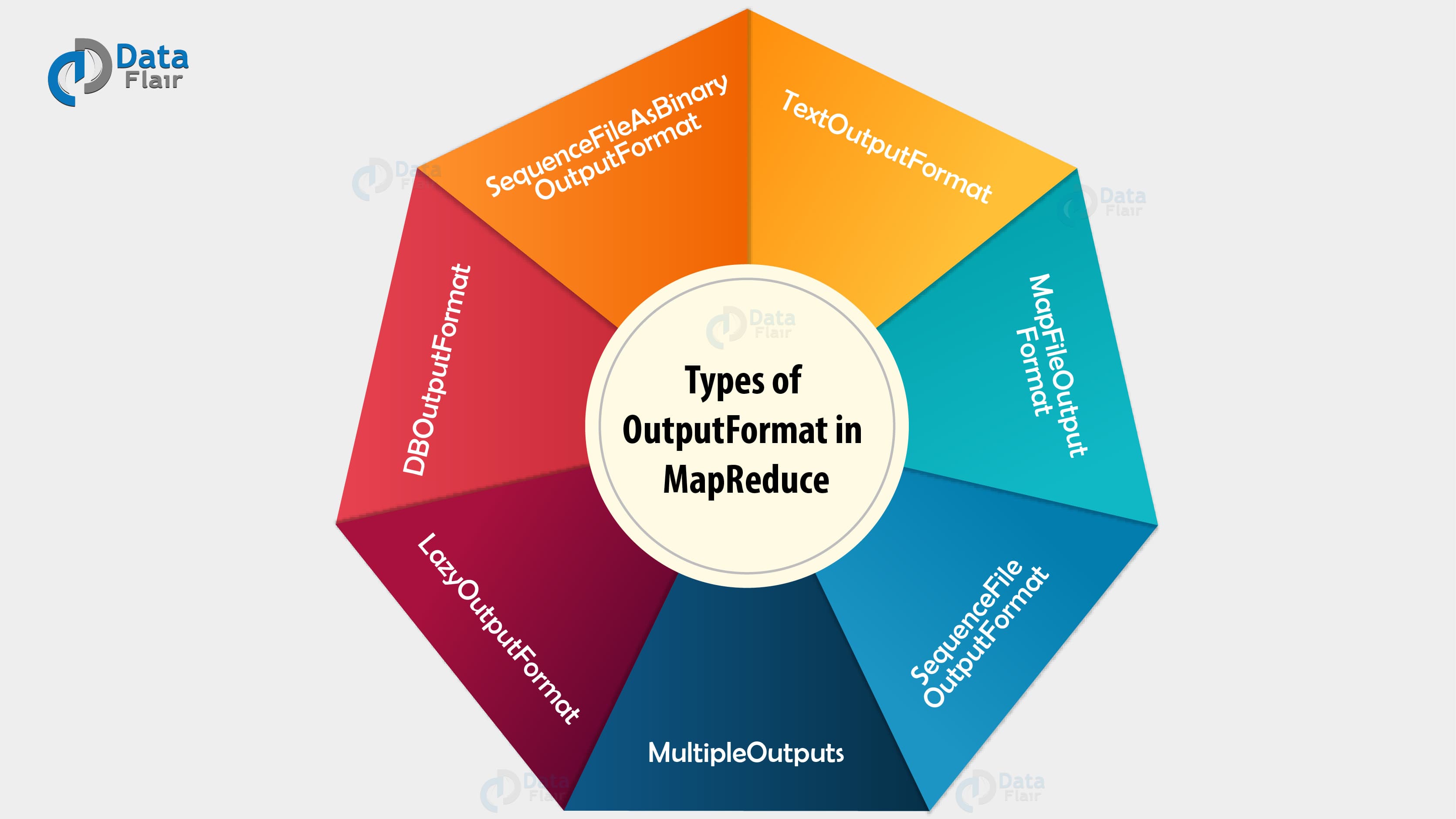
Types of Hadoop Output Formats
Read: MapReduce Recordreader
i. TextOutputFormat
MapReduce default Hadoop reducer Output Format is TextOutputFormat, which writes (key, value) pairs on individual lines of text files and its keys and values can be of any type since TextOutputFormat turns them to string by calling toString() on them. Each key-value pair is separated by a tab character, which can be changed using MapReduce.output.textoutputformat.separator property. KeyValueTextOutputFormat is used for reading these output text files since it breaks lines into key-value pairs based on a configurable separator.
ii. SequenceFileOutputFormat
It is an Output Format which writes sequences files for its output and it is intermediate format use between MapReduce jobs, which rapidly serialize arbitrary data types to the file; and the corresponding SequenceFileInputFormat will deserialize the file into the same types and presents the data to the next mapper in the same manner as it was emitted by the previous reducer, since these are compact and readily compressible. Compression is controlled by the static methods on SequenceFileOutputFormat.
iii. SequenceFileAsBinaryOutputFormat
It is another form of SequenceFileInputFormat which writes keys and values to sequence file in binary format.
Read: MapReduce Shuffling and Sorting
iv. MapFileOutputFormat
It is another form of FileOutputFormat in Hadoop Output Format, which is used to write output as map files. The key in a MapFile must be added in order, so we need to ensure that reducer emits keys in sorted order.
Any doubt yet in Hadoop Oputput Format? Please Ask.
v. MultipleOutputs
It allows writing data to files whose names are derived from the output keys and values, or in fact from an arbitrary string.
vi. LazyOutputFormat
Sometimes FileOutputFormat will create output files, even if they are empty. LazyOutputFormat is a wrapper OutputFormat which ensures that the output file will be created only when the record is emitted for a given partition.
Read: MapReduce Input Split
vii. DBOutputFormat
DBOutputFormat in Hadoop is an Output Format for writing to relational databases and HBase. It sends the reduce output to a SQL table. It accepts key-value pairs, where the key has a type extending DBwritable. Returned RecordWriter writes only the key to the database with a batch SQL query.
This was all on Hadoop Output format Tutorial.
4. Hadoop Reducer Output Format – Conclusion
Hence, these types of Hadoop reducer Output Format check the Output-Specification of the job. In the next session, we will discuss Hadoop InputSplits in detail. if you have any doubt related to Hadoop OutputFormat so please let us know in the comment box. We will be happy to solve your queries.
See Also-
In case of any queries in the Hadoop Output Format or feedback feel free to drop your comment in the comment section below and we will be back to you.
You give me 15 seconds I promise you best tutorials
Please share your happy experience on Google





This was a really nice article on Hadoop Output Format. THanks for wonderfully explaining the Types of Output format in Mapreduce. I wonder if is it possible to store the output of reducer which is a DBOutputFormat in the input of mapper, to more explain, in one MapReduce workflow, the input and output paths are the same!!
Hi Data Flair,
The all above posts are greats, But i have a question about MR phases, like all the other formats. Does Junior Hadoop Admin really need to know all this things ? I mean this is all good, knowledge always works somewhere but at the initial phases in training is that all need to understand ?
Hi
Can you please show an example where SequenceFileOutputFormat gets used , say perhaps when we are working on a chain of mapreduce jobs with one flow of mapreduce writing in this format and the second one picking from this format?
Regards
How null output format works??