Sort Merge Bucket Join in Hive – SMB Join
In our last article, we discuss Skew Join in Hive. Today, we will discuss Sort Merge Bucket Join in Hive – SMB Join in Hive. Basically, when each mapper reads a bucket from the first table and the corresponding bucket from the second table in Apache Hive.
Then we perform a Hive Sort merge Bucket join feature. However, there are much more to learn about Sort merge Bucket Map join in Hive. S
o, in this article, we will learn the whole concept of Sort merge Bucket Map join in Hive, includes use cases & disadvantages of Hive SMB Join and Hive Sort Merge Bucket Join example to understand well.
What is Sort Merge Bucket Join in Hive?
In Hive, while each mapper reads a bucket from the first table and the corresponding bucket from the second table, in SMB join. Basically, then we perform a merge sort join feature. Moreover, we mainly use it when there is no limit on file or partition or table join.
Also, when the tables are large we can use Hive Sort Merge Bucket join. However, using the join columns, all join the columns are bucketed and sorted in SMB. Although, make sure in SMB join all tables should have the same number of buckets.
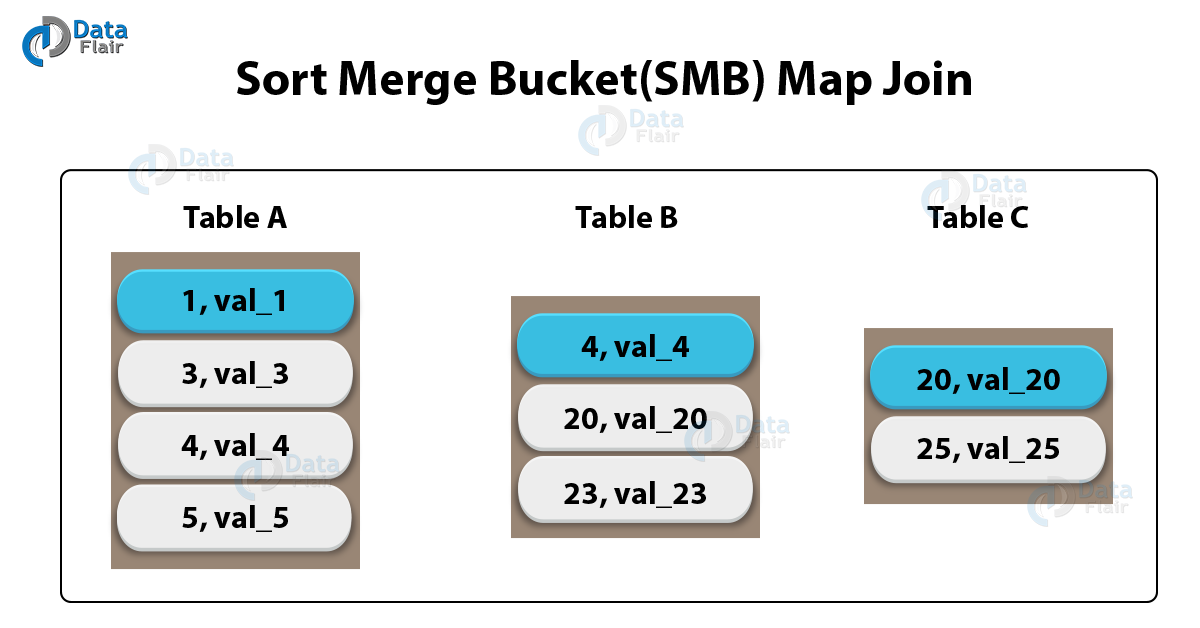
Sort Merge Bucket Map Join in Hive- SMB join
How Hive SMB Works?
Basically, in Mapper, only Join is done. Moreover, all the buckets are joined with each other at the mapper which are corresponding.
Use Case of Sort Merge Bucket Join in Hive
There are several scenarios when we can use Hive Sort Merge Bucket Join:
- While all tables are Large.
- Also, while all tables are bucketed using the join columns.
- While by using the join columns, Sorted.
- Also, when the number of buckets is same as the number of all tables.
Disadvantages of Sort Merge Bucket Join in Hive
Following are the limitations of Hive Sort Merge Bucket Join:
- However, in the same way how the SQL joins Tables need to be bucketed. Hence, for other types of SQL, it cannot be used.
- Also, it is possible that Partition tables might slow down here.
Hive Sort Merge Bucket Join Example
hive> explain select c1.* from c1,c2 where c1.col0=c2.col0;
OK
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: c1
Statistics: Num rows: 9963904 Data size: 477218560 Basic stats: COMPLETE Column stats: NONE
Sorted Merge Bucket Map Join Operator
condition map:
Inner Join 0 to 1
condition expressions:
0 {col0} {col1} {col2} {col3} {col4} {col5} {col6}
1 {col0}
keys:
0 col0 (type: string)
1 col0 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col9
Filter Operator
predicate: (_col0 = _col9) (type: boolean)
Select Operator
expressions: _col0 (type: string), _col1 (type: string), _col2 (type: string), _col3 (type: string), _col4 (type: string), _col5 (type: string), _col6 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6
File Output Operator
compressed: false
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Time taken: 0.134 seconds, Fetched: 37 row(s)
Tips for Hive Sort Merge Bucket Join (SMB)
At below, we discuss some tips for Sort Merge Bucket Join in Hive.
a. However, it is a requirement that all the tables need to be created bucketed and sorted on the same join columns. Also, data need to be bucketed when inserting.
So, before inserting data the one way is to set “hive.enforce.bucketing=true”.
For example:
create table c1(col0 string,col1 string,col2 string,col3 string,col4 string,col5 string,col6 string)
clustered by (col0) sorted by (col0) into 32 buckets;
create table c2(col0 string,col1 string,col2 string,col3 string,col4 string,col5 string,col6 string)
clustered by (col0) sorted by (col0) into 32 buckets;
set hive.enforce.bucketing = true;
From passwords insert OVERWRITE table c1 select * order by col0;
From passwords insert OVERWRITE table c2 select * order by col0;
b. It is necessary to convert SMB join to SMB map join Below parameters need to set.
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
c. Moreover, we can determine which table is for only streaming by using Big table selection policy parameter “hive.auto.convert.sortmerge.join.bigtable.selection.policy”.
Although, there are 3 values of it:
org.apache.hadoop.hive.ql.optimizer.AvgPartitionSizeBasedBigTableSelectorForAutoSMJ (default)
org.apache.hadoop.hive.ql.optimizer.LeftmostBigTableSelectorForAutoSMJ
org.apache.hadoop.hive.ql.optimizer.TableSizeBasedBigTableSelectorForAutoSMJ
d. Also, we can easily determine which table is small and should be loaded into memory by using Hint “MAPJOIN”.
e. However, One of the major key points is Small tables are read on demand here. Hence, that implies not holding small tables in memory.
f. Moreover, it supports Outer join.
Conclusion
As a result, we have learned we will learn the what is Sort Merge Bucket Map join in Hive. Also, we have seen use cases and disadvantages of Hive SMB Join, and Hive Sort Merge Bucket Join examples. Still, if any query occurs feel free to ask in the comment section.
Thus, we assure we will definitely get back to you. Moreover, keep visiting our Site DataFlair for more article on Big Data and its technologies.
Your opinion matters
Please write your valuable feedback about DataFlair on Google




