Hadoop MapReduce Flow – How data flows in MapReduce?
1. Objective
Hadoop MapReduce processes a huge amount of data in parallel by dividing the job into a set of independent tasks (sub-job). In Hadoop, MapReduce works by breaking the processing into phases: Map and Reduce. In this tutorial, will explain you the complete Hadoop MapReduce flow.
This MapReduce tutorial, will cover an end to end Hadoop MapReduce flow. Hope this blog will give you the answer for how Hadoop MapReduce works, how data is processed when a map-reduce job is submitted. Step by step execution flow of MapReduce, what are the steps involved in MapReduce job execution, etc. Let’s get the answer to all these questions with the deep study of Hadoop MapReduce flow.

Hadoop MapReduce Flow – How data flows in MapReduce?
2. What is MapReduce?
MapReduce is the data processing layer of Hadoop (other layers are HDFS – data processing layer, Yarn – resource management layer). MapReduce is a programming paradigm designed for processing huge volumes of data in parallel by dividing the job (submitted work) into a set of independent tasks (sub-job). You just need to put the custom code (business logic) in the way map reduce works and rest things will be taken care by the engine.
2.1. Hadoop MapReduce Flow – MapReduce Video Tutorial
We have also provided the video tutorial for more understanding of the internal of Hadoop MapReduce flow.
3. How Hadoop MapReduce Works?
MapReduce Data Flow
MapReduce is the heart of Hadoop. It is a programming model designed for processing huge volumes of data (both structured as well as unstructured) in parallel by dividing the work into a set of independent sub-work (tasks). Let’s discuss How MapReduce works internally-
3.1. MapReduce Internals
MapReduce is the combination of two different processing idioms called Map and Reduce, where we can specify our custom business logic. The map is the first phase of processing, where we specify all the complex logic/business rules/costly code. On the other hand, Reduce is the second phase of processing, where we specify light-weight processing. For example, aggregation/summation.
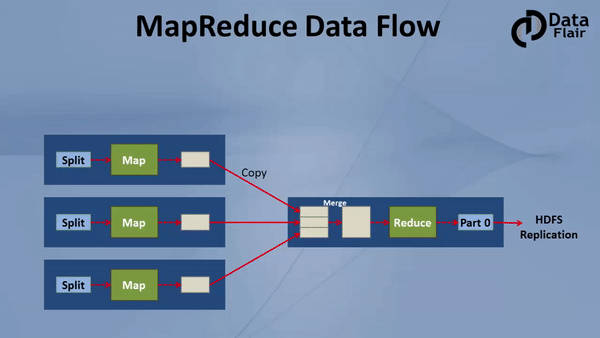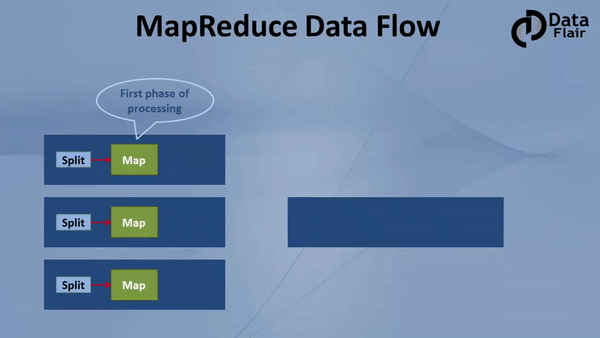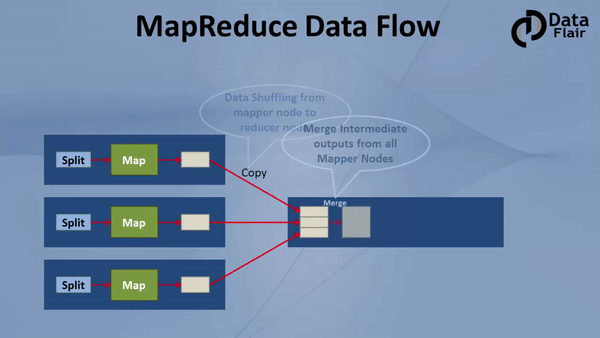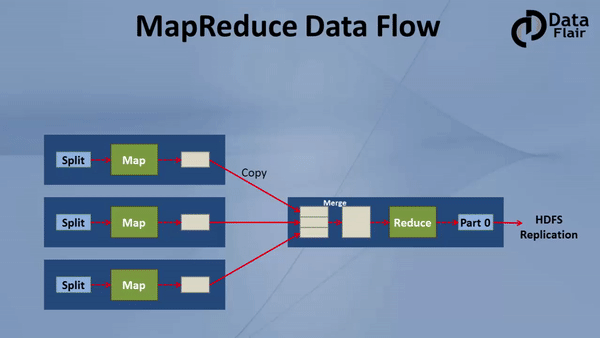
3.2. Step by step MapReduce Job Flow
The data processed by MapReduce should be stored in HDFS, which divides the data into blocks and store distributedly, for more details about HDFS follow this HDFS comprehensive tutorial. Below are the steps for MapReduce data flow:
- Step 1: One block is processed by one mapper at a time. In the mapper, a developer can specify his own business logic as per the requirements. In this manner, Map runs on all the nodes of the cluster and process the data blocks in parallel.
- Step 2: Output of Mapper also known as intermediate output is written to the local disk. An output of mapper is not stored on HDFS as this is temporary data and writing on HDFS will create unnecessary many copies.
- Step 3: Output of mapper is shuffled to reducer node (which is a normal slave node but reduce phase will run here hence called as reducer node). The shuffling/copying is a physical movement of data which is done over the network.
- Step 4: Once all the mappers are finished and their output is shuffled on reducer nodes then this intermediate output is merged & sorted. Which is then provided as input to reduce phase.
- Step 5: Reduce is the second phase of processing where the user can specify his own custom business logic as per the requirements. An input to a reducer is provided from all the mappers. An output of reducer is the final output, which is written on HDFS.
Hence, in this manner, a map-reduce job is executed over the cluster. All the complexities of distributed processing are handled by the framework. For example, data/code distribution, high availability, fault-tolerance, data locality, etc. The user just needs to concentrate on his own business requirements and write his custom code at specified phases (map and reduce).
3.3. Data Locality
Data locality is one of the most innovative principles which says move the algorithm close to the data rather than moving the data. Since data is in the range of Petabytes. Movement of petabytes of data is not workable, hence algorithms / user-codes are moved to the location where data is present. If we summarize data locality – Movement of computation is cheaper than the movement of data. To learn data locality in detail follow this quick guide.
4. Conclusion
In conclusion, we can say that data flow in MapReduce is the combination of Map and Reduce. The map takes a set of data and converts it into another set of data, where individual elements are broken down into tuples (key/value pairs). Then, Reduce takes the input from the Map and combines those data tuples based on the key and modifies the value of the key. Hence, in this manner, a map-reduce job is executed over the cluster. Thus all the complexities of distributed processing are handled by the framework.
If you have any query related to Hadoop MapReduce data flow process, so please feel free to share with us.
References:
hadoop.apache.org
See Also-
Your opinion matters
Please write your valuable feedback about DataFlair on Google





Brilliant explanation, got the complete end to end flow of Hadoop clear, the attached video is really great, speaker covered internals of Map Reduce.
I like the architecture of MapReduce and its job submission flow.
Very nicely explained how data flows in Map Reduce in Hadoop.
hi. really you have post an informative blog. it will be really helpful to many peoples. thank you for sharing this blog.
Very nicely explained data flow with GIF.
Very well explianed data flow in map Reduce!!
it is nice tutorial sir, can you please show practical implementation of this please share me
[email protected]
This is a good technical document. but could you please give a practical example of the dataflow, i mean starting from ‘copyFromLocal’ to output of reduce job.
after copying the data how hdfs manages to store data into data node through name node, how YARN is involved here…etc.
Thanks.
1. Can you please explain flow chart when a client submit a job. First it goes to name node or resource manager?
2. Before reduce starts one of the mapper file saved in temporary file system deleted want happens?
Where is combiner and partitioner??