Bucket Map Join in Hive – Tips & Working
In the last article, we discuss Map Side Join in Hive. Basically, while the tables are large and all the tables used in the join are bucketed on the join columns we use a Bucket Map Join in Hive.
In this article, we will cover the whole concept of Apache Hive Bucket Map Join. It also includes use cases, disadvantages, and Bucket Map Join example which will enhance our knowledge.
Introduction to Bucket Map Join
In Apache Hive, while the tables are large and all the tables used in the join are bucketed on the join columns we use Hive Bucket Map Join feature. Moreover, one table should have buckets in multiples of the number of buckets in another table in this type of join.
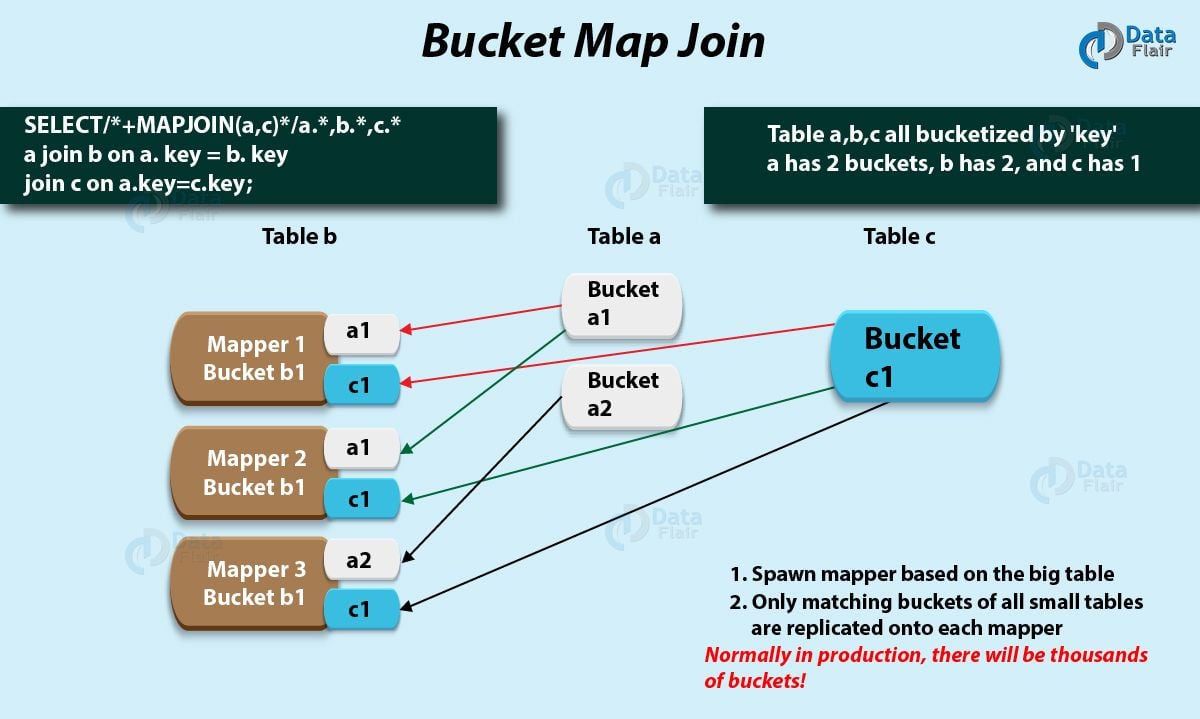
How Bucket Map Join Works
Let’s understand with an example. For suppose if one table has 2 buckets then the other table must have either 2 buckets or a multiple of 2 buckets (2, 4, 6, and so on). Further, since the preceding condition is satisfied then the joining can be done on the mapper side only.
Else a normal inner join is performed. Therefore, it implies that only the required buckets are fetched on the mapper side and not the complete table.
Hence, onto each mapper, only the matching buckets of all small tables are replicated. As a result of this, the efficiency of the query improves drastically. However, make sure data does not sort in a bucket map join.
Also, note that by default Hive does not support a bucket map join. So, we need to set the following property to true for the query to work as this join:
set hive.optimize.bucketmapjoin = true
How does it work in Hive?
Basically, Join is done in Mapper only. However, let’s understand it in this way, the mapper processing bucket 1 for table A will only fetch bucket 1 of table B.
Use Case of Bucket Map Join
To be more specific we use this feature with several scenarios. Like:
i. While all the tables are large.
ii. Also, while all tables bucketed using the join columns.
iii. Moreover, while the number of buckets in one table is a multiple of the number of buckets in the other table.
iii. Also, when all the tables do not sort.
Disadvantages of Bucket Map Join in Hive
The major disadvantage of using Bucket Map Join is, here tables need to be bucketed in the same way how the SQL joins. That implies we can not use it for other types of SQLs.
Tips on Bucket Map Join
i. At first, it is very important that the tables are created bucketed on the same join columns. Also, it is important to bucket data while inserting.
However, one of the ways is to set “hive.enforce.bucketing=true” before inserting data.
For example:
create table b1(col0 string,col1 string,col2 string,col3 string,col4 string,col5 string,col6 string)
clustered by (col0) into 32 buckets;
create table b2(col0 string,col1 string,col2 string,col3 string,col4 string,col5 string,col6 string)
clustered by (col0) into 8 buckets;
set hive.enforce.bucketing = true;
From passwords insert OVERWRITE table b1 select * limit 10000;
From passwords insert OVERWRITE table b2 select * limit 10000;
ii. Also, it is must to set hive.optimize.bucketmapjoin to true.
set hive.optimize.bucketmapjoin=true;
select /*+ MAPJOIN(b2) */ b1.* from b1,b2 where b1.col0=b2.col0;
Conclusion
As a result, we have seen the complete content regarding Apache Hive Bucket Map Join feature, Bucket Map Join example, use cases, Working, and Disadvantages of Bucket Map Join. In next article, we will see Skew Join in Hive. Although, if any query arises, please ask in a comment section.
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google





Very well explained
Thank You, Amit for commenting on “Bucket Map Join in Hive”. We hope this Apache Hive Tutorial, helps you to solve your queries.
Check out more Hive Tutorials to learn Hive.
Regards,
Data-Flair
Hi. Can you explain the scenario where my record for B table is in the 2nd bucket and the corresponding join id are present in the 1st bucket of table A and C?
As mentioned above an only matching bucket of all small tables are replicated on the mapper. How it will be done?