Hive Partitioning vs Bucketing – Advantages and Disadvantages
In our previous Hive tutorial, we have discussed Hive Data Models in detail. In this tutorial, we are going to cover the feature wise difference between Hive partitioning vs bucketing.
This blog also covers Hive Partitioning example, Hive Bucketing example, Advantages and Disadvantages of Hive Partitioning and Bucketing.
So, let’s start Hive Partitioning vs Bucketing.
What is Hive Partitioning and Bucketing?
Apache Hive is an open source data warehouse system used for querying and analyzing large datasets. Data in Apache Hive can be categorized into Table, Partition, and Bucket. The table in Hive is logically made up of the data being stored.
It is of two type such as an internal table and external table. Refer this guide to learn what is Internal table and External Tables and the difference between both. Let us now discuss the Partitioning and Bucketing in Hive in detail-
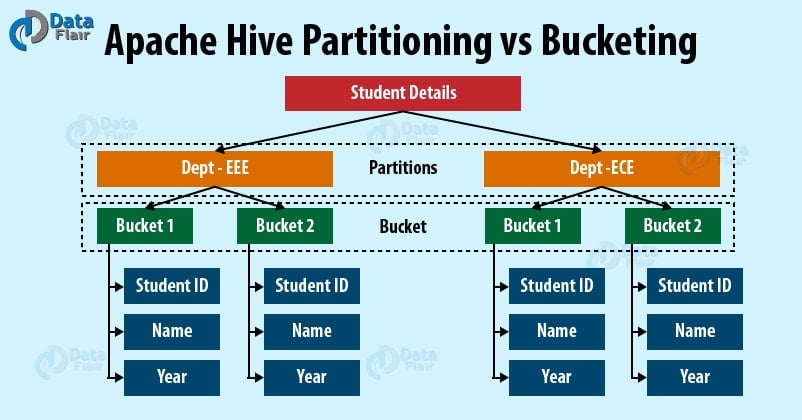
Hive partitioning vs Bucketing
- Partitioning – Apache Hive organizes tables into partitions for grouping same type of data together based on a column or partition key. Each table in the hive can have one or more partition keys to identify a particular partition. Using partition we can make it faster to do queries on slices of the data.
- Bucketing – In Hive Tables or partition are subdivided into buckets based on the hash function of a column in the table to give extra structure to the data that may be used for more efficient queries.
Comparison between Hive Partitioning vs Bucketing
We have taken a brief look at what is Hive Partitioning and what is Hive Bucketing. You can refer our previous blog on Hive Data Models for the detailed study of Bucketing and Partitioning in Apache Hive.
In this section, we will discuss the difference between Hive Partitioning and Bucketing on the basis of different features in detail-
i. Partitioning and Bucketing Commands in Hive
a) Partitioning
The Hive command for Partitioning is:
[php]CREATE TABLE table_name (column1 data_type, column2 data_type) PARTITIONED BY (partition1 data_type, partition2 data_type,….);[/php]
b) Bucketing
The Hive command for Bucketing is:
[php]CREATE TABLE table_name PARTITIONED BY (partition1 data_type, partition2 data_type,….) CLUSTERED BY (column_name1, column_name2, …) SORTED BY (column_name [ASC|DESC], …)] INTO num_buckets BUCKETS;[/php]
ii. Apache Hive Partitioning and Bucketing Example
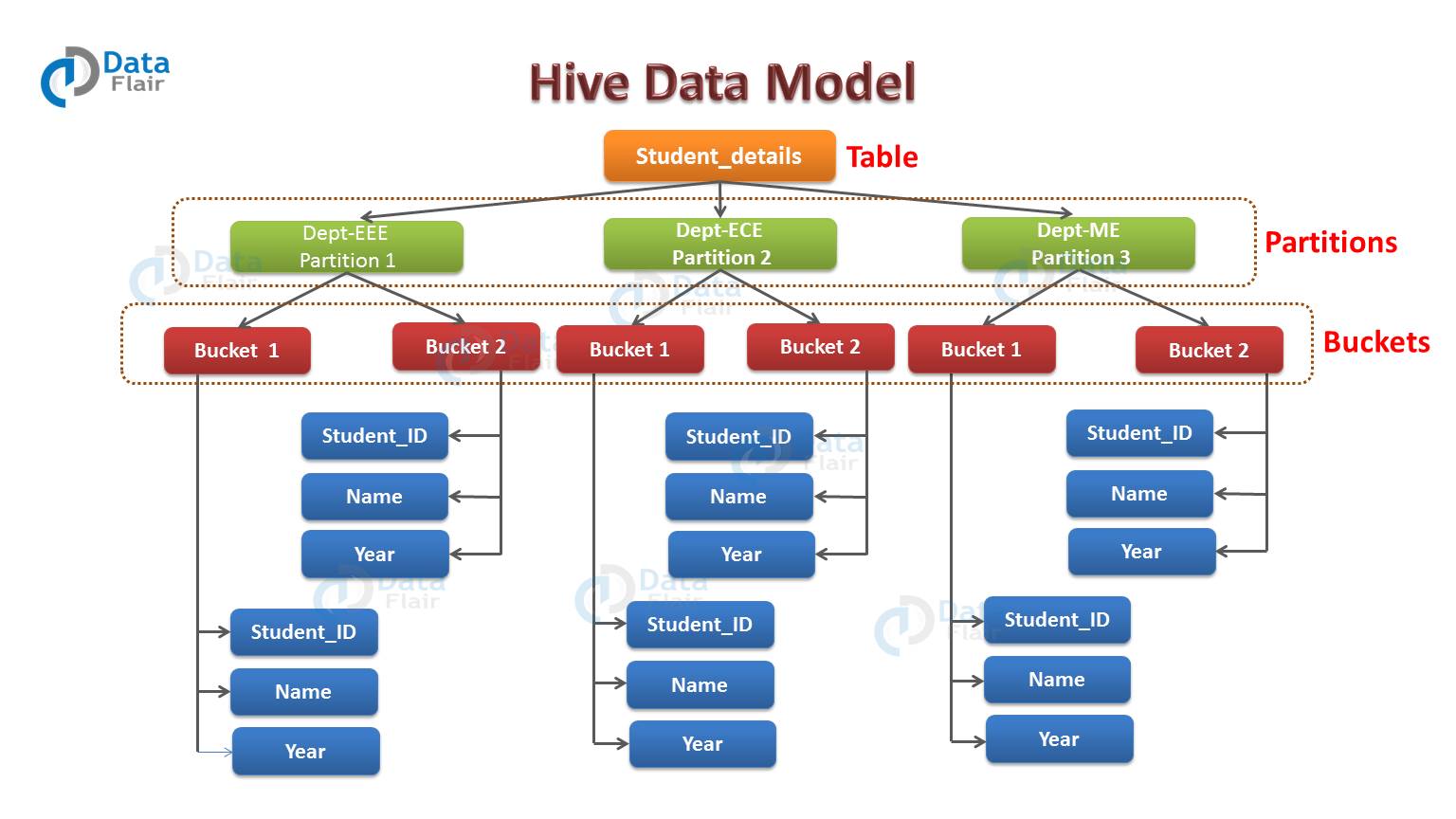
Hive Data Model
a) Hive Partitioning Example
For example, we have a table employee_details containing the employee information of some company like employee_id, name, department, year, etc. Now, if we want to perform partitioning on the basis of department column.
Then the information of all the employees belonging to a particular department will be stored together in that very partition. Physically, a partition in Hive is nothing but just a sub-directory in the table directory.
For example, we have data for three departments in our employee_details table – Technical, Marketing and Sales. Thus we will have three partitions in total for each of the departments as we can see clearly in diagram below.
For each department we will have all the data regarding that very department residing in a separate sub – directory under the table directory.
So for example, all the employee data regarding Technical departments will be stored in user/hive/warehouse/employee_details/dept.=Technical. So, the queries regarding Technical employee would only have to look through the data present in the Technical partition.
Therefore from above example, we can conclude that partitioning is very useful. It reduces the query latency by scanning only relevant partitioned data instead of the whole data set.
b) Hive Bucketing Example
Hence, from the above diagram, we can see that how each partition is bucketed into 2 buckets. Therefore each partition, says Technical, will have two files where each of them will be storing the Technical employee’s data
iii. Advantages and Disadvantages of Hive Partitioning & Bucketing
Let us now discuss the pros and cons of Hive partitioning and Bucketing one by one-
a) Pros and Cons of Hive Partitioning
Pros:
- It distributes execution load horizontally.
- In partition faster execution of queries with the low volume of data takes place. For example, search population from Vatican City returns very fast instead of searching entire world population.
Cons:
- There is the possibility of too many small partition creations- too many directories.
- Partition is effective for low volume data. But there some queries like group by on high volume of data take a long time to execute. For example, grouping population of China will take a long time as compared to a grouping of the population in Vatican City.
- There is no need for searching entire table column for a single record.
b) Pros and Cons of Hive Bucketing
Pros:
- It provides faster query response like portioning.
- In bucketing due to equal volumes of data in each partition, joins at Map side will be quicker.
Cons:
- We can define a number of buckets during table creation. But loading of an equal volume of data has to be done manually by programmers.
So, this was all about Hive Partitioning vs Bucketing. Hope you like our explanation.
Conclusion
In conclusion to Hive Partitioning vs Bucketing, we can say that both partition and bucket distributes a subset of the table’s data to a subdirectory. Hence, Hive organizes tables into partitions. And it subdivides partition into buckets.
If you like this blog or have any query related to Hive Partitioning vs Bucketing, so, please let us know by leaving a comment.
Did you like our efforts? If Yes, please give DataFlair 5 Stars on Google





i recommended best blog to learn Bigdata hadoop
but where we can get sample datasets related to your commands ??? like population dataset etc
Where cluster by and groupby is used partitioning and bucketing?