Pandas DataFrame Tutorial – A Complete Guide (Don’t Miss the Opportunity)
Get Job-Ready: Data Analysis using Python with 70+ Projects Start Now!!
Pandas DataFrame is the Data Structure, which is a 2 dimensional Array. One can say that multiple Pandas Series make a Pandas DataFrame. DataFrames are visually represented in the form of a table. DataFrames are one of the most integral data structure and one can’t simply proceed to learn Pandas without learning DataFrames first.
Parameters of DataFrames in Pandas
- data – The data from which the dataframe will be made
- index – States the index from dataframe
- columns – States the column label
- dtype – The datatype for the dataframe
- copy – Any copied data taken from inputs
In this Pandas Dataframe tutorial, we are going to study everything about dataframes like creating, renaming, deleting, transposing, etc.
So, don’t waste your time and get ready to dive into an ocean of information.
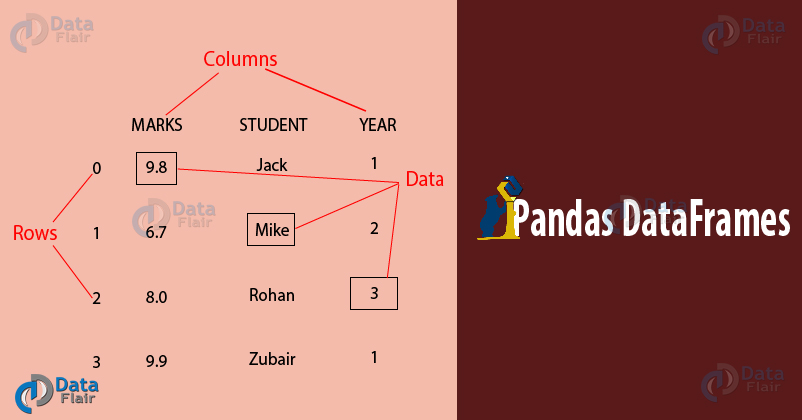
1. How to Create Pandas DataFrame from the dictionary?
We start by importing the pandas library
>>> import pandas as pd >>> import numpy as np
To become an expert in Pandas, you should be aware of Pandas Basic Functionalities
To create a DataFrame in Pandas from a dict, we first need to make a dict. For that, we will use the following command:
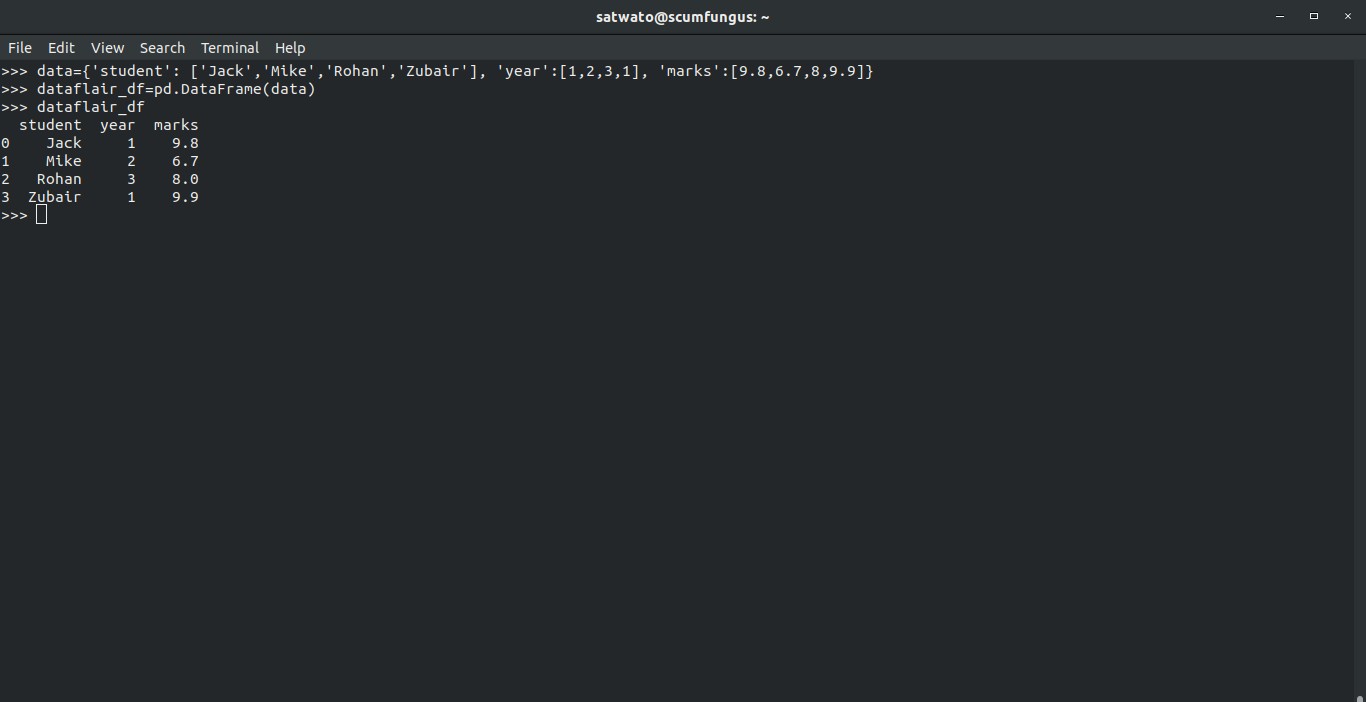
>>> data={'student': ['Jack','Mike','Rohan','Zubair'], 'year':[1,2,3,1], 'marks':[9.8,6.7,8,9.9]}After this is done, all we have to do to make a DataFrame is to use the following commands:
>>> dataflair_df=pd.DataFrame(data) >>> dataflair_df
The first line of code makes the DataFrame while the second one simply prints the entire thing out. We will get an out like this:
2. How to Access Last and First Rows of DataFrame in Pandas?
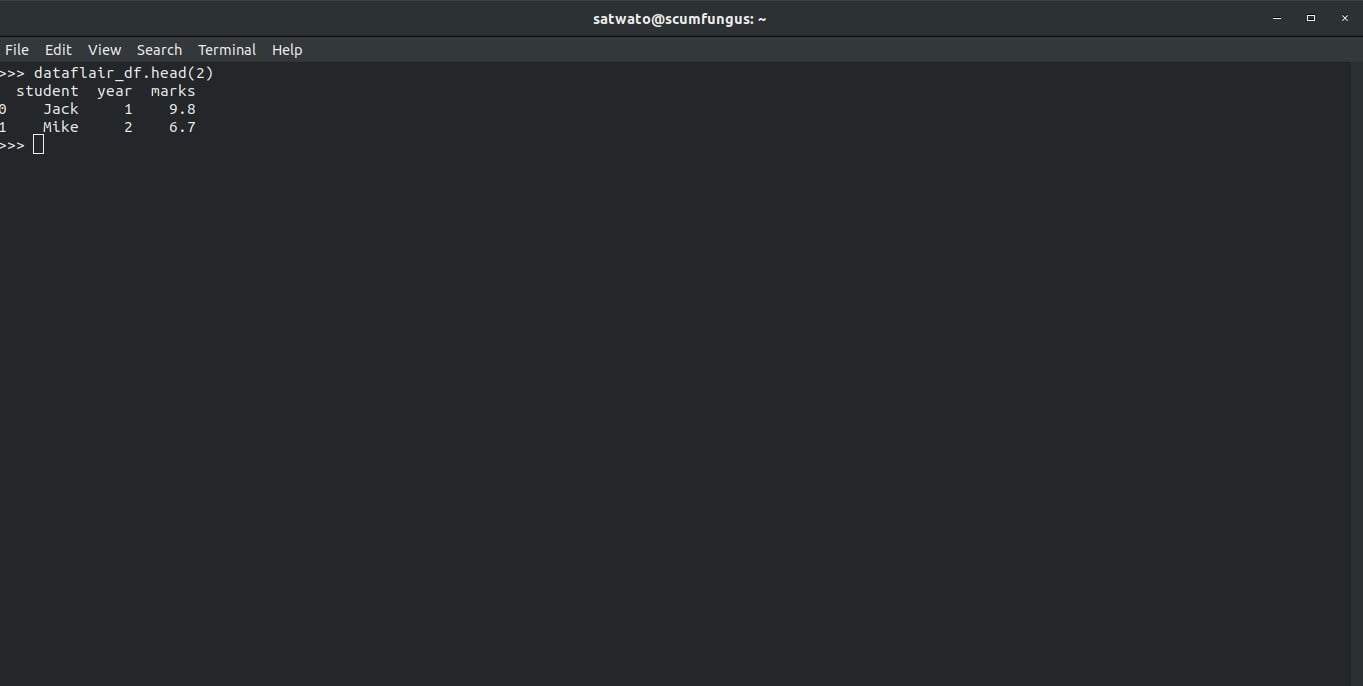
Using .head() and .tail(), we have been able to access the first few rows and the last few rows. In both cases, without a parameter, we will get 2 rows. Let’s continue with the help of examples:
>>> dataflair_df.head(2)
Output-
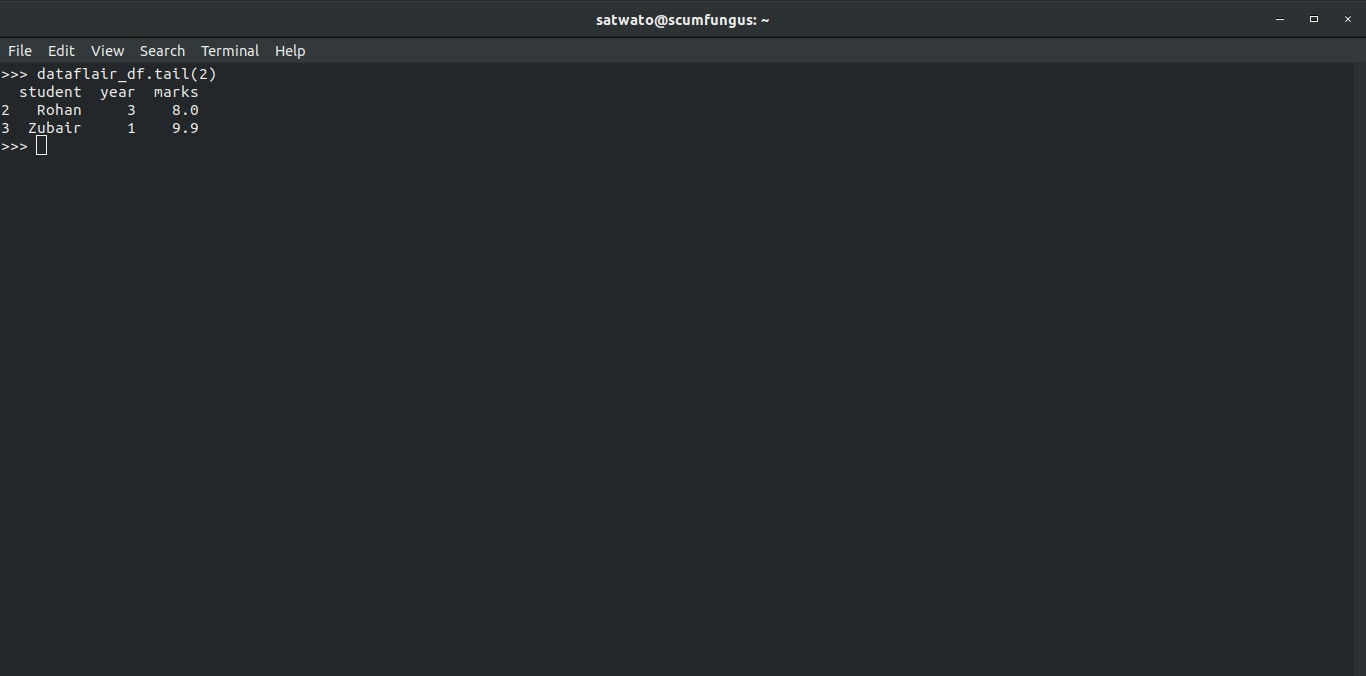
>>> dataflair_df.tail(2)
Output-
Get the easy steps to Sort Pandas Dataframes and Series
3. How to Change the Column in Pandas DataFrame?
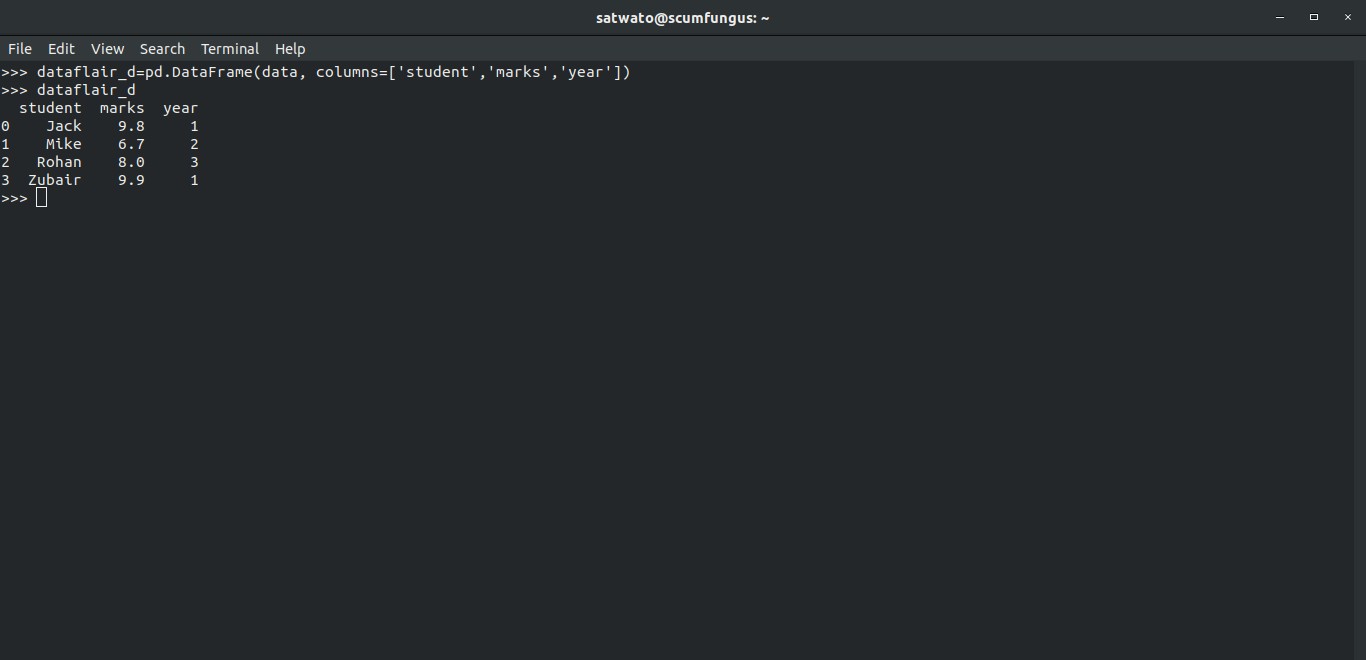
As we can see, the DataFrame is not representing our content according to the column order, we gave in the dictionary. Therefore the following method is used:
>>> dataflair_d=pd.DataFrame(data, columns=['student','marks','year']) >>> dataflair_d
Output-
4. How to Access the Columns in Pandas DataFrame?
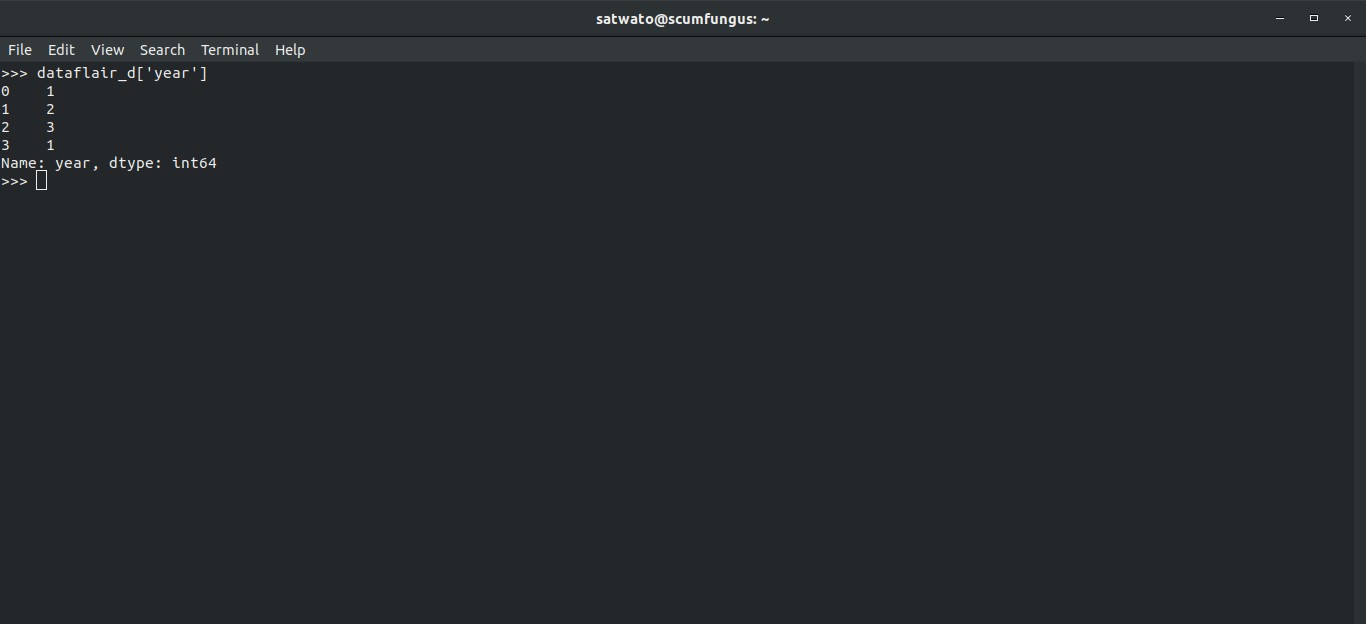
Columns can be accessed in two ways:
>>> dataflair_d['year']
Output-
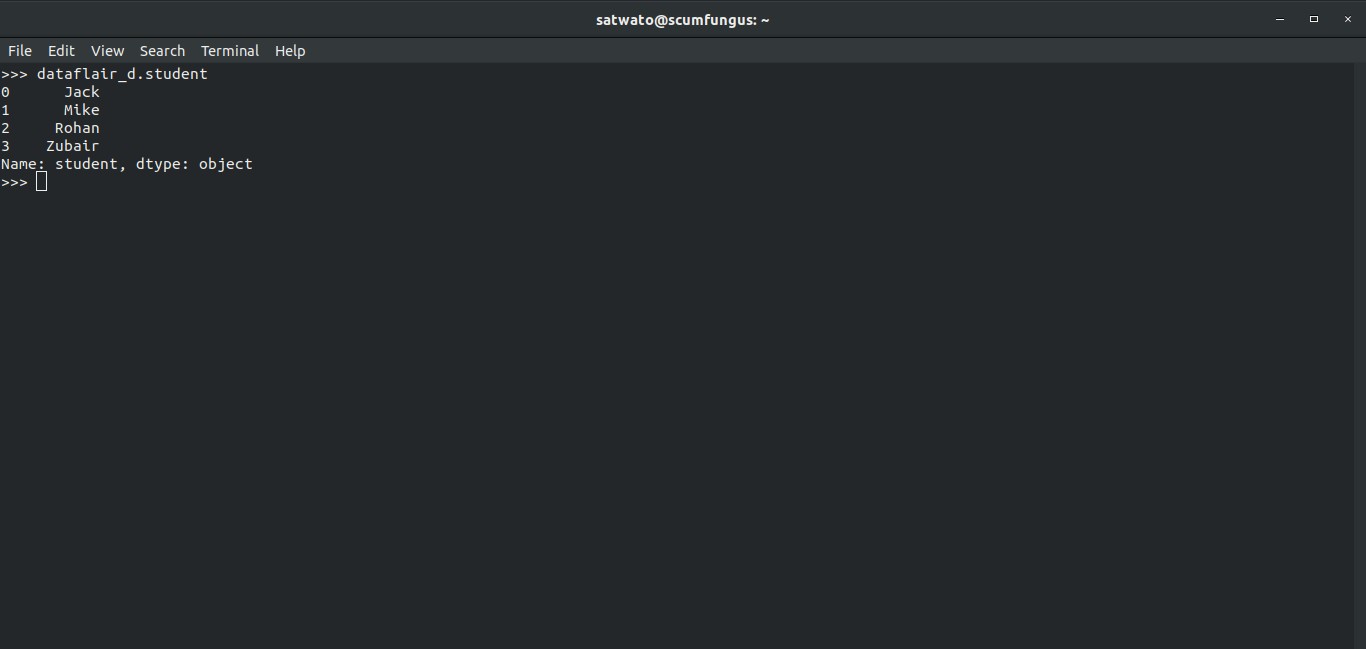
Or we can also access columns as an attribute:
>>> dataflair_d.student
Output-
5. How to Access the Rows in DataFrames?
We use loc and iloc functions to access rows. Here is an example of how that works:
>>> dataflair_d.loc[2]
Output-
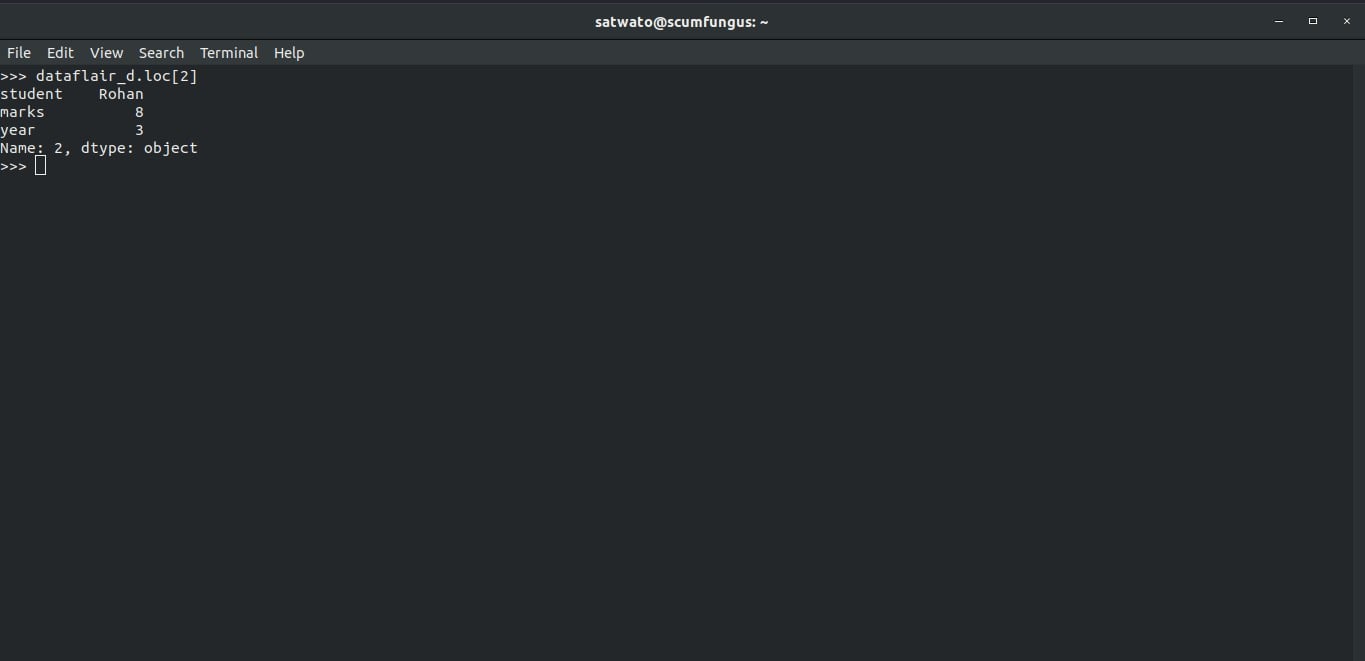
Here, we see that the loc function returns the values of the row needed along with the column names attributed to each value. This is a very helpful function.
6. Various Assignments and Operations on Pandas DataFrame
Let’s create a second DataFrame and this time, in the column attribute, let’s add a column that was not present in our dictionary.
>>> dataflair_df2= pd.DataFrame(data, columns=['student','marks','year','subjects']) >>> dataflair_df2
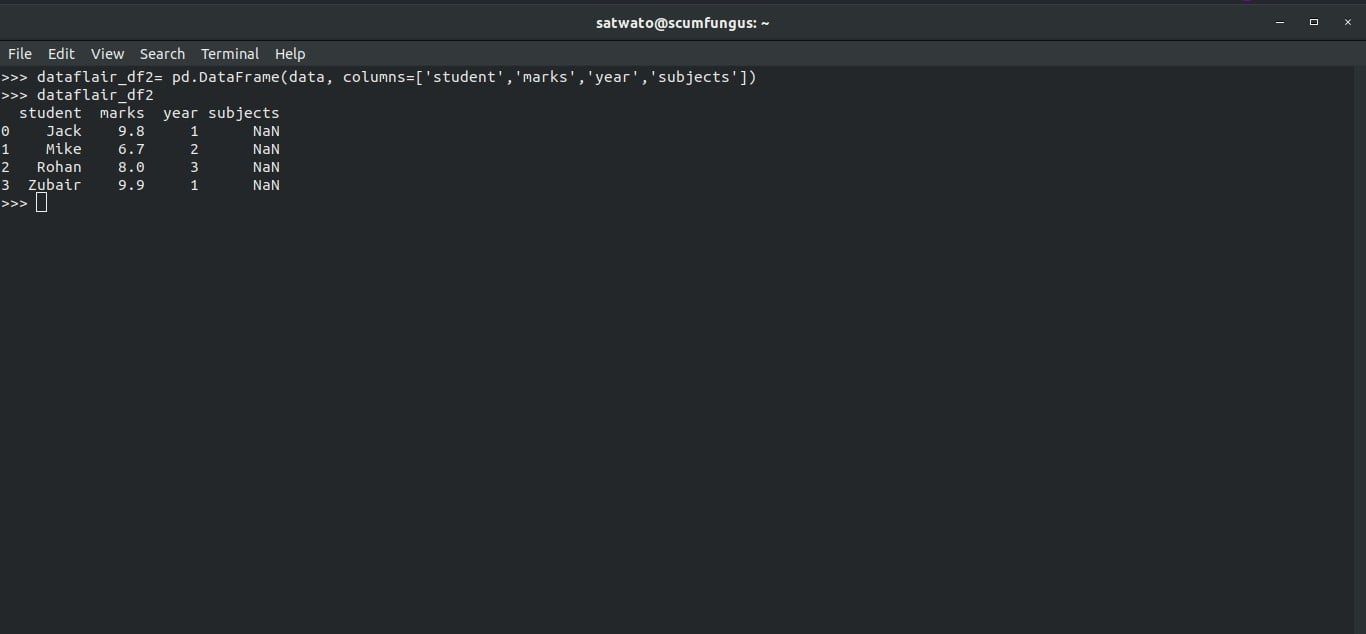
The column ‘subject’ was never a part of out original dictionary. Let’s see how Pandas handles this:
Pandas took all the values of the column ‘subject’ to be missing values and thus represented them as ‘NaN’
A cool feature of Pandas is that you assign a column with a certain constant value. For example:
>>> dataflair_df2['subjects']=4 >>> dataflair_df2
Output-
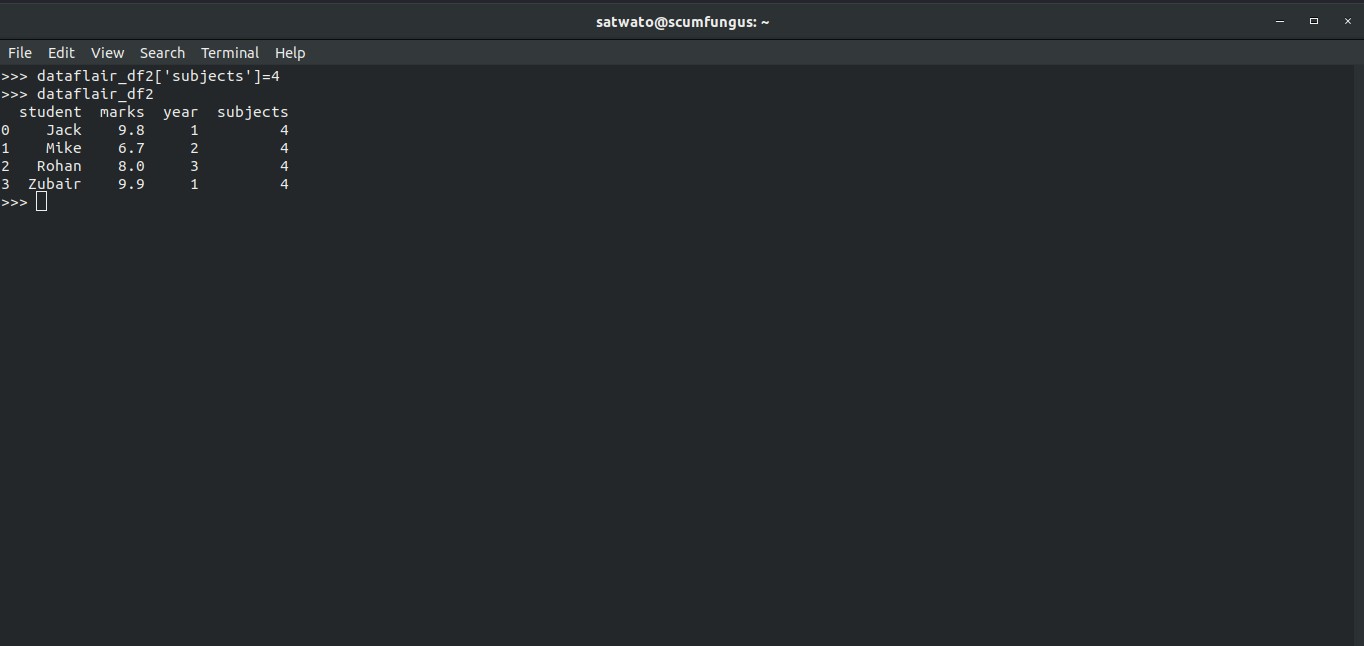
This will give us a DataFrame with the subject column containing just the value of 4 for every row.
We can also map series onto a column in a DataFrame. To see how that works, let us first create a series.
>>> ser=pd.Series([2,3,],index=[1,3])
Then we will map it onto our ‘subject’ column:
>>> dataflair_df2['subjects']=ser >>> dataflair_df2
Output-
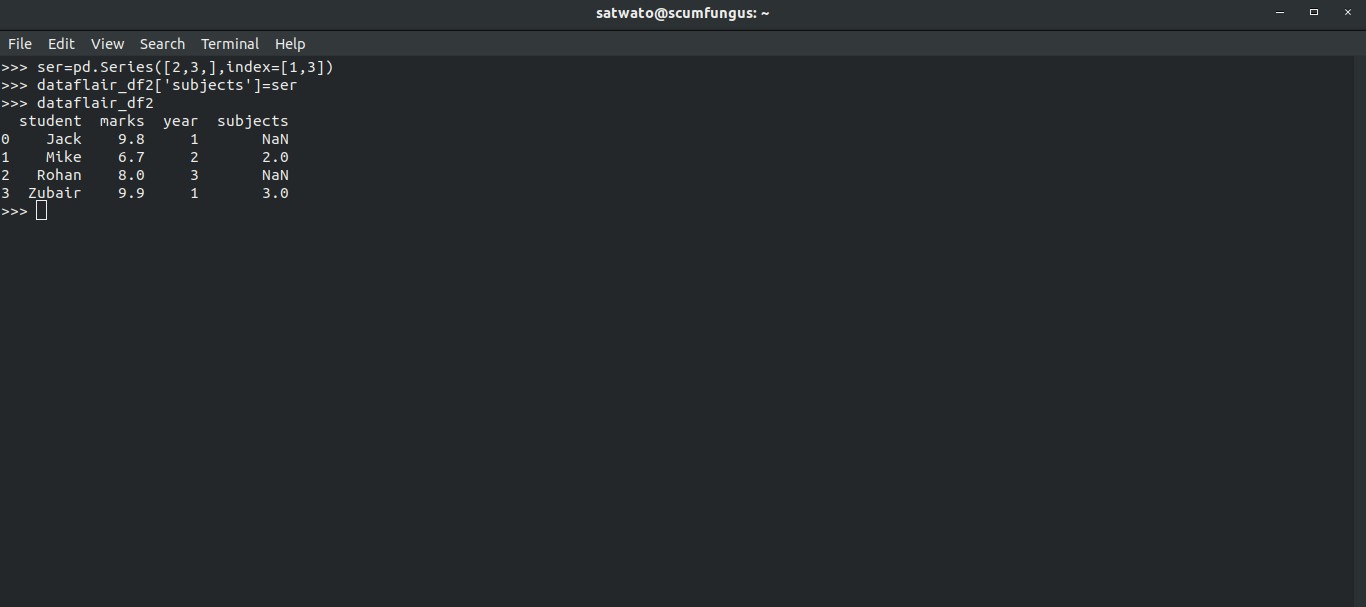
From the above output, 1 and 3 consider as an index for the values of the series. When pandas dataframes mapped columns make sure they only occupy the indices, which were mentioned. The indices that were not mentioned, get a missing value as their value.
We can also perform boolean assignments on operators. Let’s take a new column called ‘grades’
>>> dataflair_df2['grade']=dataflair_df2.marks>8 >>> dataflair_df2
Output-
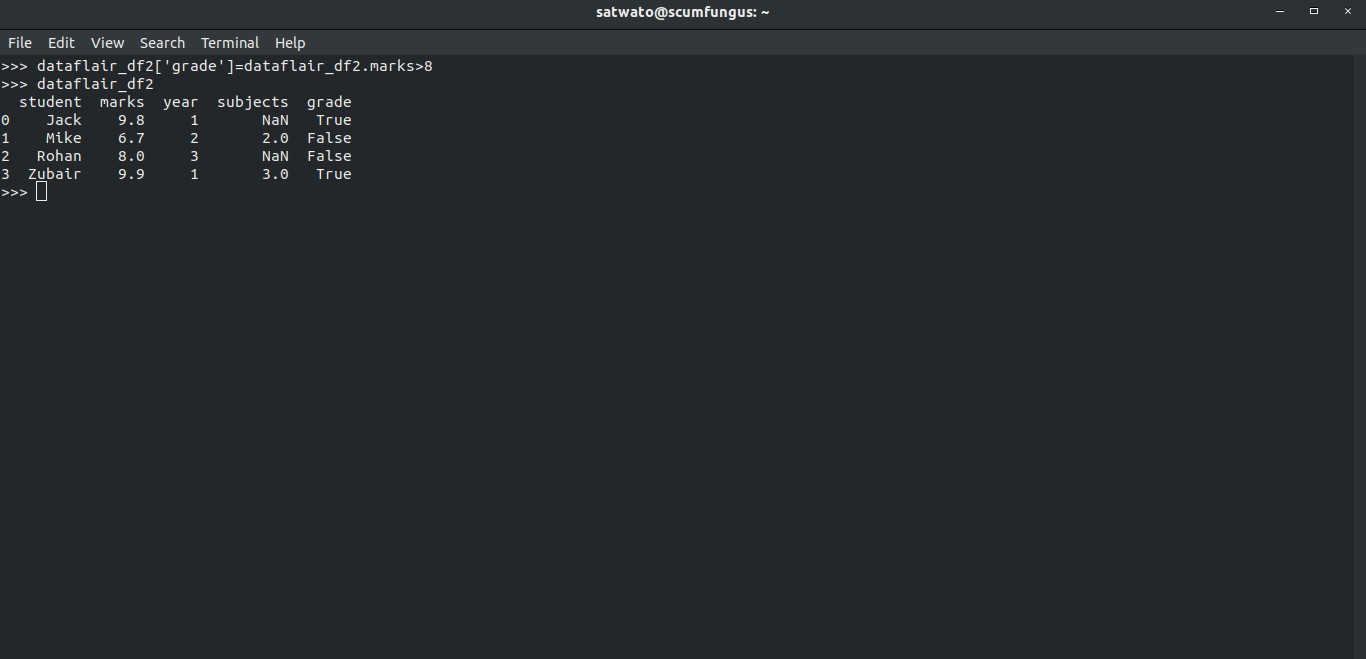
What this does is, it creates a new column ‘grade’ and fills each value of the column with a boolean expression that is returned when df.marks>8 is evaluated for each row. The boolean value can either be True or False.
Here we see, 6 and 7 gives the false value because both these numbers are not greater than 8
It’s the right time to Customize your data with Pandas Options
7. How to Delete Columns in Pandas DataFrame?
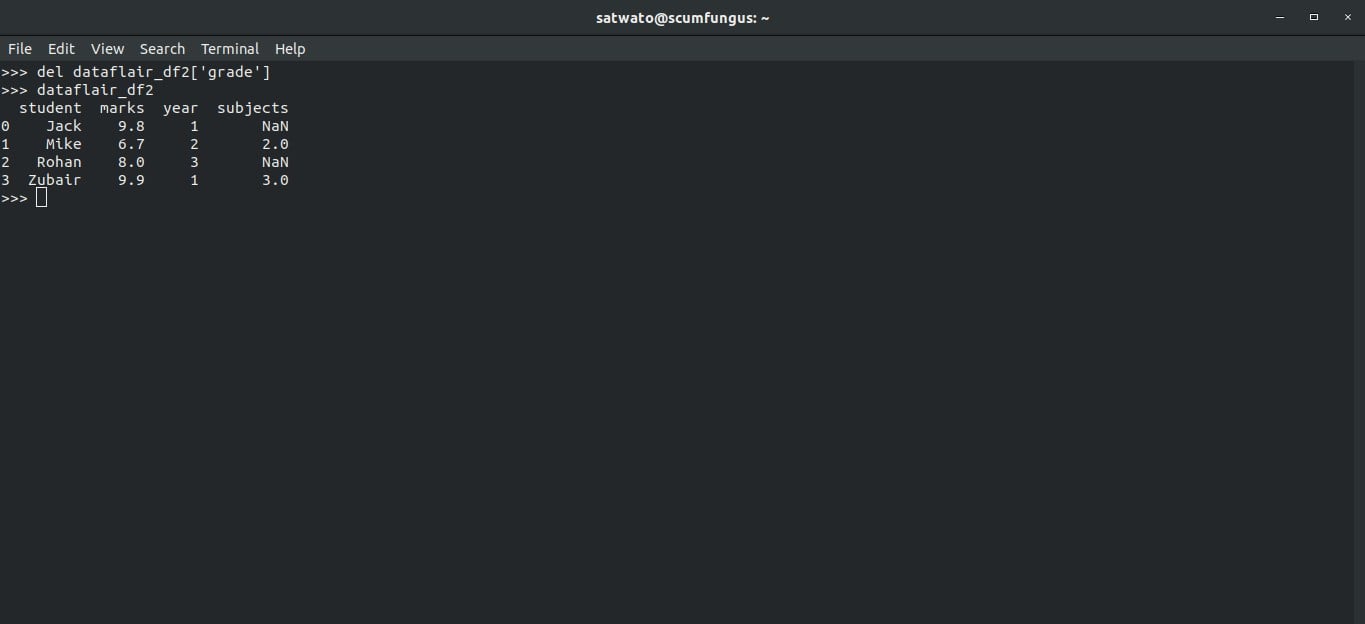
To delete a column in Pandas Dataframes, all we need to do is use the command del
>>> del dataflair_df2['grade'] >>> dataflair_df2
This will give us:
8. How to Delete Rows in Pandas DataFrame?
Pandas use .drop function to remove rows and columns.
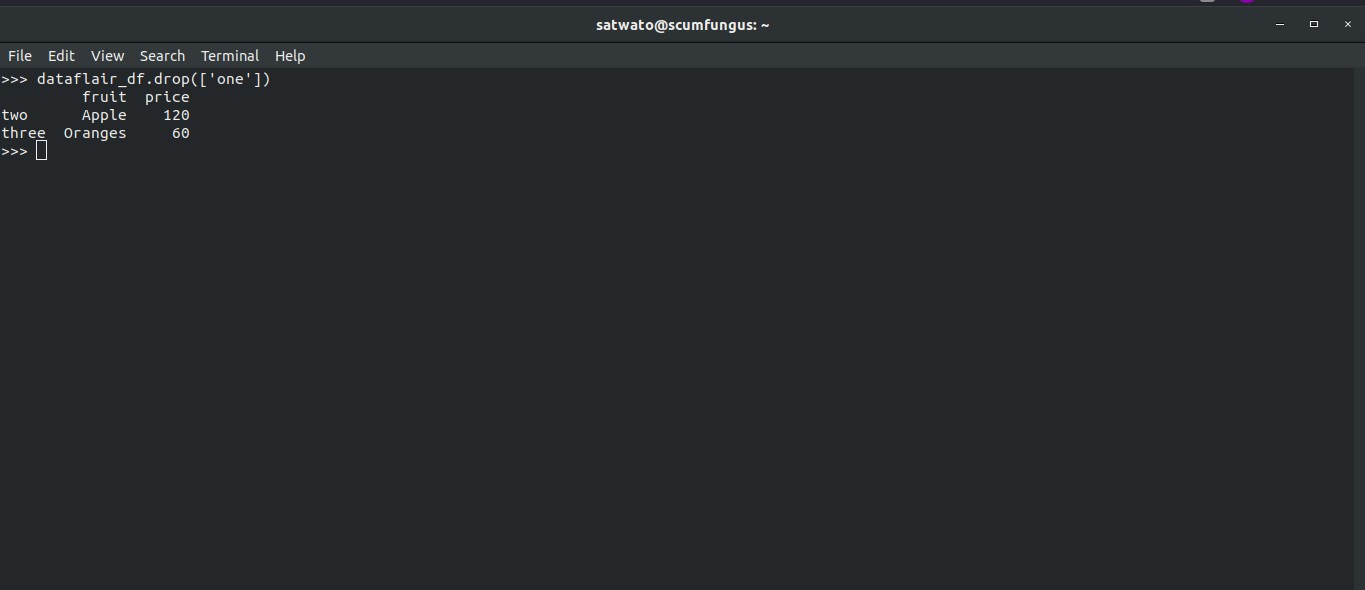
To remove rows according to the index we will do the following:
>>> dataflair_df.drop(['one'])
Output-
9. Pandas DataFrame with Nested Dictionaries
Let us consider a nested dictionary:
>>> dict={'fruits':{'apple':40,'orange':20,'bananas':25,'grapes':30}, 'vegetables':{'carrot':20,'beans':16,'peas':30,'onion':25}}In this dictionary, we see two dictionaries, ‘fruits’ and ‘vegetables’. These two dictionaries will get a column to their name. Let’s see, what happens when putting in a DataFrame:
>>> dataflair_df3=pd.DataFrame(dict) >>> dataflair_df3
Output-
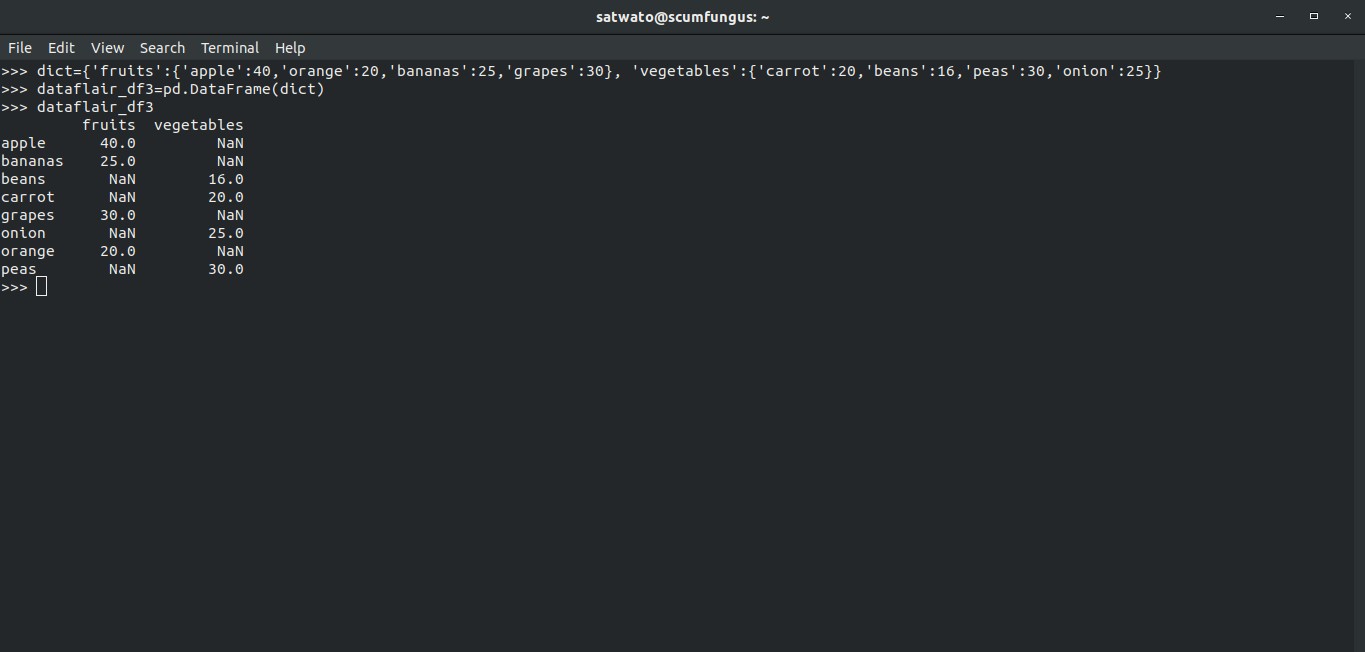
Therefore, we get Pandas DataFrame which uses all the members of the nested dictionaries. The members of one dictionary, which are not present in the other, gets represented as a Missing Value for the dictionary they aren’t present in.
For example, apple is present in the dictionary fruits, not in vegetables. Therefore in column fruits, it has the value pertaining to it in the dictionary, while vegetable column gets a NaN for apple.
10. How to Transpose Pandas DataFrames?
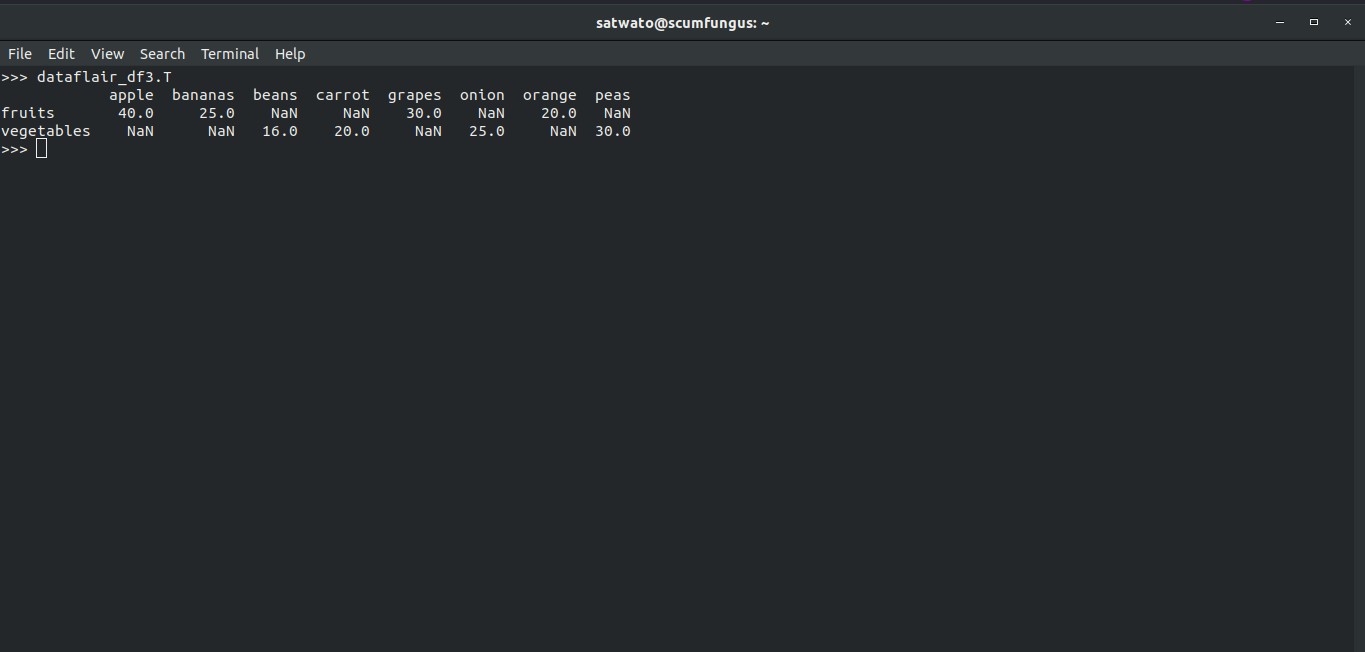
We can easily Transpose a Dataframe using the following method.
>>> dataflair_df3.T
Output-
11. Iterating over the Rows and Columns of Dataframe
We first make a new Pandas dataframe:
>> dataflair_new= { 'fruit': ["Guava", "Apple", "Oranges"], 'price':[40, 120, 60]}
>>> dataflair_df= pd.DataFrame(dataflair_new)
>>> dataflair_dfThen we iterate over the rows using the iterrows() function.
>>> for i, j in dataflair_df.iterrows(): ... print(i,j) ... print() ...
There are 3 ways to iterate over DataFrames, get complete details for Iteration in Pandas with example.
Output-
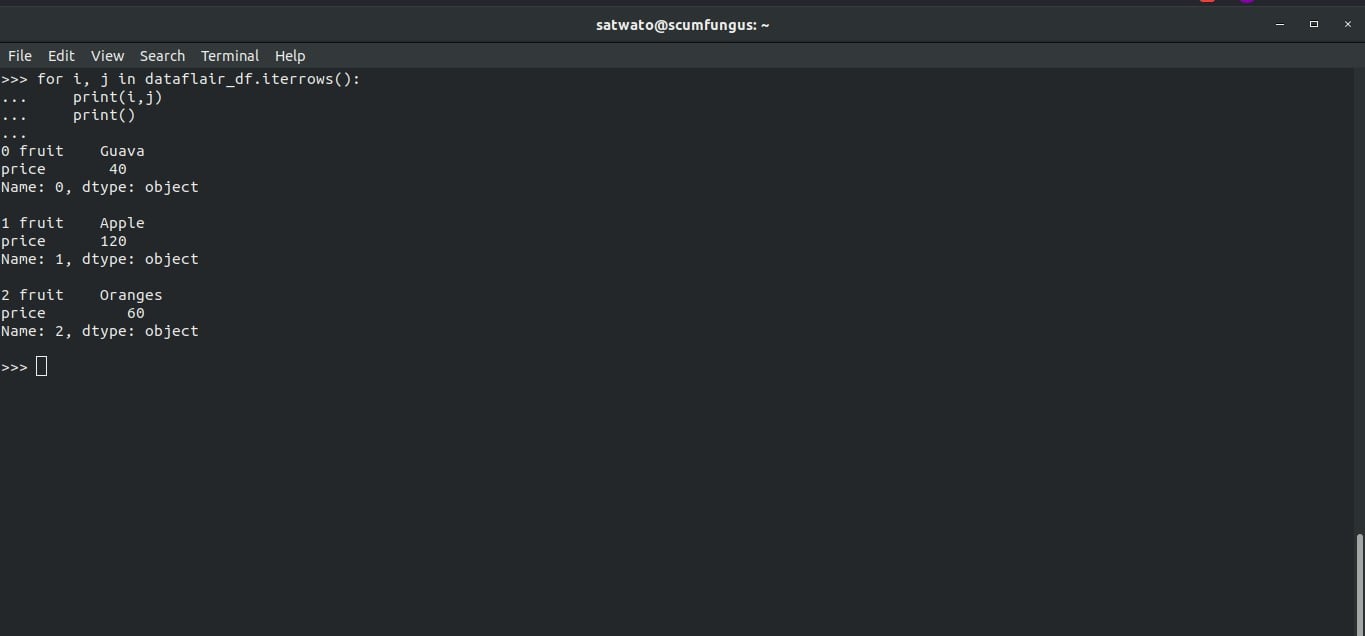
We can also iterate column-wise using iteritems() Function.
>>> for i, j in dataflair_df.iteritems(): ... print(i,j) ... print() ...
Output-
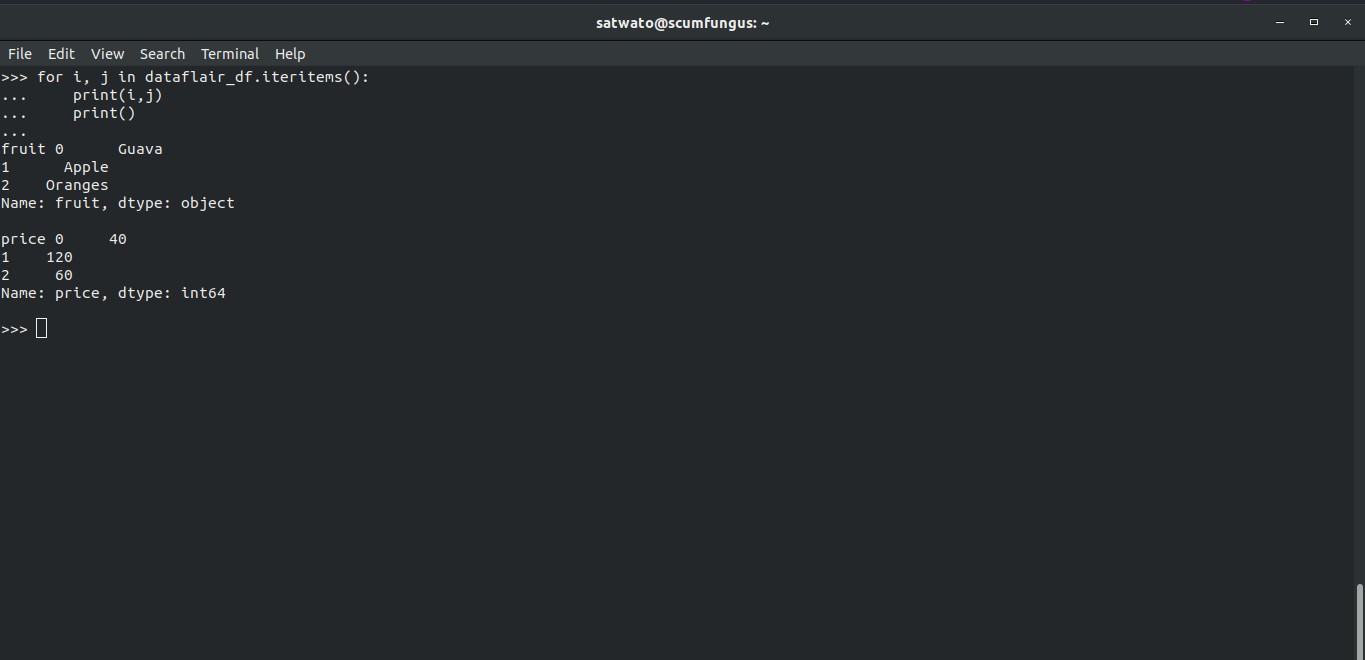
12. How to Rename a Column in Pandas DataFrames?
We can rename columns using the .rename() function.
>>> dataflair_df.rename(index=str, columns={"fruit": "a", "price": "c"})In the parameters of the .rename function, we have declared a dictionary stating the change we want. The original name is mentioned as a key of the dictionary and the desired change is given as the value to that key.
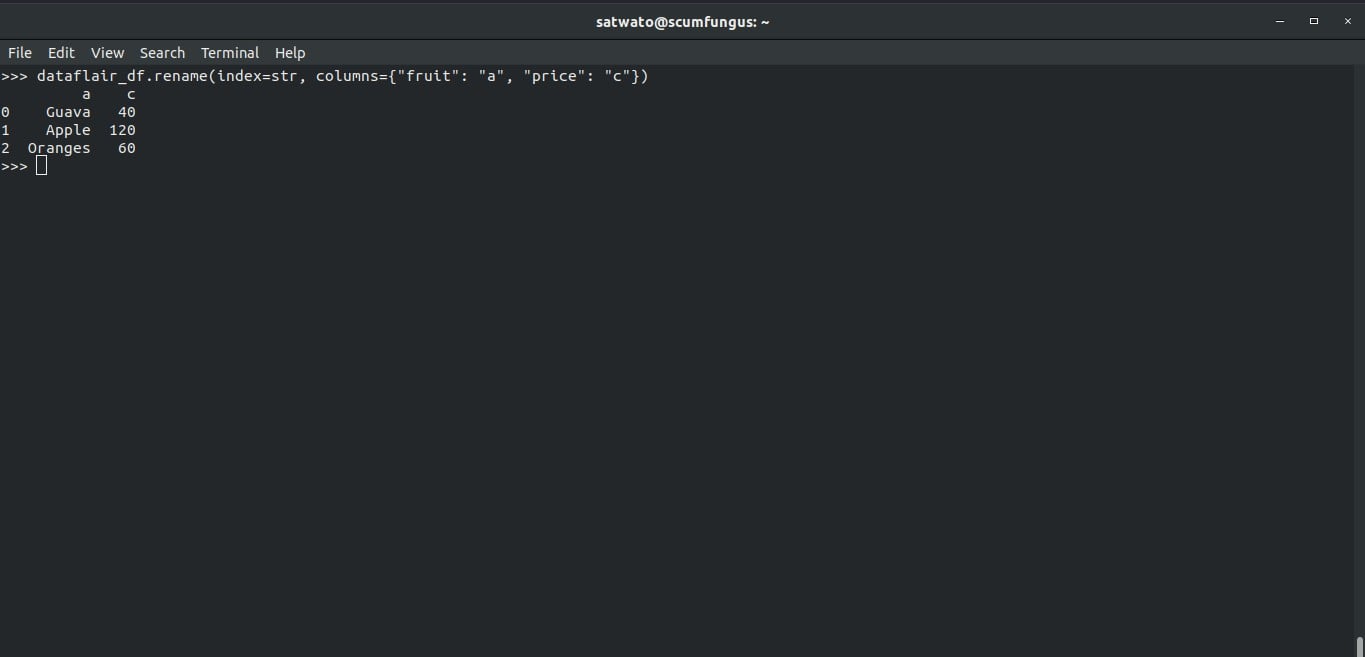
13. Stacking and Unstacking of DataFrames
Using the .stack() function we can get a long version of a wide table dataframe.
>>> dataflair_st=dataflair_df.stack() >>> dataflair_st
Output-
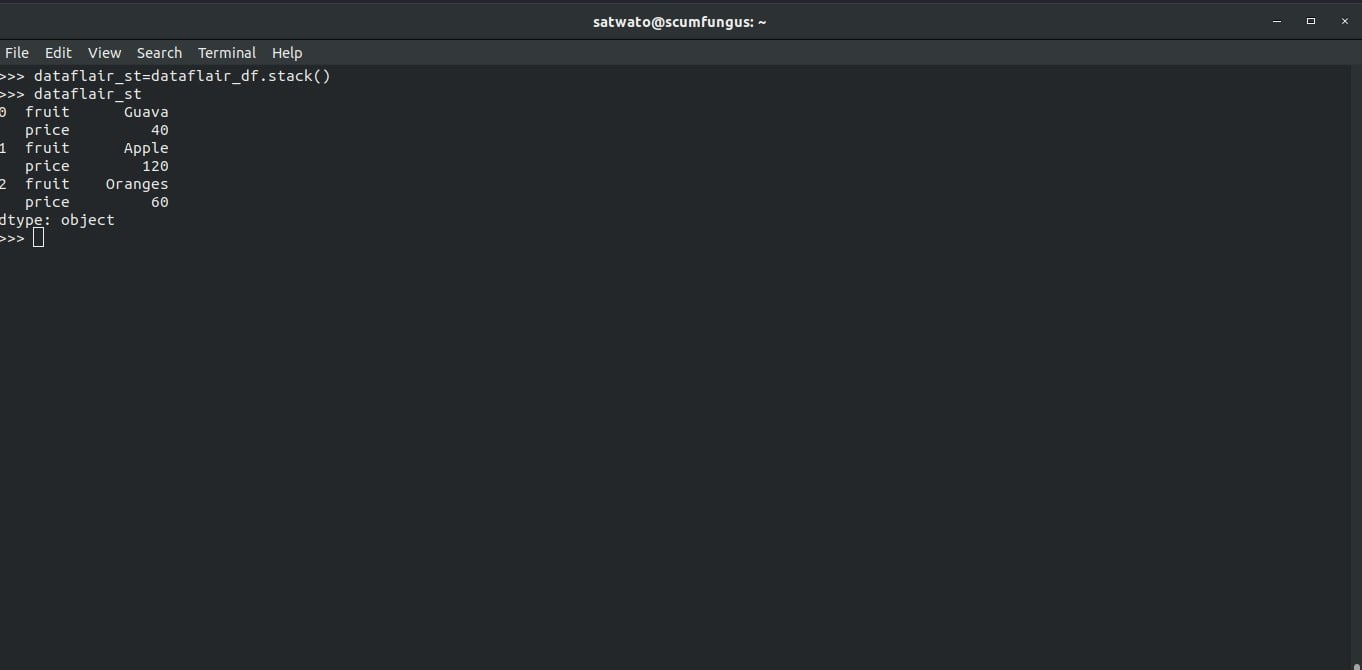
We can unstack this stacked data using the .unstack function.
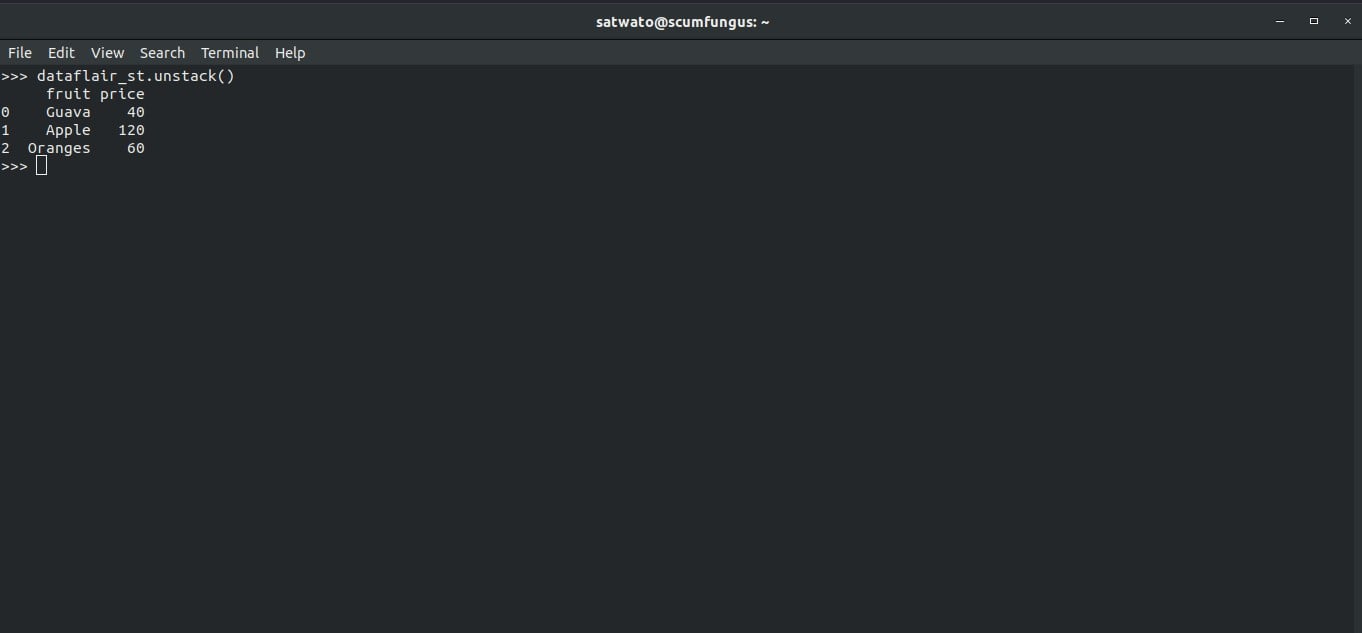
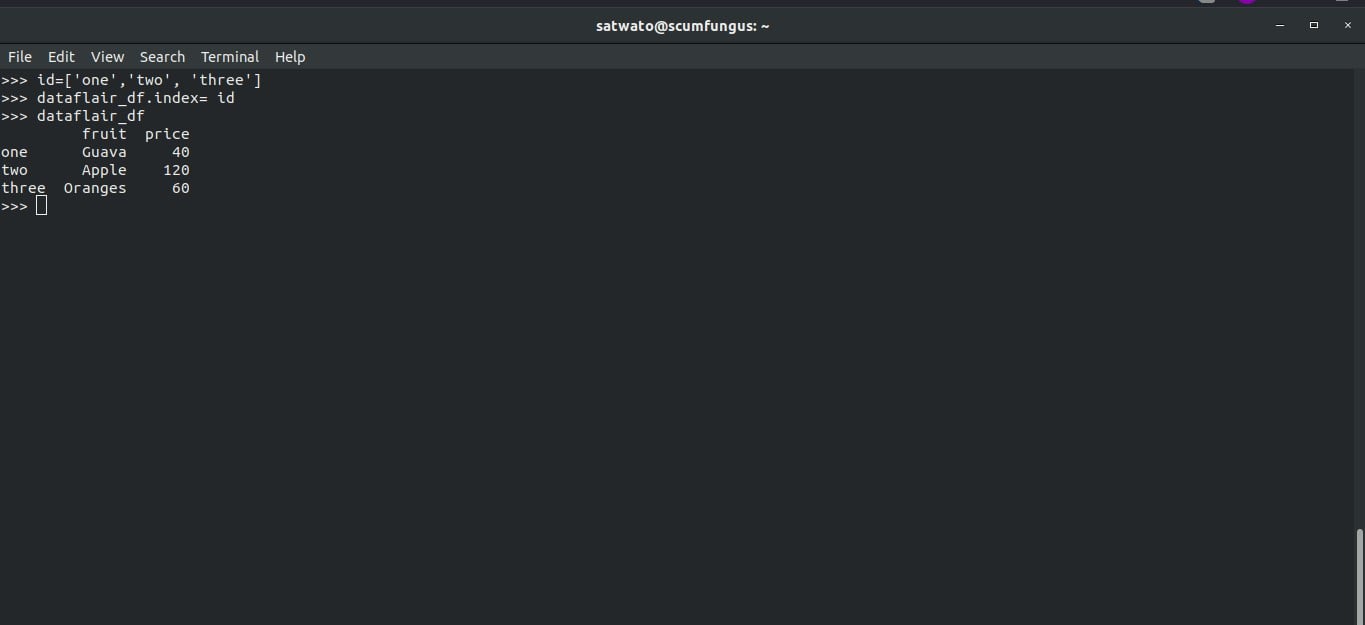
14. Setting a List as an Index in Pandas DataFrames
We can set a python list to be the index for the dataframe. But we need to make sure that the list contains the same number of elements as the number of indices already present in the DataFrame.
>>> id=['one','two', 'three'] >>> dataflair_df.index= id >>> dataflair_df
Output-
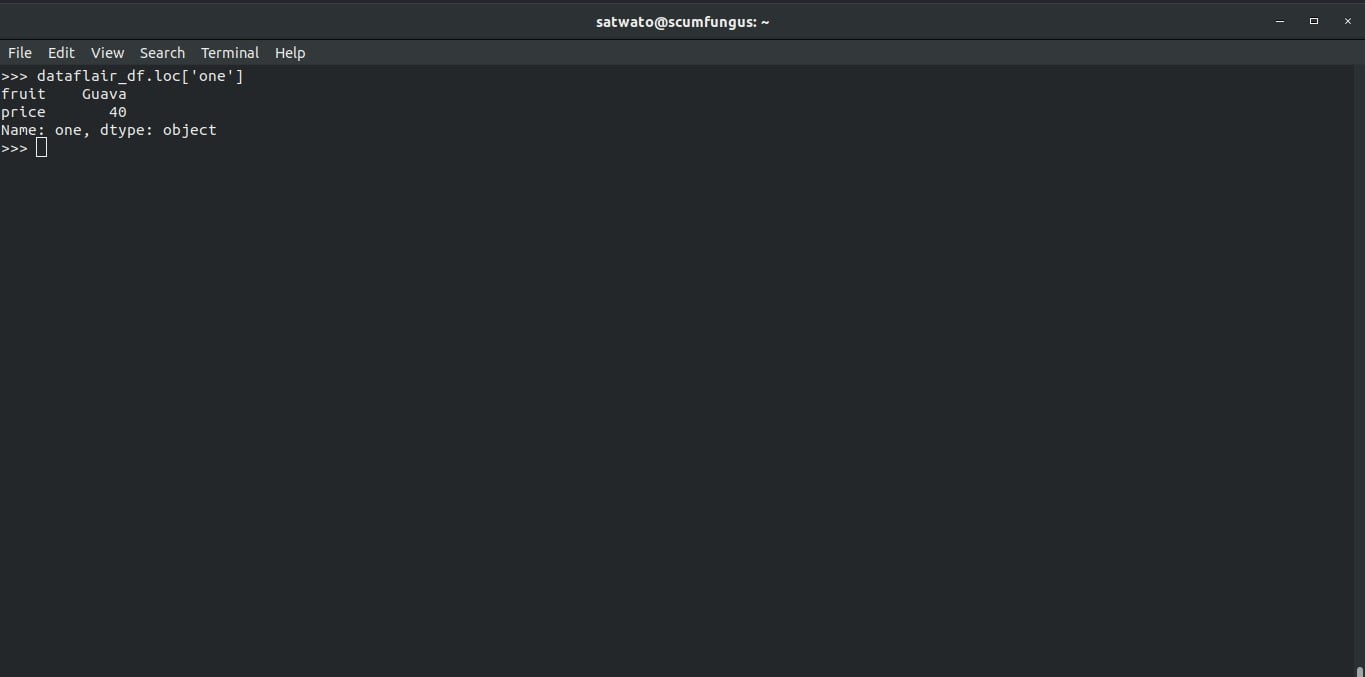
15. Selecting values from a DataFrame according to index
We can use the .loc[] function to select data from a Dataframe according to index.
>>> dataflair_df.loc['one']
Output-
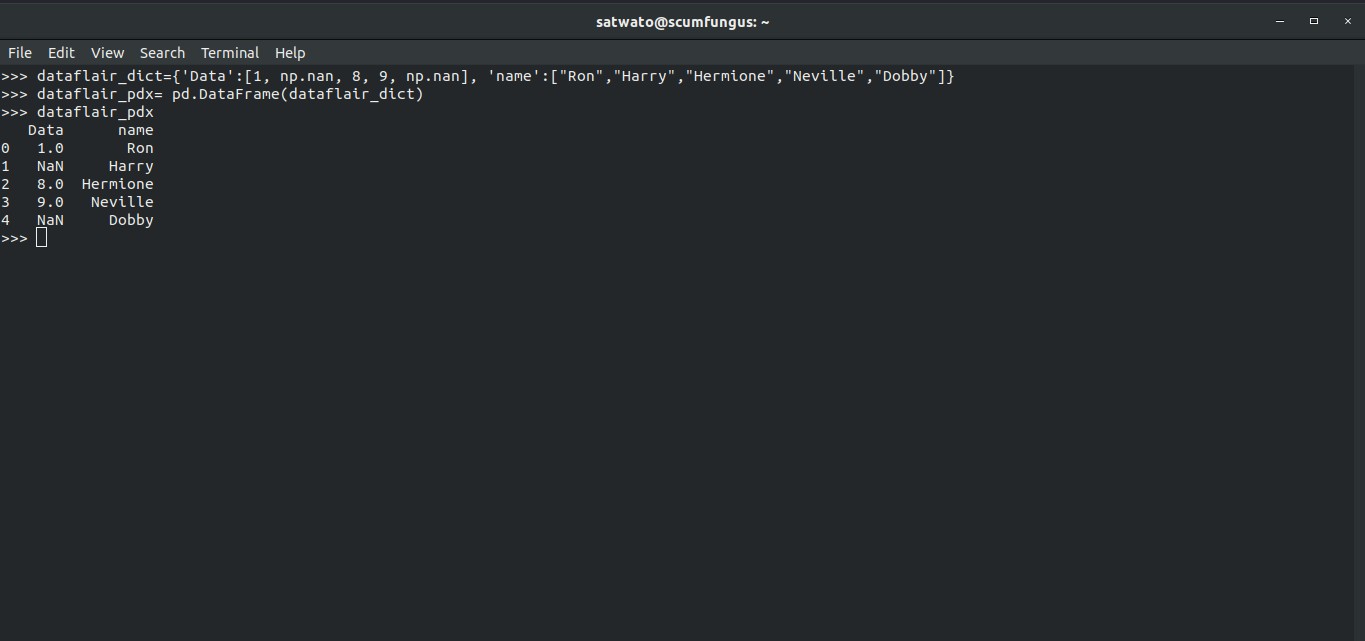
16. Working with Missing Values
Missing values in Pandas Dataframes are represented using NaN. There are methods to work around such missing data to make a more optimized dataset
Create a dataset like the following:
>>> dataflair_dict={'Data':[1, np.nan, 8, 9, np.nan], 'name':["Ron","Harry","Hermione","Neville","Dobby"]}
>>> dataflair_pdx= pd.DataFrame(dataflair_dict)
>>> dataflair_pdxOutput-
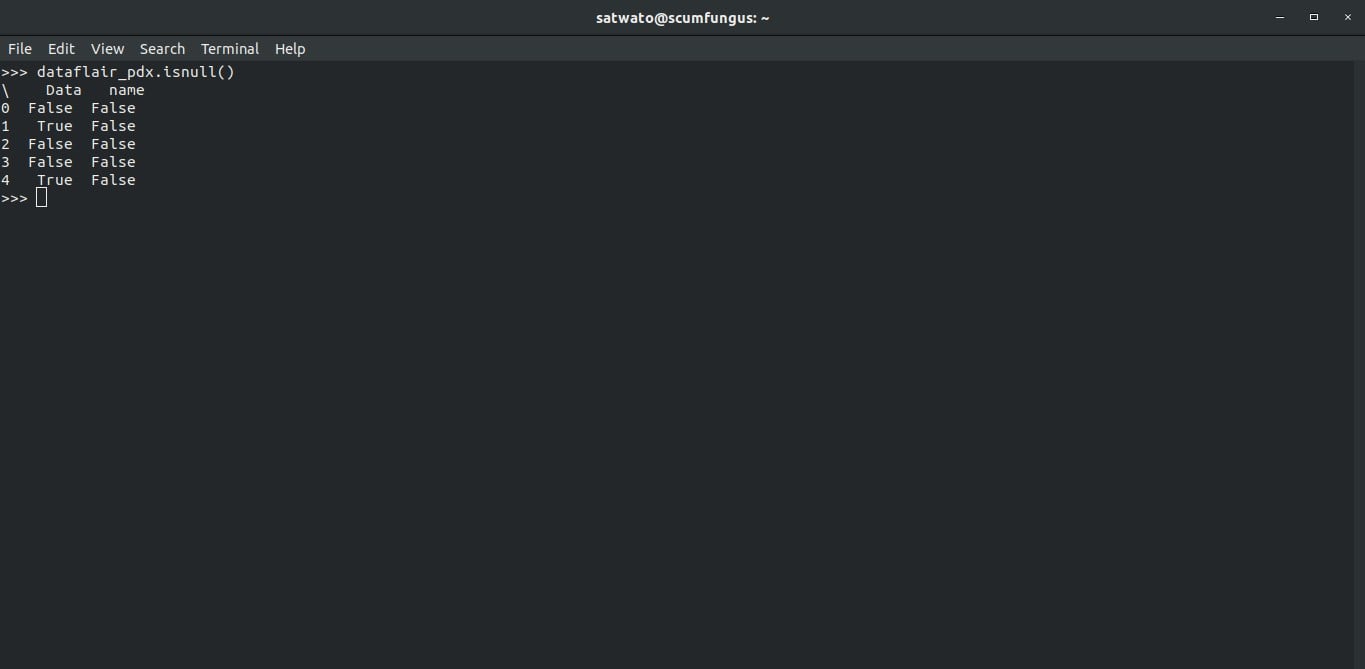
We can generate a boolean table which gives us the value True for every data which is missing.
>>> dataflair_pdx.isnull()
Output-
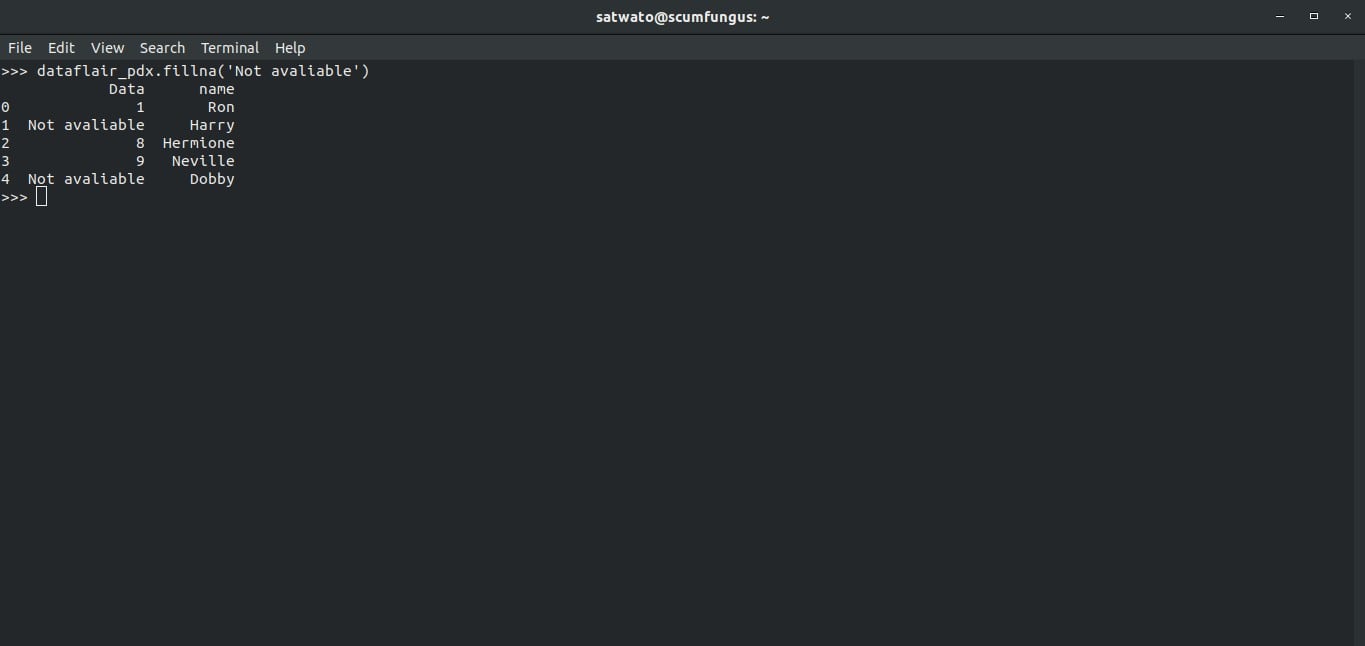
To replace the missing data with a constant value of our choice, we use .fillna()
>>> dataflair_pdx.fillna('Not avaliable')Output-
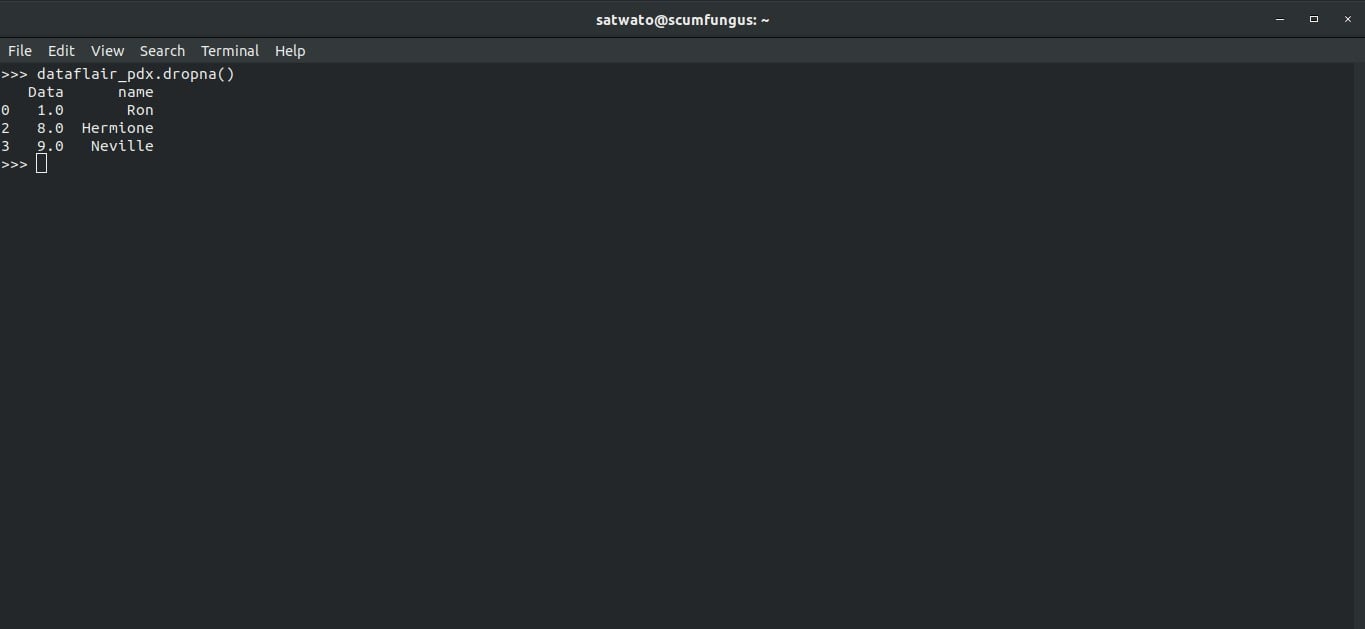
We can drop all data which is missing using .dropna() function
>>> dataflair_pdx.dropna()
Output-
17. Summary
We have gone through all the different functions and capabilities of a DataFrame. This is a very essential part of the Pandas Library and it is absolutely necessary to understand all the things taught.
Don’t forget to check the latest Applications of Pandas in real-world.
Comments are the best way to present your feedback. Therefore, don’t forget to comment below.
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google





Hi i am interested in big data course