InputSplit in Hadoop MapReduce – Hadoop MapReduce Tutorial
1. Objective
In this Hadoop MapReduce tutorial, we will provide you the detailed description of InputSplit in Hadoop. In this blog, we will try to answer What is Hadoop InputSplit, what is the need of inputSplit in MapReduce and how Hadoop performs InputSplit, How to change split size in Hadoop. We will also learn the difference between InputSplit vs Blocks in HDFS.
InputSplit in Hadoop MapReduce – Hadoop MapReduce Tutorial
2. What is InputSplit in Hadoop?
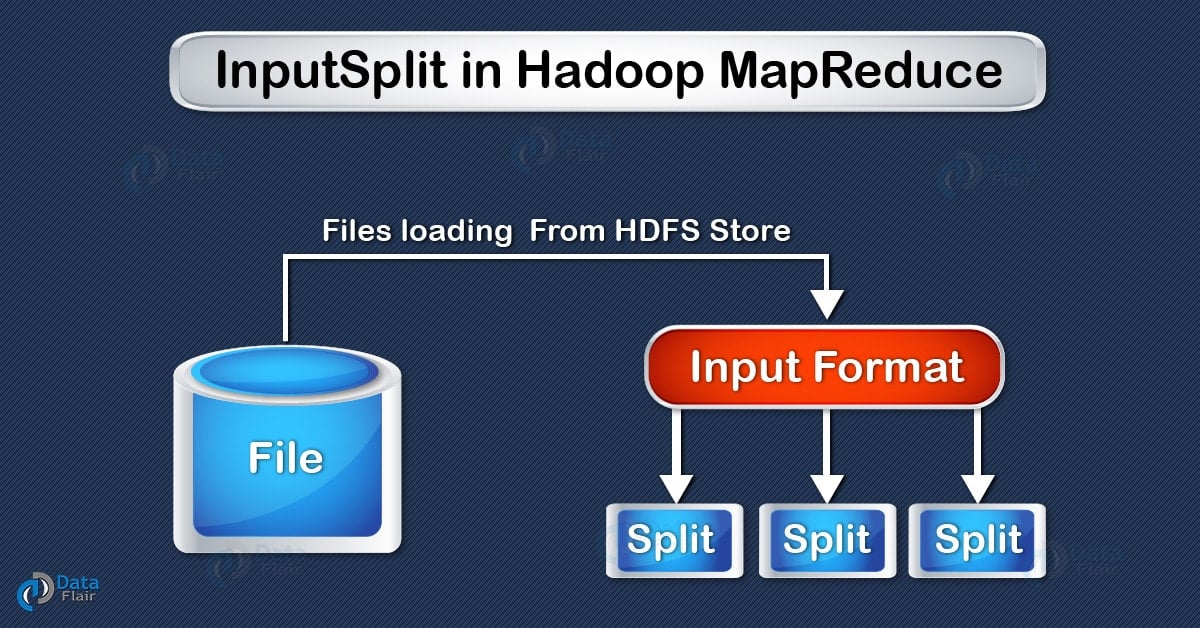
InputSplit in Hadoop MapReduce is the logical representation of data. It describes a unit of work that contains a single map task in a MapReduce program.
Hadoop InputSplit represents the data which is processed by an individual Mapper. The split is divided into records. Hence, the mapper process each record (which is a key-value pair).
MapReduce InputSplit length is measured in bytes and every InputSplit has storage locations (hostname strings). MapReduce system use storage locations to place map tasks as close to split’s data as possible. Map tasks are processed in the order of the size of the splits so that the largest one gets processed first (greedy approximation algorithm) and this is done to minimize the job runtime (Learn MapReduce job optimization techniques)The important thing to notice is that Inputsplit does not contain the input data; it is just a reference to the data.
As a user, we don’t need to deal with InputSplit directly, because they are created by an InputFormat (InputFormat creates the Inputsplit and divide into records). FileInputFormat, by default, breaks a file into 128MB chunks (same as blocks in HDFS) and by setting mapred.min.split.size parameter in mapred-site.xml we can control this value or by overriding the parameter in the Job object used to submit a particular MapReduce job. We can also control how the file is broken up into splits, by writing a custom InputFormat.
3. How to change split size in Hadoop?
InputSplit in Hadoop is user defined. User can control split size according to the size of data in MapReduce program. Thus the number of map tasks is equal to the number of InputSplits.
The client (running the job) can calculate the splits for a job by calling ‘getSplit()’, and then sent to the application master, which uses their storage locations to schedule map tasks that will process them on the cluster. Then, map task passes the split to the createRecordReader() method on InputFormat to get RecordReader for the split and RecordReader generate record (key-value pair), which it passes to the map function.
4. Conclusion
In conclusion, InputSplit doesn’t contain actual data, but a reference to the data. It is used during data processing in MapReduce program or other processing techniques. Hence, the split is divided into records and each record (which is a key-value pair) is processed by the map. Hope this blog helped you. If you like this blog or have any query related to InputSplit in Hadoop, so, leave a comment in a section given below.
Reference:
Technology is evolving rapidly!
Stay updated with DataFlair on WhatsApp!!
See Also-
- What is data Locality in Hadoop MapReduce?
- How Hadoop MapReduce Works?
- Top Hadoop MapReduce Interview Questions and Answers
You give me 15 seconds I promise you best tutorials
Please share your happy experience on Google


its very useful blog in terms of theory especially for interview purpose
its really very nice block to understand theoritically