Skew Join in Hive – Working, Tips & Examples
In our last article, we discuss Bucket Map Join in Hive, today we discuss Skew Join in hive. In Apache Hive, when there is a table with skew data in the joining column, we use Skew join in Hive.
However, there are much more to know about Skew join feature in Apache Hive. So, in this article, we will learn the what is Skew Join in Hive. Also, it includes Parameter of Hive Skew Join, limitations of Skew Join and Skew Join in Hive Examples.
Skew join in Hive
Basically, when there is a table with skew data in the joining column, we use skew join feature. On defining what is skewed table, it is a table that is having values that are present in large numbers in the table compared to other data.
However, while the rest of the data is stored in a separate file Skew data is stored in a separate file.
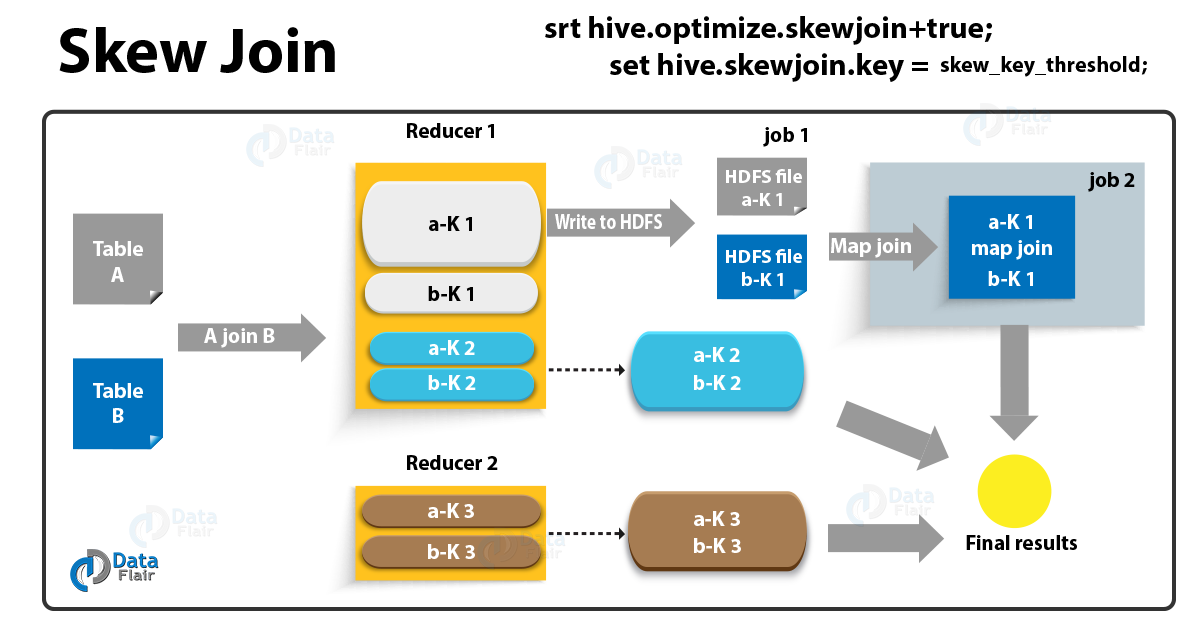
Skew Join
a. Parameter
However, to be set for a Hive skew join we need the following parameter:
set
hive.optimize.skewjoin=true;
set hive.skewjoin.key=100000;
b. Command to use
Moreover, a bucket sort merge map Join in Hive, Run the following command:
SELECT a.* FROM Sales a JOIN Sales_orc b ON a.id = b.id;
How Hive Skew Join Works
However, let’s assume if table A join B, and A has skew data “1” in joining column.
At First store, the rows with key 1 in an in-memory hash table and read B. Further to read A run a set of mappers. Afterward, do the following:
- Make sure use the hashed version of B to compute the result since it has key 1.
- Then, send all other keys to a reducer which does the join. Basically, from a mapper, this reducer will get rows of B also.
Hence, as a result, we end up reading only B twice. Basically, that implies that the skewed keys in A are only read and processed by the Mapper. Also, they are not sent to the reducer. Moreover, remaining keys in A go through only a single Map/Reduce.
However, the assumption is that B has few rows with keys which are skewed in A. Hence, in this way these rows can be loaded into the memory.
Skew Join – Use Case
- Basically, on the joining column, one table has huge skew values.
Disadvantages of Skew Join in Hive
Here, are some Limitations of Hive Skew Join are discussed:
- So, the major disadvantage of it is One table is read twice here.
- Moreover, it is necessary that users should be aware of the skew key.
Skew Join in Hive Example
Let’s discuss Hive Join example in brief.
hive> explain select a.* from passwords a, passwords2 b where a.col0=b.col1;
OK
STAGE DEPENDENCIES:
Stage-7 is a root stage , consists of Stage-1
Stage-1
Stage-4 depends on stages: Stage-1 , consists of Stage-8
Stage-8
Stage-3 depends on stages: Stage-8
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-7
Conditional Operator
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: b
Statistics: Num rows: 9961472 Data size: 477102080 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: col1 (type: string)
sort order: +
Map-reduce partition columns: col1 (type: string)
Statistics: Num rows: 9961472 Data size: 477102080 Basic stats: COMPLETE Column stats: NONE
value expressions: col1 (type: string)
TableScan
alias: a
Statistics: Num rows: 9963904 Data size: 477218560 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: col0 (type: string)
sort order: +
Map-reduce partition columns: col0 (type: string)
Statistics: Num rows: 9963904 Data size: 477218560 Basic stats: COMPLETE Column stats: NONE
value expressions: col0 (type: string), col1 (type: string), col2 (type: string), col3 (type: string), col4 (type: string), col5 (type: string), col6 (type: string)
Reduce Operator Tree:
Join Operator
condition map:
Inner Join 0 to 1
condition expressions:
0 {VALUE._col0} {VALUE._col1} {VALUE._col2} {VALUE._col3} {VALUE._col4} {VALUE._col5} {VALUE._col6}
1 {VALUE._col1}
handleSkewJoin: true
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col10
Statistics: Num rows: 10960295 Data size: 524940416 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (_col0 = _col10) (type: boolean)
Statistics: Num rows: 5480147 Data size: 262470184 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: string), _col1 (type: string), _col2 (type: string), _col3 (type: string), _col4 (type: string), _col5 (type: string), _col6 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6
Statistics: Num rows: 5480147 Data size: 262470184 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 5480147 Data size: 262470184 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-4
Conditional Operator
Stage: Stage-8
Map Reduce Local Work
Alias -> Map Local Tables:
1
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
1
TableScan
HashTable Sink Operator
condition expressions:
0 {0_VALUE_0} {0_VALUE_1} {0_VALUE_2} {0_VALUE_3} {0_VALUE_4} {0_VALUE_5} {0_VALUE_6}
1 {1_VALUE_0}
keys:
0 joinkey0 (type: string)
1 joinkey0 (type: string)
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
Map Join Operator
condition map:
Inner Join 0 to 1
condition expressions:
0 {0_VALUE_0} {0_VALUE_1} {0_VALUE_2} {0_VALUE_3} {0_VALUE_4} {0_VALUE_5} {0_VALUE_6}
1 {1_VALUE_0}
keys:
0 joinkey0 (type: string)
1 joinkey0 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col10
Filter Operator
predicate: (_col0 = _col10) (type: boolean)
Select Operator
expressions: _col0 (type: string), _col1 (type: string), _col2 (type: string), _col3 (type: string), _col4 (type: string), _col5 (type: string), _col6 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6
File Output Operator
compressed: false
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Local Work:
Map Reduce Local Work
Stage: Stage-0
Fetch Operator
limit: -1
Time taken: 0.331 seconds, Fetched: 110 row(s)
Hence, we can see that there are 2 join operators. Such as, one of them is common join and the other one is map join.
So, it shows “handleSkewJoin: true”.
Tips For Skew Join in Hive
Following are some Hive Skew Join Tips:
- However, to be set to enable skew join, we require the below parameter.
set hive.optimize.skewjoin=true; - Moreover, since if we get a skew key in join here it the parameter below that determine.
Also, we think the key as a skew join key since we see more than the specified number of rows with the same key in join operator.
set hive.skewjoin.key=100000;
Conclusion
As a result, we have seen all the concept of skew join feature in Apache Hive. We study what is Skew join in Hive, Parameter of Hive Skew Join, limitations of Skew Join, Skew Join in Hive Examples, Hive Skew Join Working, Skew Join – Use Case, and Tips For Skew Join in Hive.
Still, if any doubt occurs, please share through the comment section. Though, we assure we will get back to you definitely.
Did you like this article? If Yes, please give DataFlair 5 Stars on Google





skewjoin do not support outer join , please refer to GenMRSkewJoinProcessor.processSkewJoin methord , the comment before invoke skewJoinEnabled methord。as follower
public static void processSkewJoin(JoinOperator joinOp,
Task currTask, ParseContext parseCtx)
throws SemanticException {
// We are trying to adding map joins to handle skew keys, and map join right
// now does not work with outer joins
if (!GenMRSkewJoinProcessor.skewJoinEnabled(parseCtx.getConf(), joinOp)) {
return;
}
…….
}