Map Join in Hive | Map Side Join
In Apache Hive, there is a feature that we use to speed up Hive queries. Basically, that feature is what we call Map join in Hive. Map Join in Hive is also Called Map Side Join in Hive. However, there are many more insights of Apache Hive Map join.
So, in this Hive Tutorial, we will learn the whole concept of Map join in Hive. It includes Parameters, limitations of Map Side Join in Hive, Map Side Join in Hive Syntax. Moreover, we will see several Map Join in hive examples to understand well.
What is Map Join in Hive?
Apache Hive Map Join is also known as Auto Map Join, or Map Side Join, or Broadcast Join.
There is one more join available that is Common Join or Sort Merge Join.
However, there is a major issue with that it there is too much activity spending on shuffling data around. So, as a result, that slows the Hive Queries. Hence, to speed up the Hive queries, we can use Map Join in Hive.
Also, we use Hive Map Side Join since one of the tables in the join is a small table and can be loaded into memory. So that a join could be performed within a mapper without using a Map/Reduce step.
Working of Map Side Join in Hive
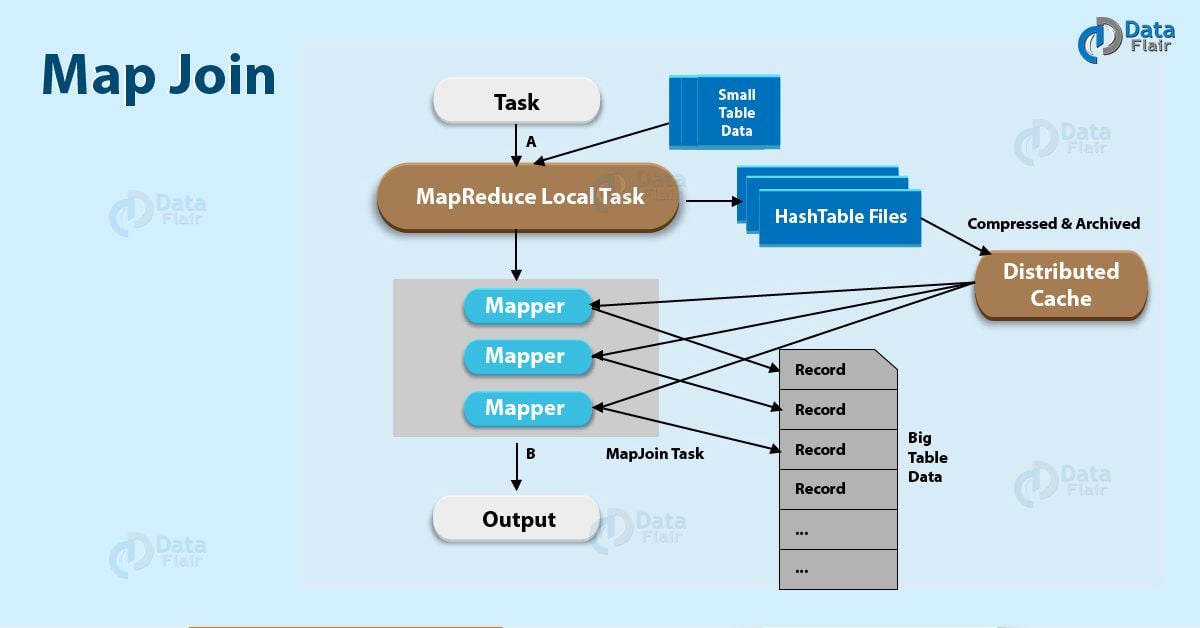
Although even if queries frequently depend on small table joins, usage of map joins speed up queries’ execution. Moreover, it is the type of join where a smaller table is loaded into memory and the join is done in the map phase of the MapReduce job.
Basically, before the original MapReduce task, its first step is to create a MapReduce local task. However, from HDFS this map/reduce task read data of the small table. Further save it into an in-memory hash table, then into a hash table file.
Afterward, it moves the hash table file to the Hadoop Distributed Cache while original join MapReduce task starts, which will populate the file to each mapper’s local disk. Hence, in this way, all the mapper can load this hash table file into the memory and then do the join in Map stage.
So, let’s understand this with an example. let’s suppose, for a join with big table A and small table B, for every mapper for table A, Table B is read completely. Since the smaller table is loaded into memory at first.
Afterward, join is performed in the map phase of the MapReduce job, no reducer is needed and reduce phase is skipped. However, map joins in Hive are way faster than the regular joins since no reducers are necessary.
Parameters of Hive Map Side Join
Moreover, let’s discuss the Hive map side join options below:
a. hive.auto.convert.join
However, this option set true, by default. Moreover, when a table with a size less than 25 MB (hive.mapjoin.smalltable.filesize) is found, When it is enabled, during joins, the joins are converted to map-based joins.
b. Hive.auto.convert.join.noconditionaltask
When there comes a scenario while three or more tables involve in the join condition. Further, Hive generates three or more map-side joins with an assumption that all tables are of smaller size by using hive.auto.convert.join.
Moreover, we can combine three or more map-side joins into a single map-side join if the size of the n-1 table is less than 10 MB using hive.auto.convert.join.noconditionaltask. Basically, this rule define by hive.auto.convert.join.noconditionaltask.size.
Limitations of Map Join in Hive
Below are some limitations of Map Side join in Hive:
- First, the major restriction is, we can never convert Full outer joins to map-side joins.
- However, it is possible to convert a left-outer join to a map-side join in the Hive. However, only possible since the right table that is to the right side of the join conditions, is lesser than 25 MB in size.
- Also, we can convert a right-outer join to a map-side join in the Hive. Similarly, only possible if the left table size is lesser than 25 MB.
How to Identify Hive Map Join?
Basically, we will see Hive Map Side Join Operator just below Map Operator Tree while using EXPLAIN command.
Other
Although, we can use the hint to specify the query using Map Join in Hive. Hence, below an example shows that smaller table is the one put in the hint, and force to cache table B manually.
Select /*+ MAPJOIN(b) */ a.key, a.value from a join b on a.key = b.key
For Example,
hive> set hive.auto.convert.join=true; hive> set hive.auto.convert.join.noconditionaltask=true; hive> set hive.auto.convert.join.noconditionaltask.size=20971520 hive> set hive.auto.convert.join.use.nonstaged=true; hive> set hive.mapjoin.smalltable.filesize = 30000000;
Map Join in Hive Example
While passwords table is huge here, and the passwords3 table is a very small table.
For example,
hive> explain select a.* from passwords a,passwords3 b where a.col0=b.col0;
OK
STAGE DEPENDENCIES:
Stage-4 is a root stage
Stage-3 depends on stages: Stage-4
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-4
Map Reduce Local Work
Alias -> Map Local Tables:
b
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
b
TableScan
alias: b
Statistics: Num rows: 1 Data size: 31 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
condition expressions:
0 {col0} {col1} {col2} {col3} {col4} {col5} {col6}
1 {col0}
keys:
0 col0 (type: string)
1 col0 (type: string)
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: a
Statistics: Num rows: 9963904 Data size: 477218560 Basic stats: COMPLETE Column stats: NONE
Map Join Operator
condition map:
Inner Join 0 to 1
condition expressions:
0 {col0} {col1} {col2} {col3} {col4} {col5} {col6}
1 {col0}
keys:
0 col0 (type: string)
1 col0 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col9
Statistics: Num rows: 10960295 Data size: 524940416 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (_col0 = _col9) (type: boolean)
Statistics: Num rows: 5480147 Data size: 262470184 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: string), _col1 (type: string), _col2 (type: string), _col3 (type: string), _col4 (type: string), _col5 (type: string), _col6 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6
Statistics: Num rows: 5480147 Data size: 262470184 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 5480147 Data size: 262470184 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Local Work:
Map Reduce Local Work
Stage: Stage-0
Fetch Operator
limit: -1Time taken: 0.1 seconds, Fetched: 63 row(s)
Tips on Map Join in Hive
i. At first, auto convert shuffle/common join to map join.
However, we have 3 parameters are related:
set hive.auto.convert.join=true;
set hive.auto.convert.join.noconditionaltask=true;
set hive.auto.convert.join.noconditionaltask.size=10000000;
- At frist, by default, it is starting from Hive 0.11, hive.auto.convert.join=true.
- Moreover, by setting hive.auto.convert.join=false we can disable this feature.
- However, common join can convert to map join automatically, when hive.auto.convert.join.noconditionaltask=true, if estimated size of small table(s) is smaller than hive.auto.convert.join.noconditionaltask.size(default 10MB).
- Also, according to statistics we know estimated “Table b’s Data Size=31”, from above SQL plan output.
- Moreover, if “set hive.auto.convert.join.noconditionaltask.size = 32;”, the explain output shows map join operator:
Map Join Operator - Further, if “set hive.auto.convert.join.noconditionaltask.size = 31;”, then the join becomes common join operator:
Join Operator.
ii. Second, to force to use the map join we can use “MAPJOIN”.
At first, make sure below parameter is set to false(Default is true in Hive 0.13).
set hive.ignore.mapjoin.hint=false;
Then:
select /*+ MAPJOIN(a) */ a.* from passwords a, passwords2 b where a.col0=b.col0 ;
Conclusion
Hence we have the whole concept of Map Join in Hive. However, it includes parameter and Limitations of Map side Join in Hive. Moreover, we have seen the Map Join in Hive example also to understand it well.
In the next article, we will see Bucket Map Join in Hive and Skew Join in Hive. Furthermore, if You have any query, feel free to ask in the comment section.
We work very hard to provide you quality material
Could you take 15 seconds and share your happy experience on Google





is there any way i can join two large tables (> 10 GB ) optimally? (no bucketing)
If i have two tables of size 2 GB and 50 GB respectively, how can we join these two tables?
Please advise
use map side join where 50 gb will be treated as left table while smaller one as right
Hello, does it mean that you can have table with size more than 25MB for map join usage? If yes, does this mean that I need to set manually limit?
Yes