Apache Hive Features | Limitations of Hive
As we know to process structured data in Hadoop, we use Hive. Apart from it, there are several features of Apache Hive. well, it also has several limitations.
So, in this Hive Tutorial, we will see “Apache Hive features and limitations of Hive”, we will discuss both features and limitations of Hive. But, before that, we will also learn the introduction of Hive.
What is Apache Hive?
Basically, the tool to process structured data in Hadoop we use Hive. It is a data warehouse infrastructure. Moreover, to summarize Big Data, it resides on top of Hadoop. Also, makes querying and analyzing easy.
However, the Apache Software Foundation took it up, but initially, Hive was developed by Facebook. Further Apache Software Foundation developed it as an open-source under the name Apache Hive. Although, many different companies use it. Like, Amazon uses it in Amazon Elastic MapReduce.
Apache Hive Features and Limitations
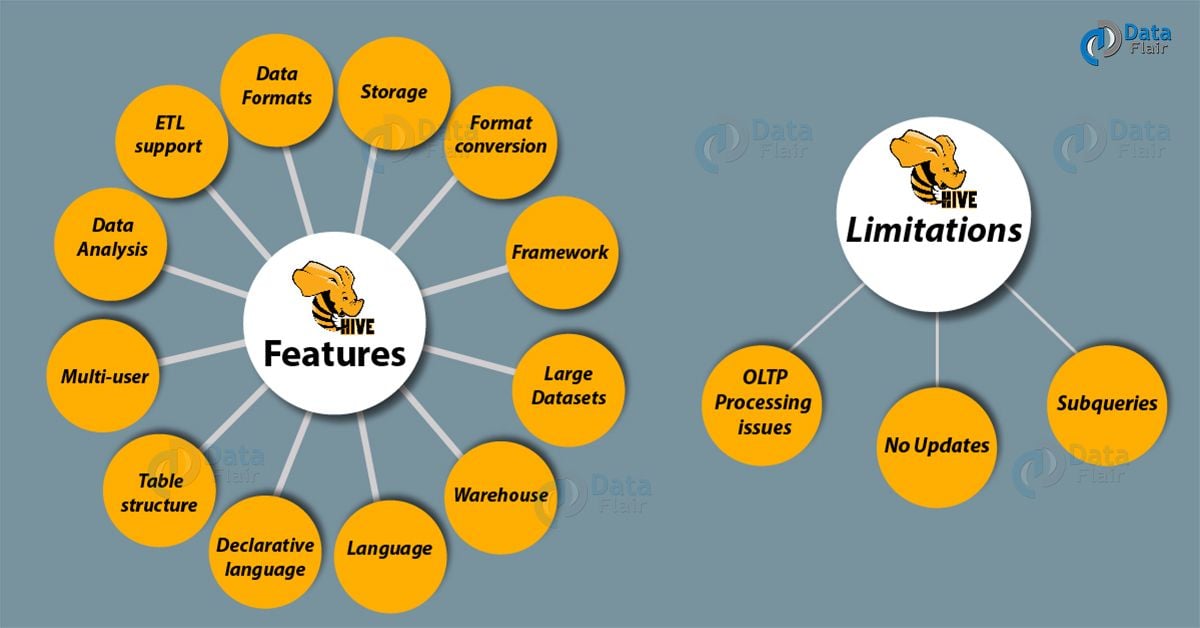
Apache Hive Features | Limitations of Hive
a. Hive Features
Some Hive new features are discussed below:
i. Framework
Apache Hive is built on top of Hadoop distributed framework system (HDFS).
ii. Large datasets
However, in distributed storage, it helps to query large datasets residing.
iii. Warehouse
Also, we can say Hive is a distributed data warehouse.
iv. Language
Queries data using a SQL-like language called HiveQL (HQL).
v. Declarative language
HiveQL is a declarative language like SQL.
vi. Table structure
Table structure/s is/are similar to tables in a relational database.
vii. Multi-user
Multiple users can simultaneously query the data using Hive-QL.
viii. Data Analysis
However, to perform more detailed data analysis, Hive allows writing custom MapReduce framework processes.
ix. ETL support
Also, it is possible to extract/transform/load (ETL) Data easily.
x. Data Formats
Moreover, Hive offers the structure on a variety of data formats.
xi. Storage
Hive allows access files stored in HDFS. Also, similar others data storage systems such as Apache HBase.
x. Format conversion
Moreover, it allows converting the variety of format from to within Hive. Although, it is very simple and possible.
b. Limitations of Hive
i. OLTP Processing issues
However, Hive is not designed for Online transaction processing (OLTP). Although, we can use it for the Online Analytical Processing (OLAP).
ii. No Updates
It does not support updates and deletes, however, it does support overwriting or apprehending data.
iii. Subqueries
Basically, in Hive, Subqueries are not supported.
So, this was all in Features of Hive. Hope you like our explanation.
Conclusion
Hence, we have seen all the Hive features and limitations of Hive. Still, if any query occurs feel free to ask in the comment section.
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google





please clear me meaning of ‘HIVE does support overwriting or apprehending data’
Hii Ved Prakash,
Thank you for asking the query, here is the solution for you –
Hive supports Overwriting and Apprehending. Here Apprehending means insert the incremental data through queries into the target, For example, INSERT INTO query will append data to the table or partition, keeping the existing data intact. Whereas the keyword ‘OVERWRITE’ signifies that if the OVERWRITE keyword is used when the contents of the target table (or partition) will be deleted and replaced by the new files. For doing so, we use INSERT OVERWRITE query, it overwrites any existing data in the table or partition.
Hope our this explanation helps you.
Best. Very detailed, concise and repeatative of important lines, like a reminder
Thanks for the feedback. If you liked the article, share our Hadoop tutorial series with your friends and colleagues on social media.
Thanks for the article. But I have doubt.
How can multiple users can simultaneously query in HIVE