Hadoop Counters | The Most Complete Guide to MapReduce Counters
1. Hadoop Counters: Objective
In this MapReduce Hadoop Counters tutorial, we will provide you the detailed description of MapReduce Counters in Hadoop. The tutorial covers an introduction to Hadoop MapReduce counters, Types of Hadoop Counters such as Built-in Counters and User-defined counters. In this Hadoop counters tutorial, we will also discuss the FileInputFormat and FileOutputFormat of Hadoop MapReduce.
Hadoop Counters
2. What is Hadoop MapReduce?
Before we start with Hadoop Counters, let us first see the overview of Hadoop MapReduce.
MapReduce is the core component of Hadoop which provides data processing. MapReduce works by breaking the processing into two phases; Map phase and Reduce phase. The map is the first phase of processing, where we specify all the complex logic/business rules/costly code, whereas the Reduce phase is the second phase of processing, where we specify light-weight processing like aggregation/ summation.
In Hadoop, MapReduce Framework has certain elements such as Counters, Combiners, and Partitioners, which play a key role in improving the performance of data processing.
Let’s now focus on Hadoop MapReduce Counters here.
Read: DataFlaw in MapReduce
3. What are Hadoop Counters?
Hadoop Counters Explained: Hadoop Counters provides a way to measure the progress or the number of operations that occur within map/reduce job. Counters in Hadoop MapReduce are a useful channel for gathering statistics about the MapReduce job: for quality control or for application-level. They are also useful for problem diagnosis.
Counters represent Hadoop global counters, defined either by the MapReduce framework or applications. Each Hadoop counter is named by an “Enum” and has a long for the value. Counters are bunched into groups, each comprising of counters from a particular Enum class.
Hadoop Counters validate that:
- The correct number of bytes was read and written.
- The correct number of tasks was launched and successfully ran.
- The amount of CPU and memory consumed is appropriate for our job and cluster nodes.
Read about Key – Value Pairs
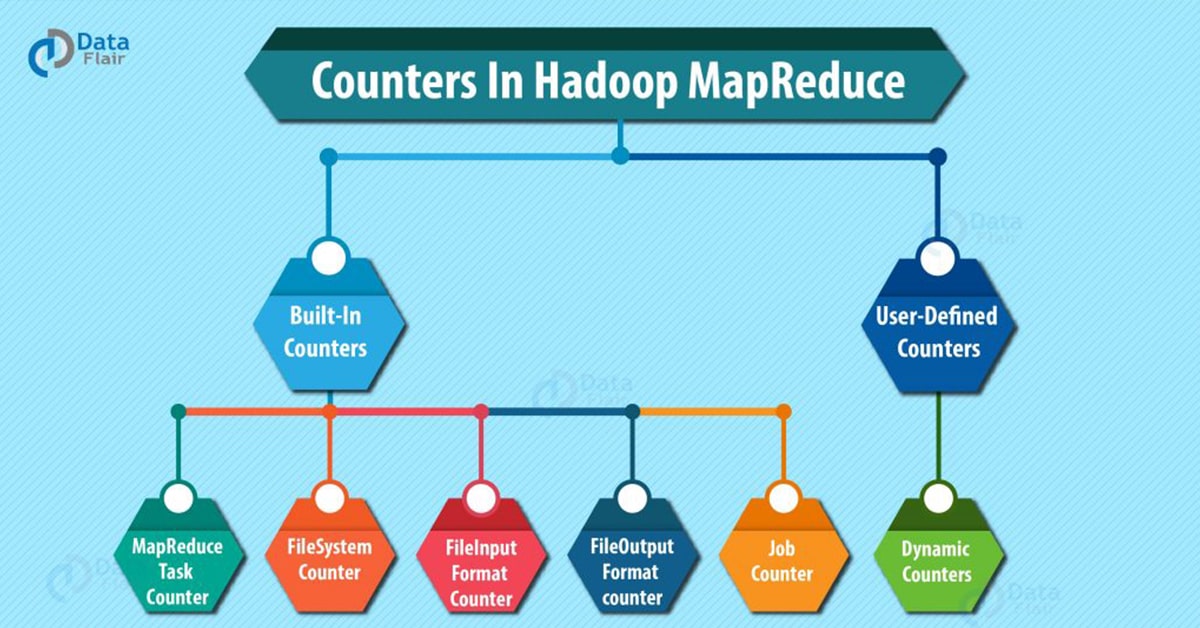
4. Types of Hadoop MapReduce Counters
There are basically 2 types of MapReduce Counters:
- Built-In Counters in MapReduce
- User-Defined Counters/Custom counters in MapReduce
Let’s discuss these types counters in Hadoop MapReduce:
4.1. Built-In Counters in MapReduce
Hadoop maintains some built-in Hadoop counters for every job and these report various metrics, like, there are counters for the number of bytes and records, which allow us to confirm that the expected amount of input is consumed and the expected amount of output is produced.
Hadoop Counters are divided into groups and there are several groups for the built-in counters. Each group either contains task counters (which are updated as task progress) or job counter (which are updated as a job progress).
There are several groups for the Hadoop built-in Counters:
a. MapReduce Task Counter in Hadoop
Hadoop Task counter collects specific information (like number of records read and written) about tasks during its execution time. For example, the MAP_INPUT_RECORDS counter is the Task Counter which counts the input records read by each map task.
Hadoop Task counters are maintained by each task attempt and periodically sent to the application master so they can be globally aggregated.
b. FileSystem Counters
Hadoop FileSystem Counters in Hadoop MapReduce gather information like a number of bytes read and written by the file system. Below are the name and description of the file system counters:
- FileSystem bytes read– The number of bytes read by the filesystem by map and reduce tasks.
- FileSystem bytes written– The number of bytes written to the filesystem by map and reduce tasks.
c. FileInputFormat Counters in Hadoop
FileInputFormat Counters in Hadoop MapReduce gather information of a number of bytes read by map tasks via FileInputFormat. Refer this guide to learn about InputFormat in Hadoop MapReduce.
d. FileOutputFormat counters in MapReduce
FileOutputFormat counters in Hadoop MapReduce gathers information of a number of bytes written by map tasks (for map-only jobs) or reduce tasks via FileOutputFormat. refer this guide to learn about OutputFormat in Hadoop MapReduce in detail.
e. MapReduce Job Counters
MapReduce Job counter measures the job-level statistics, not values that change while a task is running. For example, TOTAL_LAUNCHED_MAPS, count the number of map tasks that were launched over the course of a job (including tasks that failed). Application master maintains MapReduce Job counters, so these Hadoop Counters don’t need to be sent across the network, unlike all other counters, including user-defined ones.
4.2. User-Defined Counters/Custom Counters in Hadoop MapReduce
In addition to MapReduce built-in counters, MapReduce allows user code to define a set of counters, which are then incremented as desired in the mapper or reducer. For example, in Java, ‘enum’ is used to define counters.
A job may define an arbitrary number of ‘enums’, each with an arbitrary number of fields. The name of the enum is the group name, and the enum’s fields are the counter names.
a. Dynamic Counters in Hadoop MapReduce
Java enum’s fields are defined at compile time, so we cannot create new counters in Hadoop MapReduce at runtime using enums. To do so, we use dynamic counters in Hadoop MapReduce, one that is not defined at compile time using java enum.
Read: Shuffing and Sorting in MapReduce
5. MapReduce Counters: Conclusion
In conclusion, Counters check whether the correct number of bytes is read or written, the correct number of tasks are launched and successfully run. Hence, Hadoop maintains built-in counters and user-defined counters to measure the progress that occurs within MapReduce job.
If you like this blog or have any query, feel free to share with us. We will be happy to solve them.
See Also-
We work very hard to provide you quality material
Could you take 15 seconds and share your happy experience on Google




