Learn the Concept of Key-Value Pair in Hadoop MapReduce
1. Objective
In this MapReduce tutorial, we are going to learn the concept of a key-value pair in Hadoop. The key Value pair is the record entity that MapReduce job receives for execution. By default, RecordReader uses TextInputFormat for converting data into a key-value pair. Here we will learn what is a key-value pair in MapReduce, how key-value pairs are generated in Hadoop using InputSplit and RecordReader and on what basis generation of key-value pairs in Hadoop MapReduce takes place? We will also see Hadoop key-value pair example in this tutorial.
Learn the Concept of Key-Value Pair in Hadoop MapReduce
To practically implement MapReduce Programs, firstly install Hadoop on your system.
2. What is a key-value pair in Hadoop?
Apache Hadoop is used mainly for Data Analysis. We look at statistical and logical techniques in data Analysis to describe, illustrate and evaluate data. Hadoop deals with structured, unstructured and semi-structured data. In Hadoop, when the schema is static we can directly work on the column instead of keys and values, but, when the schema is not static, then we will work on keys and values. Keys and values are not the intrinsic properties of the data, but they are chosen by user analyzing the data.
MapReduce is the core component of Hadoop which provides data processing. Hadoop MapReduce is a software framework for easily writing an application that processes the vast amount of structured and unstructured data stored in the Hadoop Distributed FileSystem (HDFS). MapReduce works by breaking the processing into two phases: Map phase and Reduce phase. Each phase has key-value as input and output. Learn more about how data flows in Hadoop MapReduce?
3. Key-value pair Generation in MapReduce
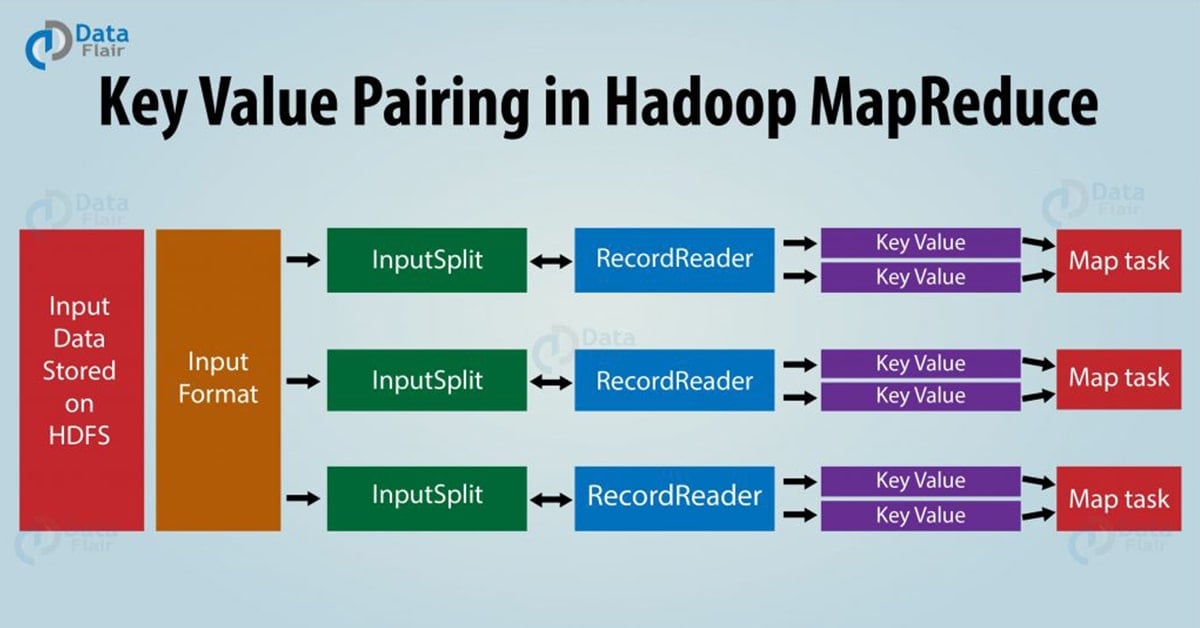
Let us now learn how key-value pair is generated in Hadoop MapReduce?In MapReduce process, before passing the data to the mapper, data should be first converted into key-value pairs as mapper only understands key-value pairs of data.
key-value pairs in Hadoop MapReduce is generated as follows:
- InputSplit – It is the logical representation of data. The data to be processed by an individual Mapper is presented by the InputSplit. Learn MapReduce InputSplit in detail.
- RecordReader – It communicates with the InputSplit and it converts the Split into records which are in form of key-value pairs that are suitable for reading by the mapper. By default, RecordReader uses TextInputFormat for converting data into a key-value pair. RecordReader communicates with the InputSplit until the file reading is not completed. Learn more about MapReduce record reader in detail.
In MapReduce, map function processes a certain key-value pair and emits a certain number of key-value pairs and the Reduce function processes values grouped by the same key and emits another set of key-value pairs as output. The output types of the Map should match the input types of the Reduce as shown below:
- Map: (K1, V1) -> list (K2, V2)
- Reduce: {(K2, list (V2 }) -> list (K3, V3)
4. On what basis is a key-value pair generated in Hadoop?
Generation of a key-value pair in Hadoop depends on the data set and the required output. In general, the key-value pair is specified in 4 places: Map input, Map output, Reduce input and Reduce output.
a. Map Input
Map-input by default will take the line offset as the key and the content of the line will be the value as Text. By using custom InputFormat we can modify them.
b. Map Output
Map basic responsibility is to filter the data and provide the environment for grouping of data based on the key.
- Key – It will be the field/ text/ object on which the data has to be grouped and aggregated on the reducer side.
- Value – It will be the field/ text/ object which is to be handled by each individual reduce method.
c. Reduce Input
The output of Map is the input for reduce, so it is same as Map-Output.
d. Reduce Output
It depends on the required output.
5. MapReduce key-value pair Example
Suppose, the content of the file which is stored in HDFS is John is Mark Joey is John. Using InputFormat, we will define how this file will split and read. By default, RecordReader uses TextInputFormat to convert this file into a key-value pair.
- Key – It is offset of the beginning of the line within the file.
- Value – It is the content of the line, excluding line terminators.
From the above content of the file-
- Key is 0
- Value is John is Mark Joey is John.
6. Conclusion
In conclusion, we can say that InputSplit and RecordReader generate the Key-value pair in Hadoop by using TextInputFormat. Hence, Key is the byte offset of the beginning of the line within the file and Value is the content of the line excluding line terminators.
Hope this blog helped you to more understand the working process of MapReduce. If you have any question in mind so you can share with us by leaving a comment below.
See Also-
If you are Happy with DataFlair, do not forget to make us happy with your positive feedback on Google





Please answer below:
for a given input key-value pair can a mapper write multiple key value pairs
The answer is yes based on what they have described in the above blog. They have mentioned as follows:
In MapReduce, map function processes a certain key-value pair and emits a certain number of key-value pairs and the Reduce function processes values grouped by the same key and emits another set of key-value pairs as output. The output types of the Map should match the input types of the Reduce as shown below:
Map: (K1, V1) -> list (K2, V2)
Reduce: {(K2, list (V2 }) -> list (K3, V3)