How to Find Duplicate Records in SQL – With & Without DISTINCT Keyword
Expert-led Online Courses: Elevate Your Skills, Get ready for Future - Enroll Now!
In this tutorial, we will learn about duplicates and the reasons we need to eliminate them. Also, we will focus on the methods with which we can remove duplicates from the data we have in our SQL database.
What are Duplicates in SQL?
Duplicates in SQL are mostly the data points that exist more than once in our data store.
For example:
If we consider a customer table and in it, we store the details of customers of any particular shop. Then here, duplicate records would be the entry of a single customer more than once.
In such cases, the system has an increased load of handling large data stores and their processing.
Why do we need to handle Duplicates in SQL?
Some of the major reasons why we need to remove duplicates from our records are as follows:
1. The size of data to be stored increases due to the duplicates.
2. When we have duplicates in our data they can give rise to business errors also known as logical errors.
3. Due to the increased use of resources, the overall cost of the handling resources rises.
4. Errors arise when analytics are performed on such erroneous data.
Demo Database
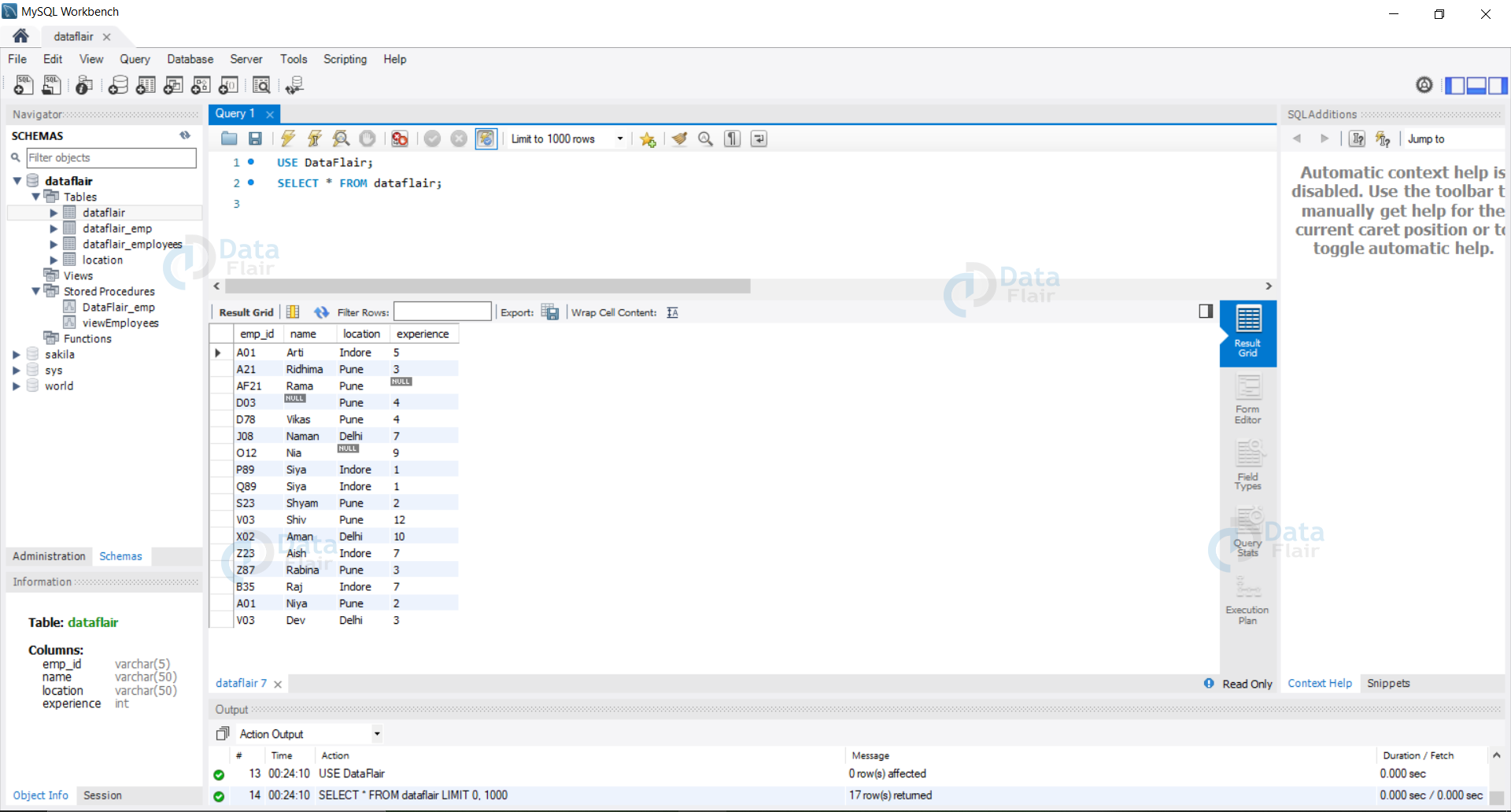
Let us now have a look at our demo database: DataFlair.
Query:
USE DataFlair; SELECT * FROM dataflair;
Output:
How to handle Duplicates in SQL?
We have various solutions present to handle the duplicates which exist in our database. Some of them are as follows:
1. Using the Distinct Keyword to eliminate duplicate values and count their occurences from the Query results.
We can use the Distinct keyword to fetch the unique records from our database. This way we can view the unique results from our database.
Syntax:
SELECT col1, col2, COUNT(DISTINCT(col3)),..... FROM tableName;
Example: Let us first try to view the count of unique id’s in our records by finding the total records and then the number of unique records.
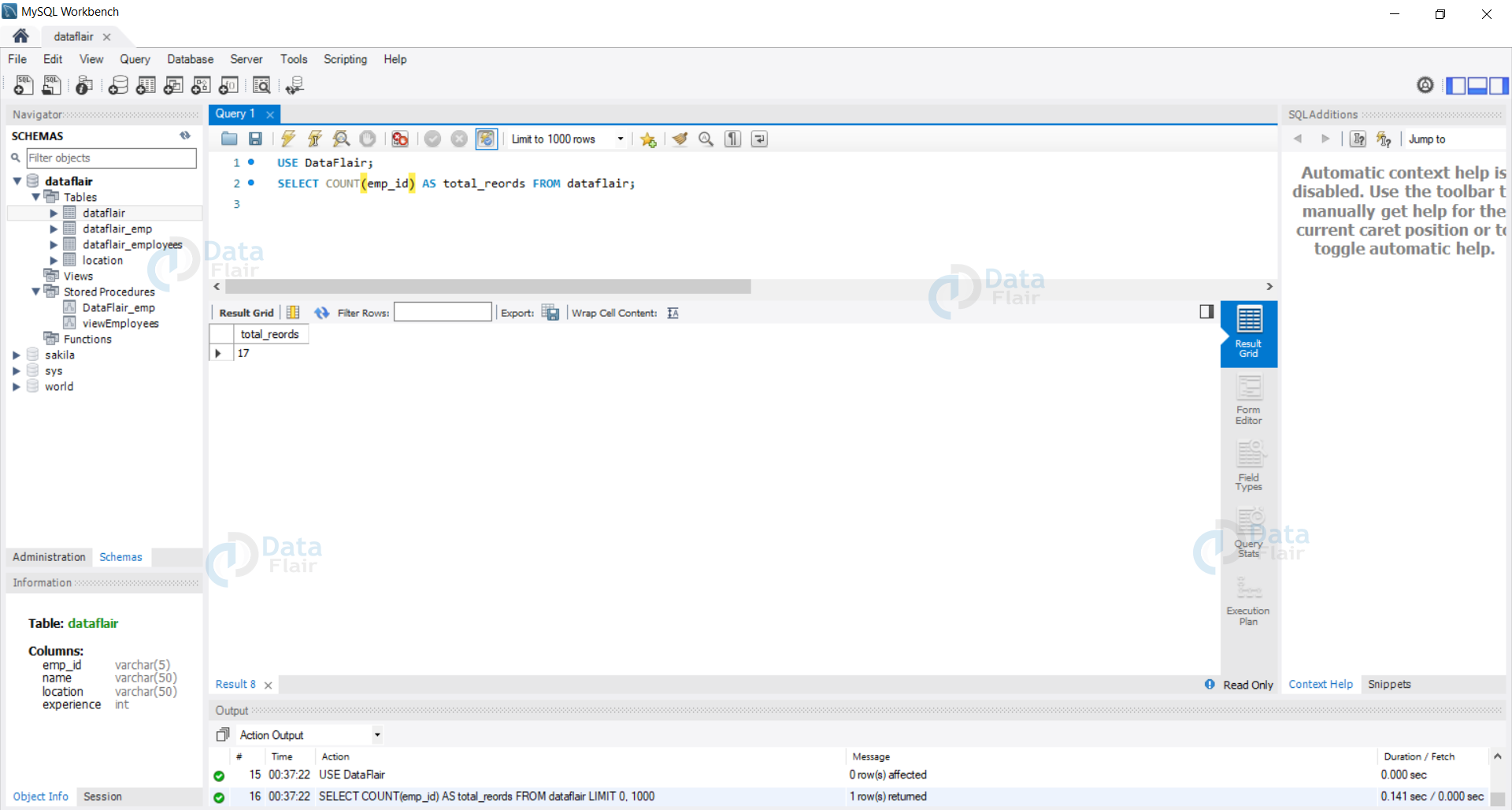
Step 1: View the count of all records in our database.
Query:
USE DataFlair; SELECT COUNT(emp_id) AS total_records FROM dataflair;
Output:
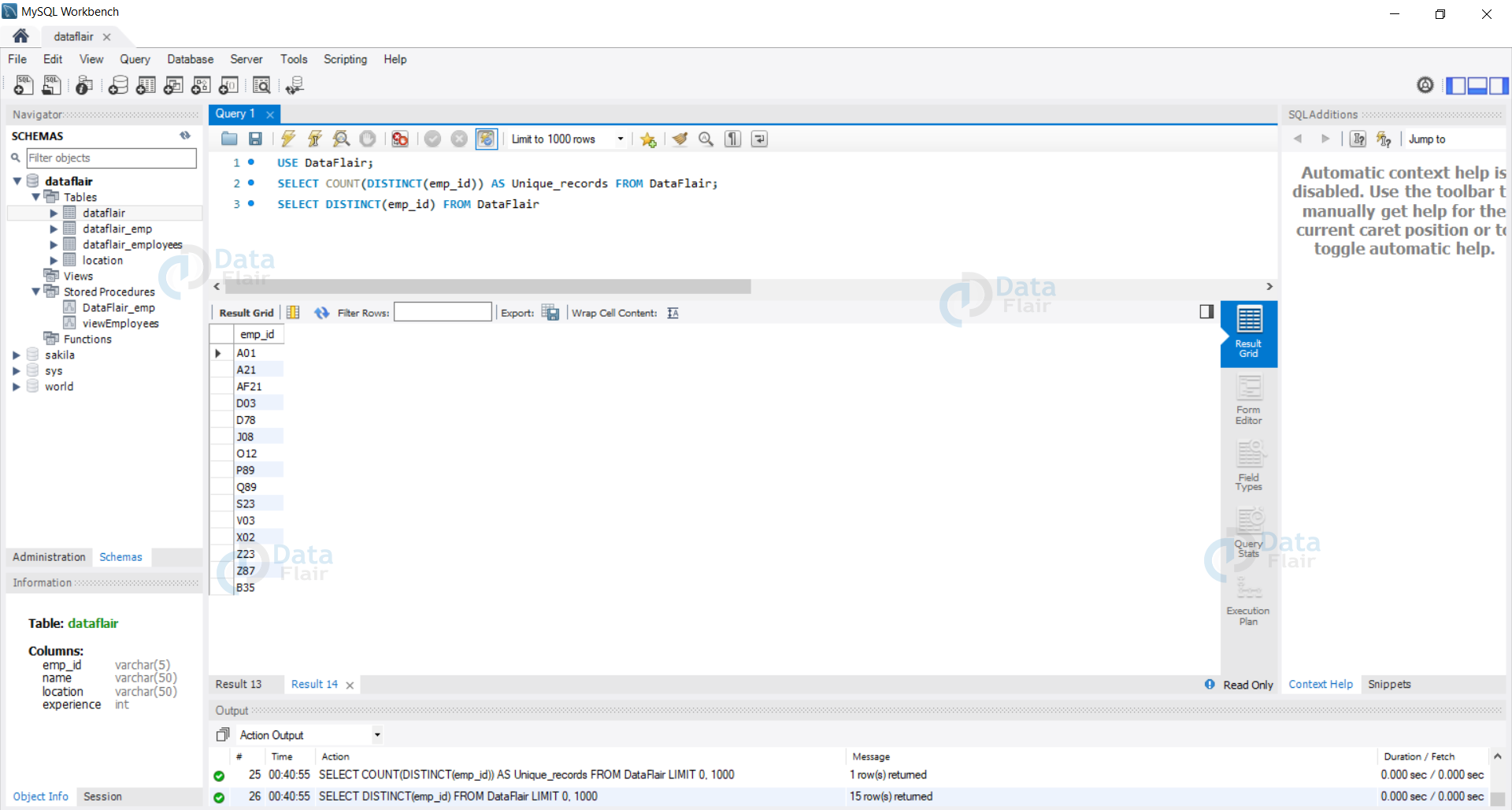
Step 2: View the count of unique records in our database.
Query:
USE DataFlair; SELECT COUNT(DISTINCT(emp_id)) AS Unique_records FROM DataFlair; SELECT DISTINCT(emp_id) FROM DataFlair;
Output:
2. Using Distinct keyword to delete the Duplicate records from the database.
Syntax:
SELECT col1, col2, DISTINCT(col3),..... FROM tableName;
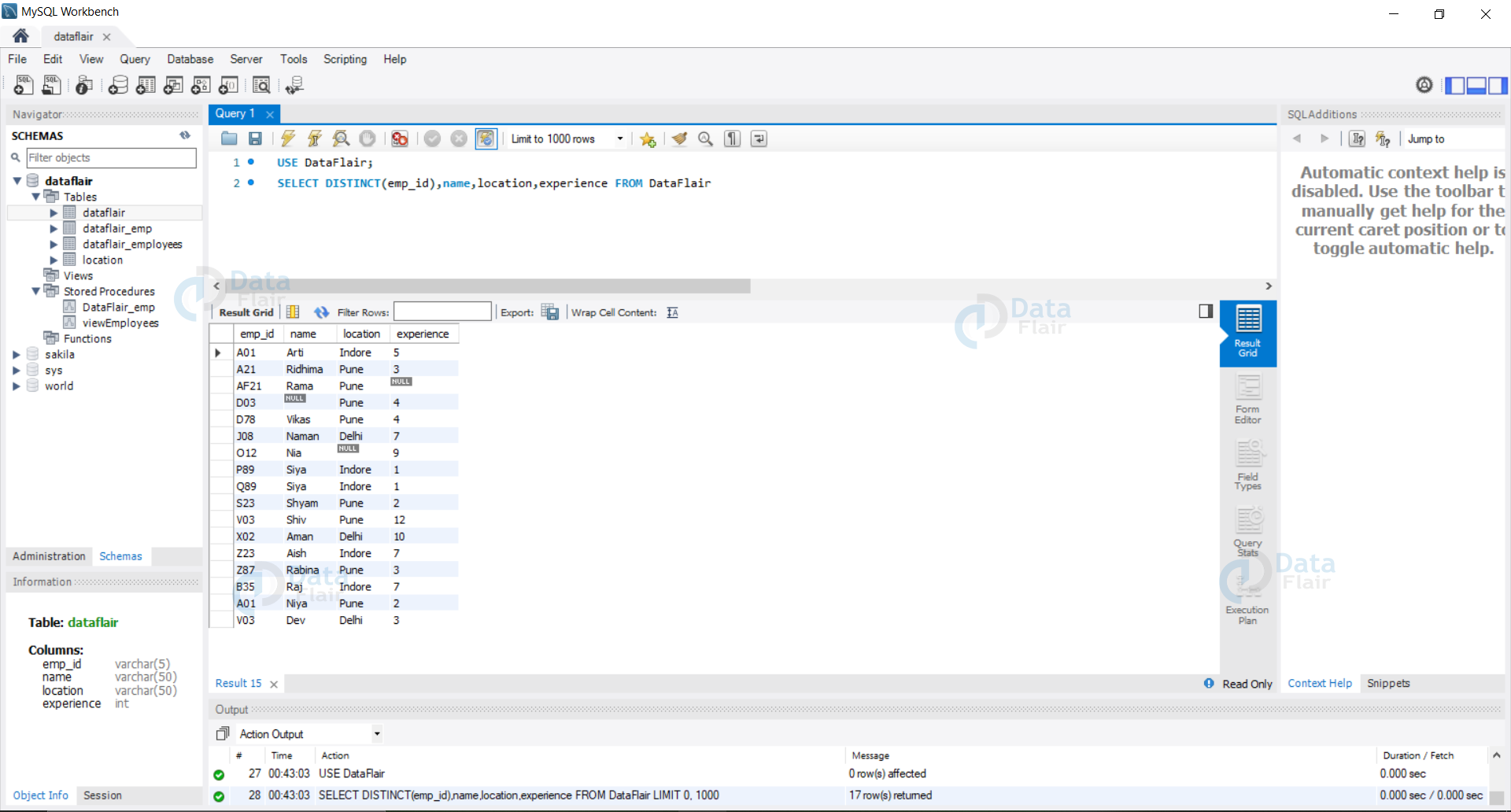
Example: Let us now view our table after deleting the duplicate records in our database.
Query:
USE DataFlair; SELECT DISTINCT(emp_id),name,location,experience FROM DataFlair
Output:
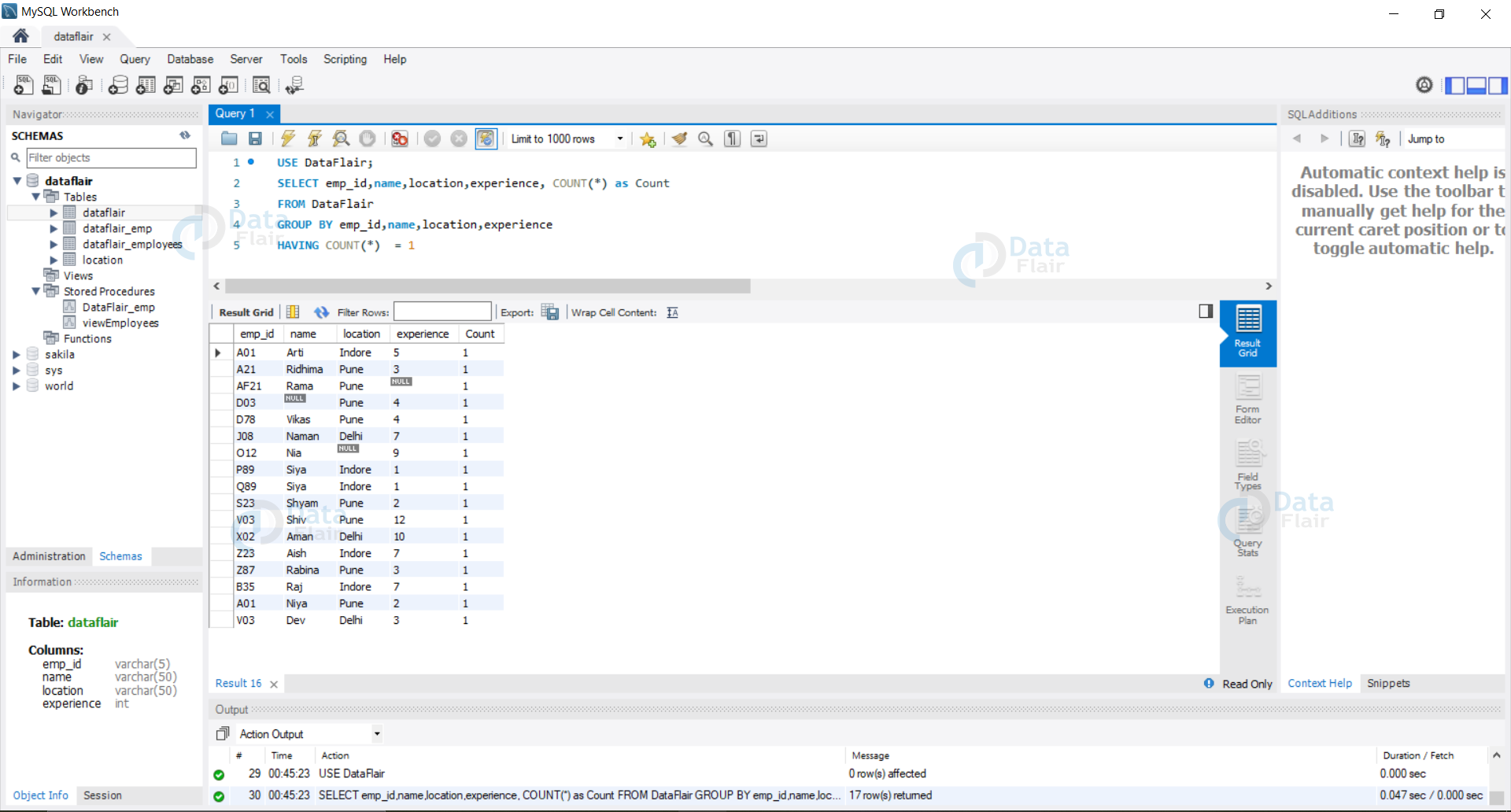
3. Using the Count keyword and Group By to eliminate the duplicate records.
Syntax:
SELECT col1,col2,col3,...... COUNT(*) AS aliasName FROM tableName GROUP BY col1,col2,col3,...... HAVING COUNT(*) = 1;
Example: Let us now eliminate the duplicate records of our database using the Count and the Group By keyword.
Query:
USE DataFlair; SELECT emp_id,name,location,experience, COUNT(*) as Count FROM DataFlair GROUP BY emp_id,name,location,experience HAVING COUNT(*) = 1
Output:
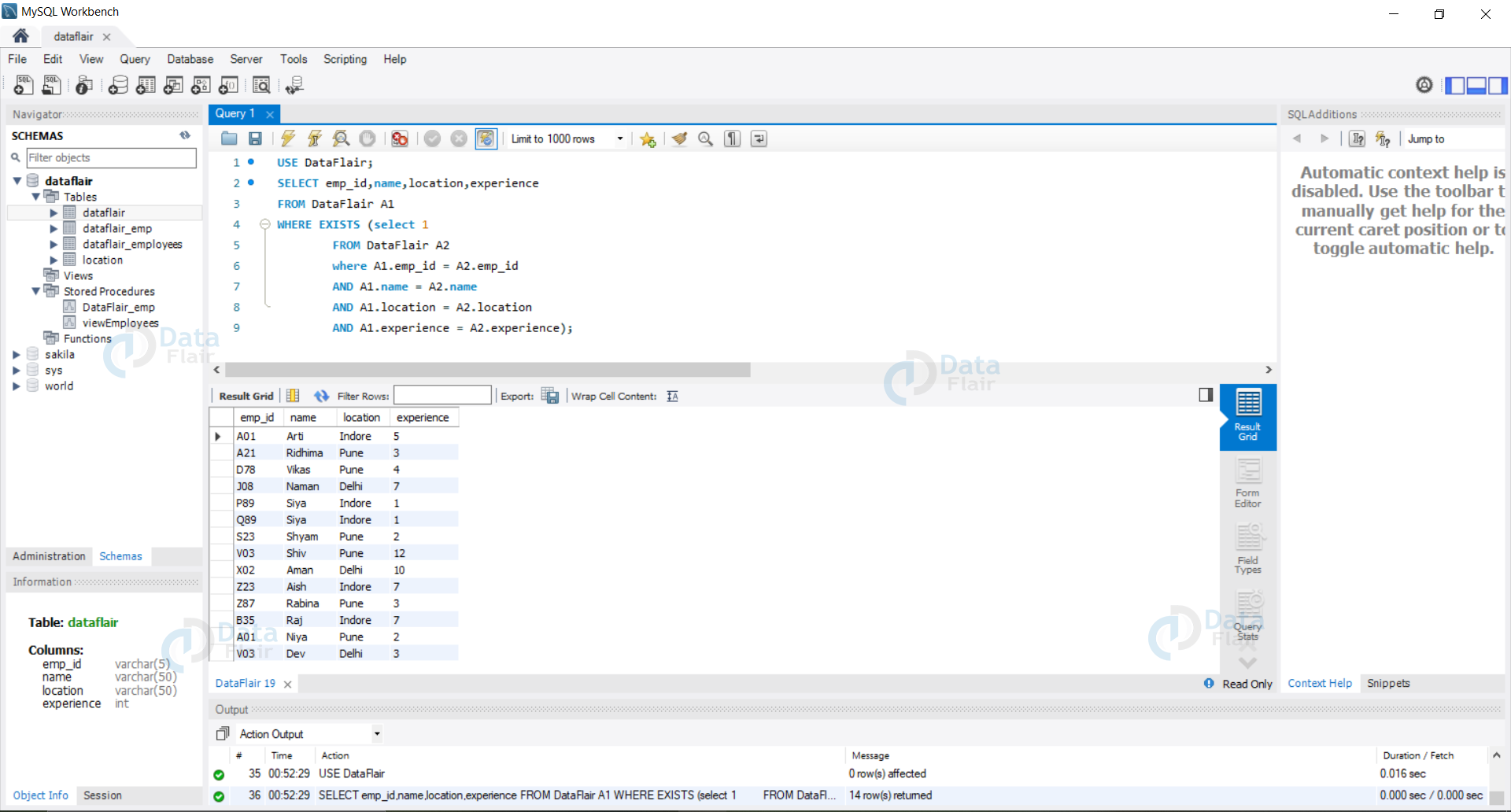
4. Using Joins to eliminate the Duplicate records.
Syntax:
SELECT col1,col2,col3,.... FROM tableName alias WHERE EXISTS(SELECT 1 FROM tableName alias2 WHERE Alias.col1 = Alias1.col1 AND Alias.col2 = Alias2.col2 AND Alias.col2 = Alias2.col2 AND ...);
Example: Let us now try to remove the duplicates from our data using Join operation on our data.
Query:
USE DataFlair;
SELECT emp_id,name,location,experience
FROM DataFlair A1
WHERE EXISTS (SELECT 1
FROM DataFlair A2
where A1.emp_id = A2.emp_id
AND A1.name = A2.name
AND A1.location = A2.location
AND A1.experience = A2.experience);
Output:
Summary
In this tutorial, we have understood what are duplicates and how do they affect our business. We have then also discussed various methods by which we can either handle or completely remove duplicates from our database.
We have various methods like the Distinct keyword and then we have also seen the use of count and the Group By clause. And at last, we have seen how we can use joins to eliminate duplicates from our data.
Your 15 seconds will encourage us to work even harder
Please share your happy experience on Google




