Keras Multi-GPU and Distributed Training Mechanism with Examples
Machine Learning courses with 100+ Real-time projects Start Now!!
Keras is a famous machine learning framework for most of the data science developers. In this DataFlair Keras Tutorial, we will talk about the feature of Keras to train neural networks using Keras Multi-GPU and Distributed Training Mechanism. Keras has the ability to distribute the training process among multiple processing units.
Multi-GPU and Distributed Training in Keras
Keras is a python open-source neural network library. It enables experimentation and provides ease or writing code. It provides almost all the layers, optimizers, and activation functions to create neural networks.
For training distribution, Keras focuses on minimal changes in the existing model and code. This distribution of computation generally work in two ways:
1. Keras Model Parallelism
Here we train the same model on different devices by distributing the model into different parts. To distribute computation in this way, the model must be large and we have to be very careful while splitting the model.
Suppose we want to train our deep learning model using 5 GPUs. We would distribute 5 layers to GPU 1, 5 layers to GPU 2 and like that till the last GPU.
2. Keras Data Parallelism
We use this technique when we have insufficient memory to load the data points. The dataset is very big to be fit in the memory, so we divide the dataset into several batches. We train different batches of datasets on different GPUs. Since Keras Multi-GPU may have different speeds, this technique is asynchronous.
Now let’s see how to distribute computation using Keras and TensorFlow. We will look at ways to perform model parallelism and data parallelism.
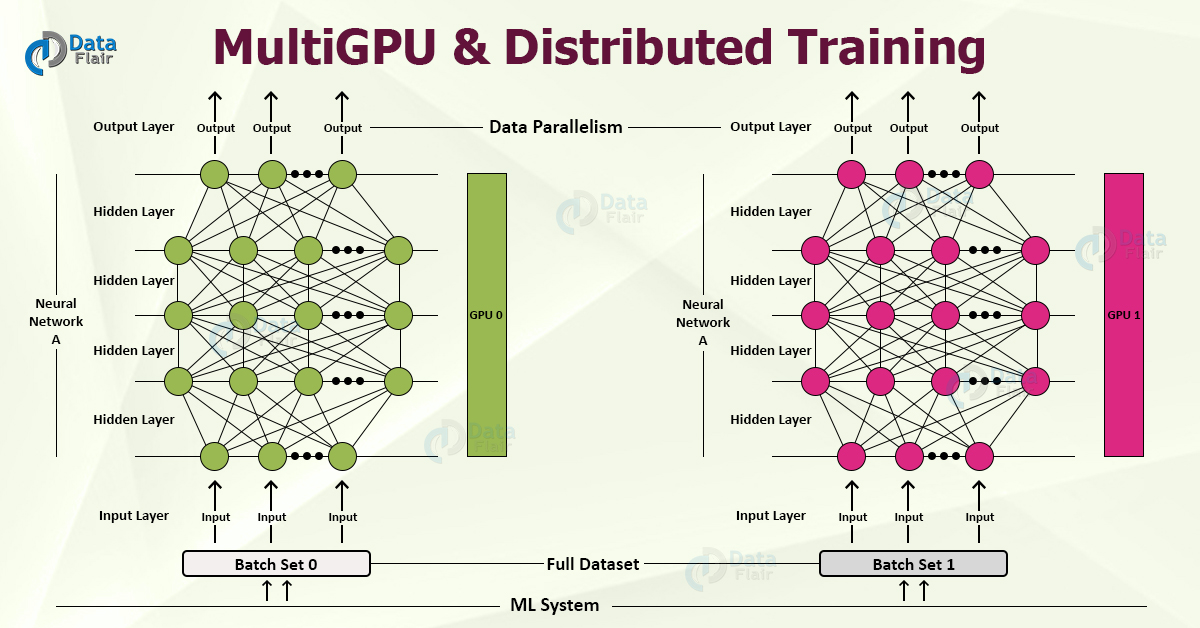
Image source: FrankDenneman.nl
Model Parallelism Example in Keras
Here we are trying to distribute training in three parts. In the following code, our model has some parts on GPU0, some on GPU1 and rest on GPU2. This is an example of a three-way model parallelism.
with tf.device(“/gpu:0”): x=tf.Variable(tf.ones(())) x=tf.square(x) with tf.device(“/gpu:1”): y=tf.Variable(tf.ones(())) y=tf.square(y) with tf.device(“/gpu:2”): l=x+y optimizer=tf.train.GradientDescentOptimizer(learning_rate=0.1) optimize_train=optimizer.minimize(l) session=tf.Session() session.run(tf.global_variables_initializer()) loss,sam=session.run([l,optimize_train])
Now we’ll make use of TensorFlow’s Mirror Strategy API available in the distribute module.
Data parallelism using Mirrored Strategy API, TensorFlow
The following is an example of a single host, multi-device synchronous training.
tf.distribute.MirroredStrategy is used for in-graph replication and perform training of multiple GPUs synchronously.
This API keeps an abstraction for training distribution among multiple processing units. This API copies model’s parameters to each and every GPU. Then it combines the gradients from all the GPUs, gets a combined value, and applies it to all copies of the model.
Sample example, how to use tf.distribute.MirroredStrategy:
- First, we need to instantiate the MirroredStrategy API. We can customize the computing devices we want to use. This strategy will use all the GPUs available by default.
- After instantiating, we need to create and compile the Keras model inside a scope using the previous strategy object.
- Finally, train the model using fit().
strat = tf.distribute.MirroredStrategy()
To print the number of devices available for training
print(strategy.num_replicas_in_sync)
Create the strategy scope for creating model and compile model
with strategy.scope():
Everything that creates variables should be under the strategy scope. In general this is only model construction & `compile()`.
model = CreateModel(...) model.compile(...)
Training the model on all available GPUs.
model.fit(x_train,y_train, ...)
Test the model on all available GPUs.
model.evaluate(x_test)
Using callbacks to ensure fault tolerance in keras
The fault-tolerance refers to recovery from failure. In this section, we are discussing strategy to ensure recovery if a failure occurs. For this purpose, we use ModelCheckpoint callback. Using ModelCheckpoint we can save our model after each n epoch counts. If the failure occurs you can continue training from the saved model.
Code to use the model checkpoint.
model_checkpoint_callback = tf.keras.callbacks.ModelCheckpoint( filepath=filepath, save_weights_only=True, monitor='val_acc', mode='max', save_best_only=True) model.fit(epochs=10, callbacks=[model_checkpoint_callback]) model.load_weights(filepath)
tf.data performance tips
This section describes the tips and best practices to ensure better efficiency of the model using tf.data pipeline.
- .cache() method:
Using this method, the data will be cached after the first iteration over the dataset. The upcoming iteration over the dataset will use this cached data. This increases model performance when the dataset is constant in each iteration or we are reading data from a remote system.
- .prefetch(size_of_buffer) method:
Using this method, we can train on a dataset asynchronously. It prefetches the next batch of the dataset in GPU after the training of the current batch is over.
Multiworker Distributed Synchronous Training
Multi Worker here refers to multiple computer machines. Each machine runs a copy of the model, the variables are synced after each batch.
We set up a cluster of machines. Each machine may have the same or different number of GPUs. Each machine has a config file TF_CONFIG which tells the machine its role. TF_CONFIG also tells the machine how to communicate with other machines. We create a scope of MultiWorker Mirrored Strategy on each machine. Then we compile and run code on each machine after creating scope.
Summary
This article talks about Keras Multi-GPU and features of Keras to distribute training on multiple GPUs. We discuss two different ways to perform distribution, model parallelism, and data parallelism.
In general, we use data parallelism. This article then explains examples to perform model and data parallelism. We saw two ways, one using TensorFlow’s mirrored strategy and other for model parallelism by creating three different sessions. Afterwards, this article describes callback to ensure tolerance, performance tips, and multi-worker distributed synchronous training.
If you are Happy with DataFlair, do not forget to make us happy with your positive feedback on Google




