Apache Hive Installation – Install Hive on Ubuntu in 5 Minutes
This DataFlair article provides a complete package to Install Hive on Ubuntu along with the screenshots.
Hive is a data warehousing infrastructure tool built on the top of Hadoop. This article helps you to start quickly with the Hive by providing guidance about downloading Hive, setting and configuring Hive and launching HiveServer2, and the Beeline Command shell to interact with Hive.
This article enlists the steps to be followed for Hive 3.1.2 installation on Hadoop 3.1.2 on Ubuntu.
What is Apache Hive?
Apache Hive is a warehouse infrastructure designed on top of Hadoop for providing information summarization, query, and ad-hoc analysis. Hence, in order to get your Hive running successfully, Java and Hadoop ought to be pre-installed and should be functioning well on your Linux OS.
Before installing the Hive, we require dedicated Hadoop installation, up and running with all the Hadoop daemons.
So, let’s start the Apache Hive Installation Tutorial.
Apache Hive Installation on Ubuntu
Now in order to get Apache Hive installation successfully on your Ubuntu system, please follow the below steps and execute them on your Linux OS.
Here are the steps to be followed for installing Hive 3.1.2 on Ubuntu.
1. Download Hive
Step 1: First, download the Hive 3.1.2 from this link.
Step 2: Locate the apache-hive-3.1.2-bin.tar.gz file in your system.
Step 3: Extract this tar file using the below command:
tar -xzf apache-hive-3.1.2-bin.tar.gz

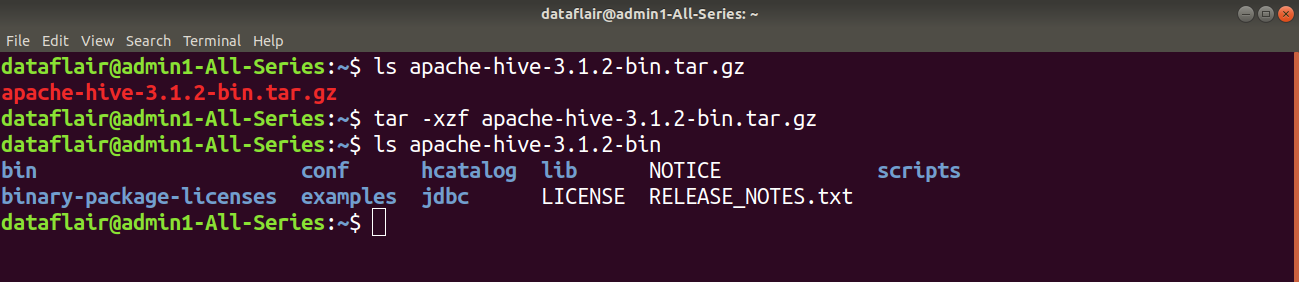
2. Configuring Hive files
Step 4: Now, we have to place the Hive PATH in .bashrc file. For this, open .bashrc file in the nano editor and add the following in the .bashrc file.
export HIVE_HOME= “home/dataflair/apache-hive-3.1.2-bin” export PATH=$PATH:$HIVE_HOME/bin

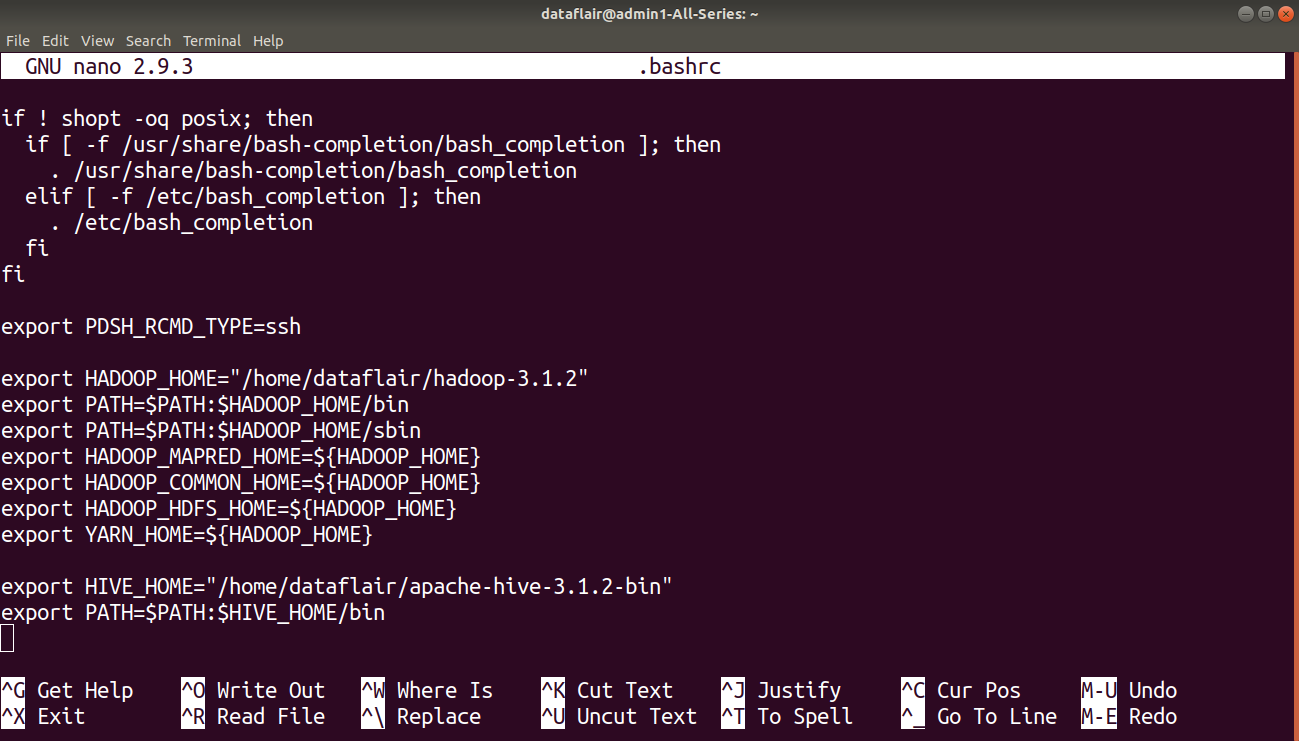
Note: Here enter the correct name & version of your hive and correct path of your Hive File “home/dataflair/apache-hive-3.1.2-bin” this is the path of my Hive File and “apache-hive-3.1.2-bin” is the name of my hive file.
So please enter the correct path and name of your Hive file. After adding save this file.
Press CTRL+O and enter to save changes. Then press CTRL+D to exit the editor.
Step 5: Open the core-site.xml file in the nano editor. The file is located in home/hadoop-3.1.2/etc/hadoop/ (Hadoop Configuration Directory).
Add the following configuration property in the core-site.xml file.
<configuration> <property> <name>hadoop.proxyuser.dataflair.groups</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.dataflair.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.server.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.server.groups</name> <value>*</value> </property> </configuration>

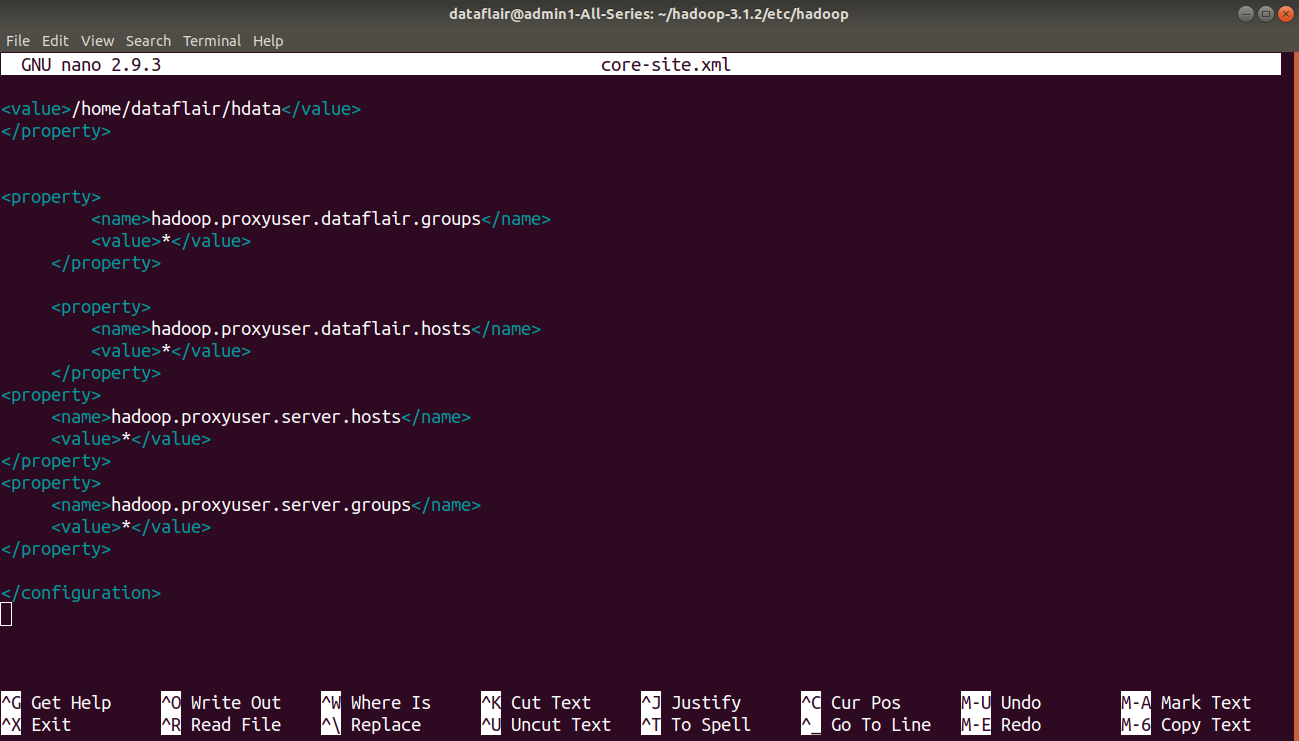
Press CTRL+O and enter to save changes. Then press CTRL+D to exit the editor.
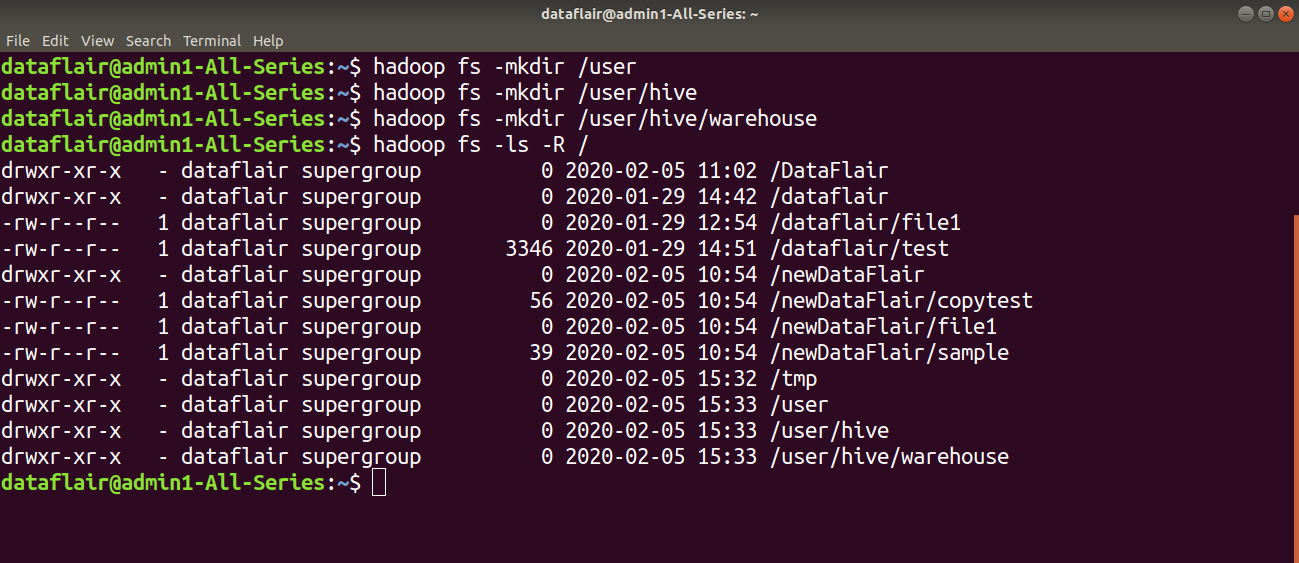
Step 6: Make a directory ‘tmp’ in HDFS using the below command:
hadoop fs -mkdir /tmp

Step 6: Use the below commands to create a directory ‘warehouse’ inside ‘hive’ directory, which resides in ‘user’ directory. The warehouse is the location to store data or tables related to Hive.
hadoop fs -mkdir /user hadoop fs -mkdir /user/hive hadoop fs -mkdir /user/hive/warehouse

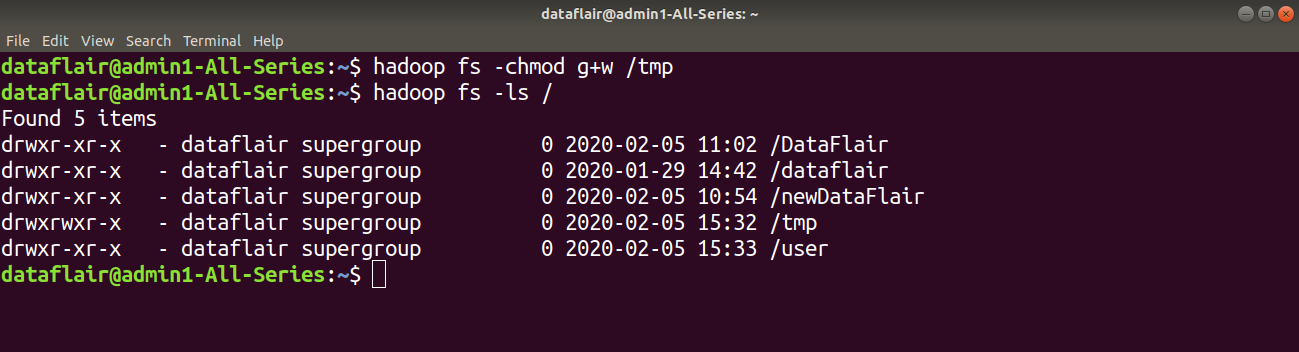
Step 7: Give the write permission to the members of the ‘tmp’ file group using command:
hadoop fs -chmod g+w /tmp

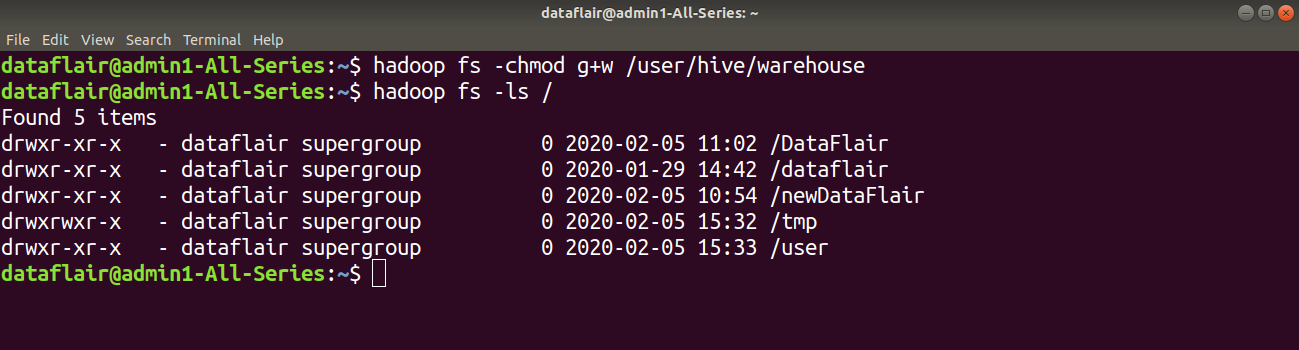
Step 8: Now give write permission to the warehouse directory using the command:
hadoop fs -chmod g+w /user/hive/warehouse

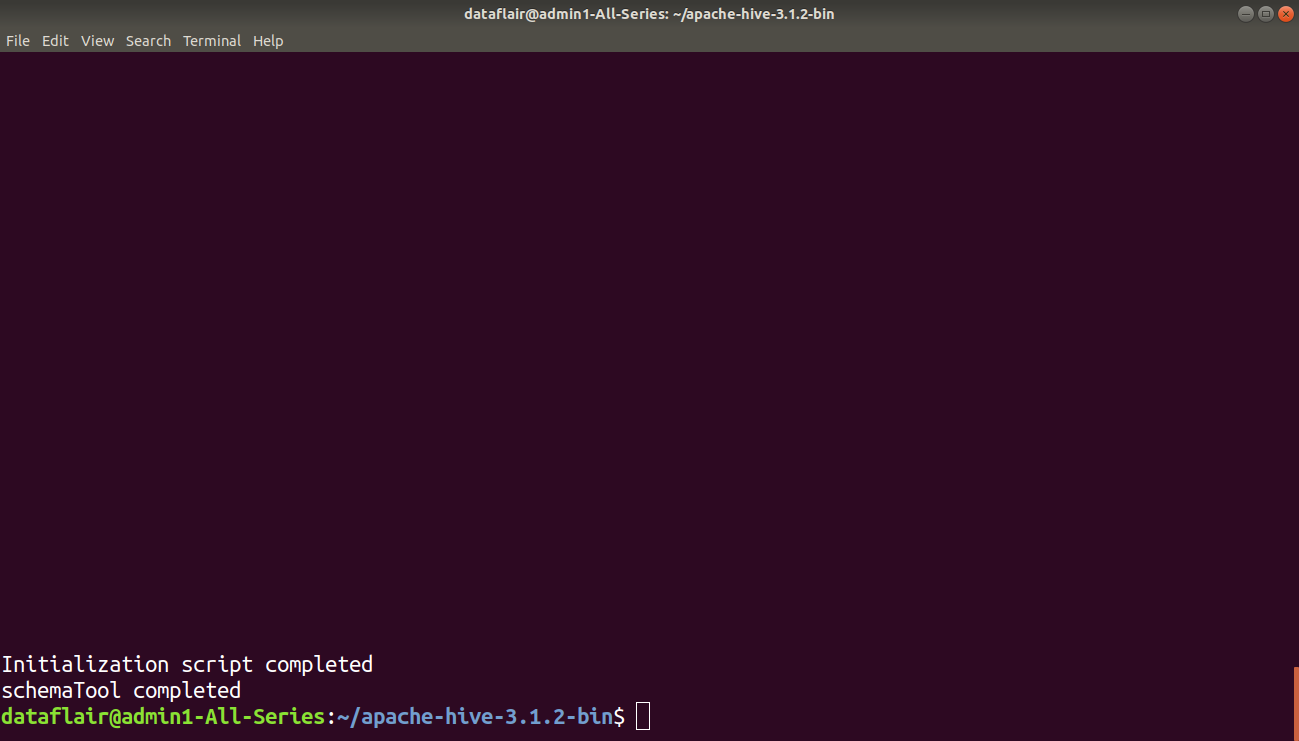
3. Initialize Derby database
Step 9: Hive by default uses Derby database. Use the below command to initialize the Derby database.
bin/schematool -dbType derby -initSchema

4. Launching Hive
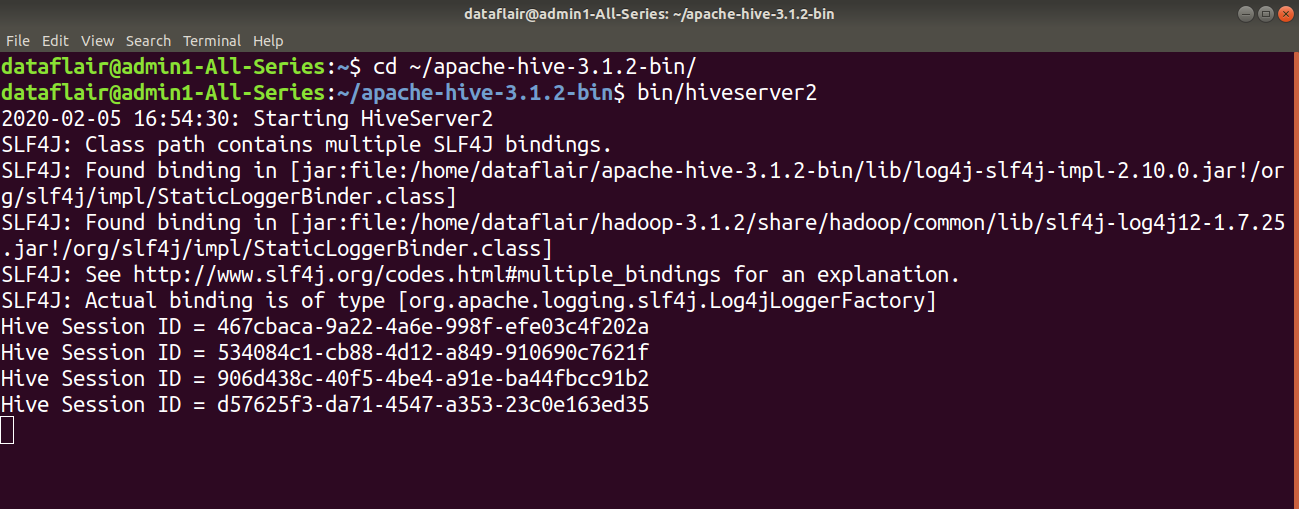
Step 10: Now start the HiveServer2 using the below command:
bin/hiveserver2
[For this first move to the ~/apache-hive-3.1.2-bin/]

Step 11: On the different tab, type the below command to launch the beeline command shell.
bin/beeline -n dataflair -u jdbc:hive2://localhost:10000

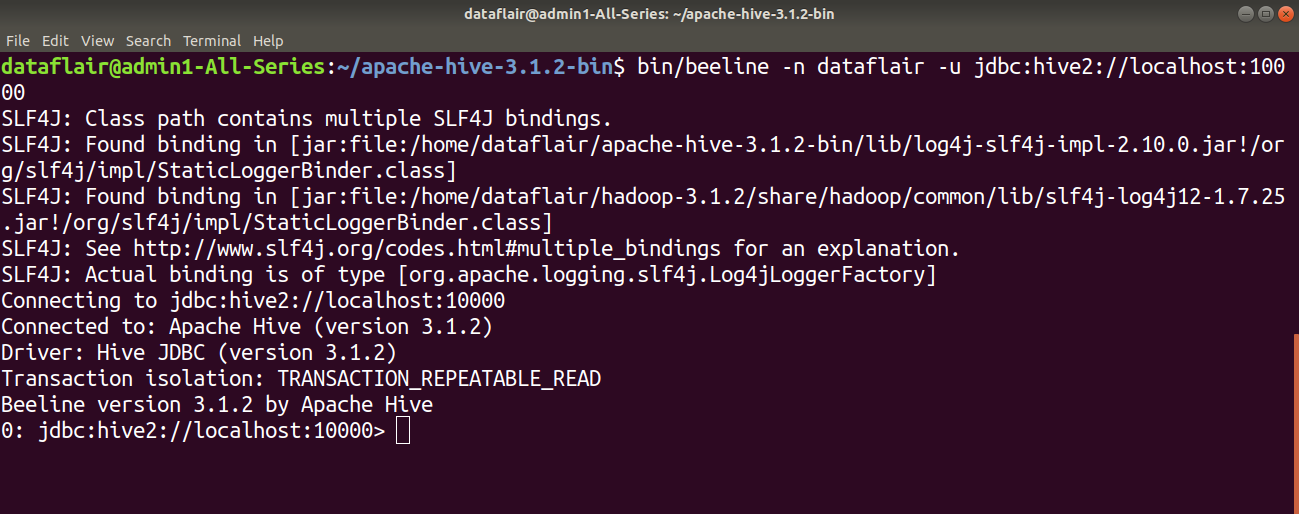
Congratulations!! We have successfully installed Hive 3.1.2 on Ubuntu.
Now, you can type SQL queries in the Beeline command shell to interact with the Hive system.
5. Verifying Hive Installation
For example, in the below image, I am using show databases query to list out the database in the Hive warehouse.
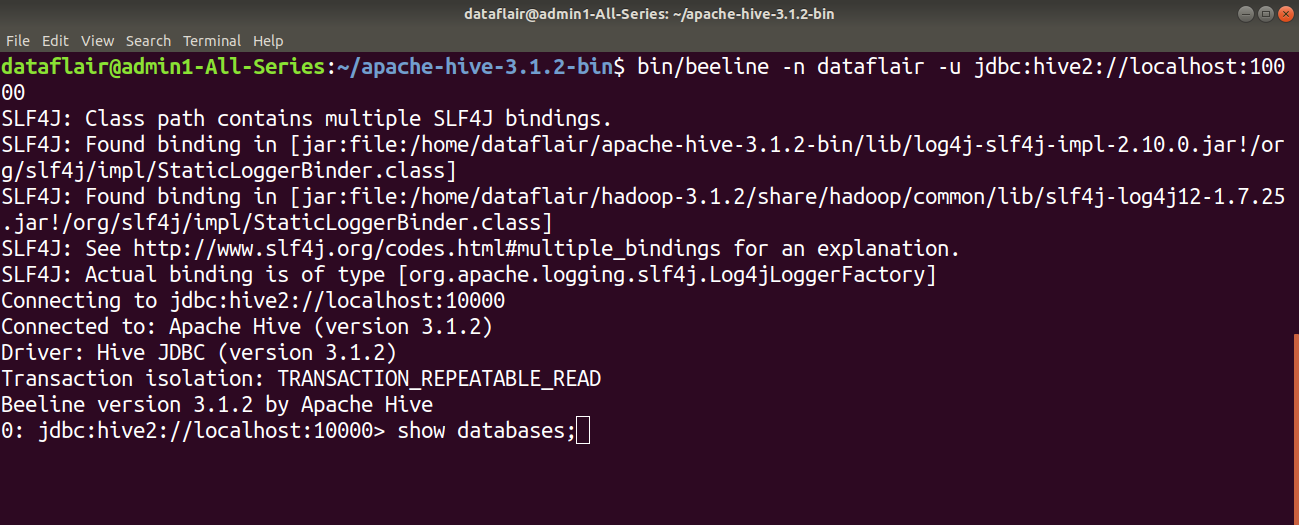
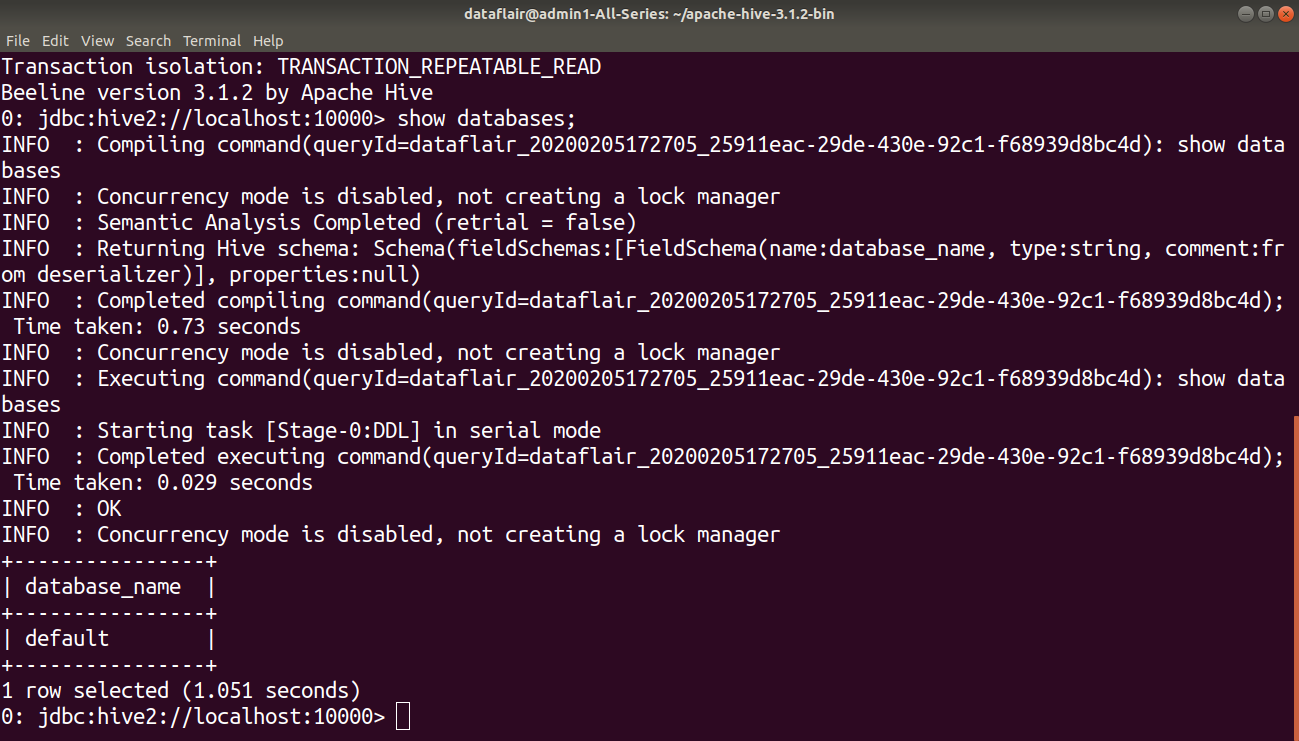
We have successfully installed Apache Hive 3.1.2 on Hadoop 3.1.2 on Ubuntu.
Conclusion
Hence, in this Hive installation tutorial, we discussed the process to install Hive on Ubuntu.
Hive installation Done? Now, master Hive from our article in the left sidebar.
Still, if you have any confusion related to Hive Installation, ask in the comment tab.
Keep Learning!!
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google





Normally I don’t learn article on blogs, but I
would like to say that this write-up very forced me to try and do so!
Your writing taste has been amazed me. Thanks, quite nice article.
Hi,
It is the honest feedback on “Apache HIve Installation” from readers like you that keeps us striving to be better than we were yesterday.
We are glad we could do our part to change your mind about written material.
Regard,
Data-Flair
Hi, the hive download link is broken.
Hi Sanjay,
Thanks for Commenting on “Apache Hive Installation”. We reviewed the link, it seems fine. Check your Internet connectivity or try opening it on a different device, still you face any problem do let us know.
Regards,
Data-Flair
what does ad-hoc analysis mean ?
Thanks in advance!!
Thanks,
Santhosh.
Hi, the Hive download link is not working
hive download link is not working
There is a problem occurring at step 9, when initializing the derby database.
Please Help
schematool -dbType derby -initSchema
If you get Exception Error
Exception in thread “main” java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
Solution :
$ rm home/hadoop/apache-hive-3.1.2-bin/lib/guava-19.0.jar
$ cp hadoop/share/hadoop/hdfs/lib/guava-27.0-jre.jar /home/hadoop/apache-hive-3.1.2-bin/lib
Hi All,
Need help in resolving below issue.
I have installed Ubuntu as Windows subsystem on Windows 10.
Installed Hadoop 3.1.3 and Hive 3.1.2
When I am running normal query without MapReduce its running fine.
hive> use bhudwh;
OK
Time taken: 1.075 seconds
hive> select id from matches where id
When running MapReduce query, it throws error – Error: Could not find or load main class 1600.
hive> select distinct id from matches;
Query ID = bhush_20200529144705_62bc4f10-1604-453f-a90c-ed905c9c1fe9
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Starting Job = job_1590670326852_0003, Tracking URL = DESKTOP-EU9VK4S.localdomain:8088/proxy/application_1590670326852_0003/
Kill Command = /mnt/e/Study/Hadoop/hadoop-3.1.3/bin/mapred job -kill job_1590670326852_0003
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2020-05-29 14:47:24,644 Stage-1 map = 0%, reduce = 0%
2020-05-29 14:47:41,549 Stage-1 map = 100%, reduce = 100%
Ended Job = job_1590670326852_0003 with errors
Error during job, obtaining debugging information…
Examining task ID: task_1590670326852_0003_m_000000 (and more) from job job_1590670326852_0003
Task with the most failures(4):
—–
Task ID:
task_1590670326852_0003_m_000000
URL:
0.0.0.0:8088/taskdetails.jsp?jobid=job_1590670326852_0003&tipid=task_1590670326852_0003_m_000000
—–
Diagnostic Messages for this Task:
[2020-05-29 14:47:40.355]Exception from container-launch.
Container id: container_1590670326852_0003_01_000005
Exit code: 1
[2020-05-29 14:47:40.360]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class 1600
[2020-05-29 14:47:40.361]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class 1600
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 HDFS Read: 0 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 0 msec
hive>
Below are few lines from Hadoop logs.
2020-05-29 14:47:28,262 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Reduce slow start threshold not met. completedMapsForReduceSlowstart 1
2020-05-29 14:47:28,262 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: Diagnostics report from attempt_1590670326852_0003_m_000000_0: [2020-05-29 14:47:27.559]Exception from container-launch.
Container id: container_1590670326852_0003_01_000002
Exit code: 1
[2020-05-29 14:47:27.565]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class 1600
[2020-05-29 14:47:27.566]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class 1600
I have tried all the configuration changes suggested in different threads but its not working.
I have also checked Hadoop MapReduce example of **WordCount** and it also fails with same error.
All Hadoop processes seems running fine. Output of **jps** command.
9473 NodeManager
11798 Jps
9096 ResourceManager
8554 DataNode
8331 NameNode
8827 SecondaryNameNode
Please suggest how to resolve this error.
From the given stacktrace we can’t identify the root cause of issue, please post complete stacktrace of MapReduce Job execution, which gives complete error details
i had installed hive 3.1.2 on hadoop 2.7.3 everthing goes right , but when i type hive command from shell then it goes to hive script mode show database then i get error:
0: jdbc:hive2://localhost:10000> show databases;
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+—————-+
| database_name |
+—————-+
| db001 |
| default |
| game |
+—————-+
3 rows selected (1.515 seconds)
hive> show databases;
FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
hive>
I think Hive 3.1.2 is not compatible with Hadoop 2.7.3, you should use Hadoop 3.1.2.
I hope you have setup hive_home, Java_home and path variables correctly in .bashrc. If you have changed metastore from derby to MySQL, please provide all the config params in hive-site.xml and add MySQL conenctor jar
Hi thank you for this good and update post. I followed you but when I tried to run
schematool -dbType derby -initSchema
I got following error
Exception in thread “main” java.lang.RuntimeException: com.ctc.wstx.exc.WstxParsingException: Illegal character entity: expansion character (code 0x8
at [row,col,system-id]: [3215,96,”file:/home/train/apache-hive-3.1.2-bin/conf/hive-site.xml”]
at org.apache.hadoop.conf.Configuration.loadResource(Configuration.java:2981)
at org.apache.hadoop.conf.Configuration.loadResources(Configuration.java:2930)
at org.apache.hadoop.conf.Configuration.getProps(Configuration.java:2805)
at org.apache.hadoop.conf.Configuration.get(Configuration.java:1459)
at org.apache.hadoop.hive.conf.HiveConf.getVar(HiveConf.java:4996)
at org.apache.hadoop.hive.conf.HiveConf.getVar(HiveConf.java:5069)
at org.apache.hadoop.hive.conf.HiveConf.initialize(HiveConf.java:5156)
at org.apache.hadoop.hive.conf.HiveConf.(HiveConf.java:5104)
at org.apache.hive.beeline.HiveSchemaTool.(HiveSchemaTool.java:96)
at org.apache.hive.beeline.HiveSchemaTool.main(HiveSchemaTool.java:1473)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:318)
at org.apache.hadoop.util.RunJar.main(RunJar.java:232)
Caused by: com.ctc.wstx.exc.WstxParsingException: Illegal character entity: expansion character (code 0x8
at [row,col,system-id]: [3215,96,”file:/home/train/apache-hive-3.1.2-bin/conf/hive-site.xml”]
at com.ctc.wstx.sr.StreamScanner.constructWfcException(StreamScanner.java:621)
at com.ctc.wstx.sr.StreamScanner.throwParseError(StreamScanner.java:491)
at com.ctc.wstx.sr.StreamScanner.reportIllegalChar(StreamScanner.java:2456)
at com.ctc.wstx.sr.StreamScanner.validateChar(StreamScanner.java:2403)
at com.ctc.wstx.sr.StreamScanner.resolveCharEnt(StreamScanner.java:2369)
at com.ctc.wstx.sr.StreamScanner.fullyResolveEntity(StreamScanner.java:1515)
at com.ctc.wstx.sr.BasicStreamReader.nextFromTree(BasicStreamReader.java:2828)
at com.ctc.wstx.sr.BasicStreamReader.next(BasicStreamReader.java:1123)
at org.apache.hadoop.conf.Configuration$Parser.parseNext(Configuration.java:3277)
at org.apache.hadoop.conf.Configuration$Parser.parse(Configuration.java:3071)
at org.apache.hadoop.conf.Configuration.loadResource(Configuration.java:2964)
… 15 more
There was a bad character in hive-site.xml I corrected it (actually deleted because it was in description).
In step 6, when I typed “hadoop fs -mkdir /tmp” on the command line, it said “hadoop: command not found”.
Is is because I need to run the command at a specific directory?
Thanks
In have installed but when I tring to start with this command it’s not starting.
bin/beeline -n gajanand -u jdbc:hive2://localhost:10000
bin/beeline -n gajanand -u jdbc:hive2://localhost:10002
hive.server2.webui.host
localhost
The host address the HiveServer2 WebUI will listen on
hive.server2.webui.port
10002
Hi ,
while trying to execute the beeline command , i am getting this below issue.PLease help on the below issue
chottu@chottu-virtual-machine:~/Desktop/learning/apache-hive-3.1.2-bin$ bin/beeline -n dataflair -u jdbc:hive2://localhost:10000
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/chottu/Desktop/learning/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/chottu/Desktop/learning/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Connecting to jdbc:hive2://localhost:10000
21/12/17 23:29:17 [main]: WARN jdbc.HiveConnection: Failed to connect to localhost:10000
Error: Could not open client transport with JDBC Uri: jdbc:hive2://localhost:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: chottu is not allowed to impersonate dataflair (state=08S01,code=0)
Beeline version 3.1.2 by Apache Hive
When I am opening new tab and typing last command, I am getting a java error and the program stopped