5 Important Cassandra Features That You Must Know
Job-ready Online Courses: Knowledge Awaits – Click to Access!
1. Objective – Cassandra Features
In our last Cassandra Tutorial, we have discussed the best books for Cassandra. In this article, we will get to know about the 5 important Cassandra Features. Cassandra is taking over a lot of organizations.
Moreover, it is becoming the most used NoSQL database. Therefore, there is a need to learn about the Features of Apache Cassandra as well.
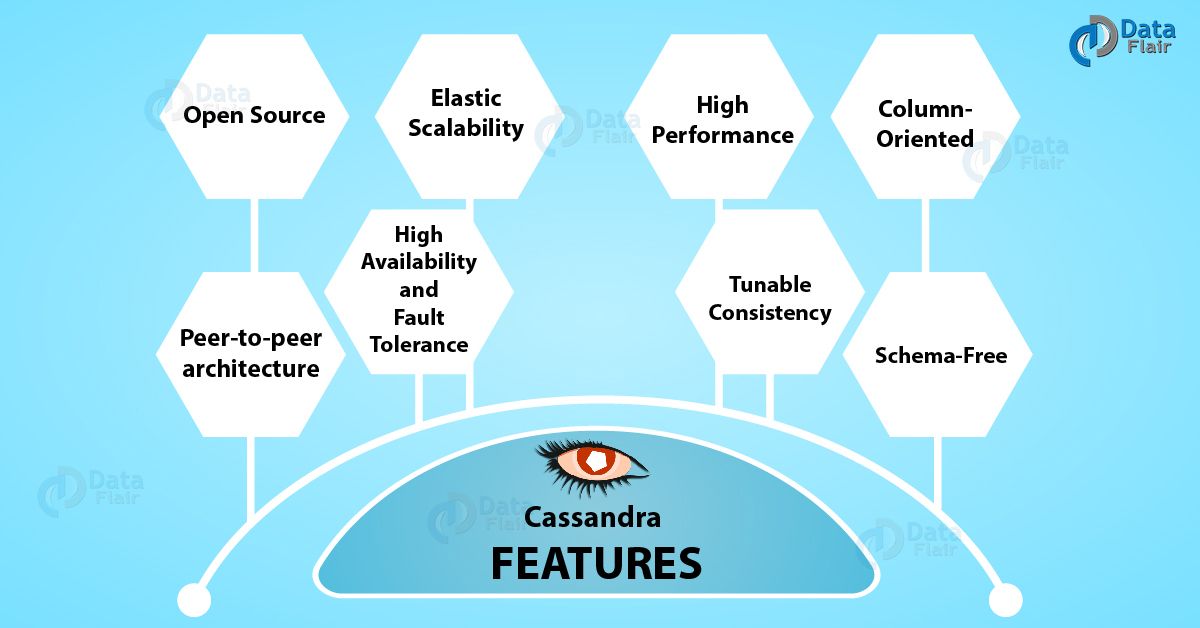
5 Important Cassandra Features That You Must Know
Have a look at mostly used Cassandra Applications
2. Top Cassandra Features
Here are 5 important Cassandra Features:
a. Open Source

Cassandra Features – Open Source
For a human, the price of a product place an important role. Cassandra, though it is very powerful and reliable, is FREE! It is an open source project by Apache. Because of the open source feature, it gave birth to a huge Cassandra Community, where people discuss their queries and views.
Furthermore, there is a possibility of integrating Cassandra with other Apache Open-source projects like Hadoop, Apache Pig, Apache Hive etc. This is the first and an important Cassandra feature.
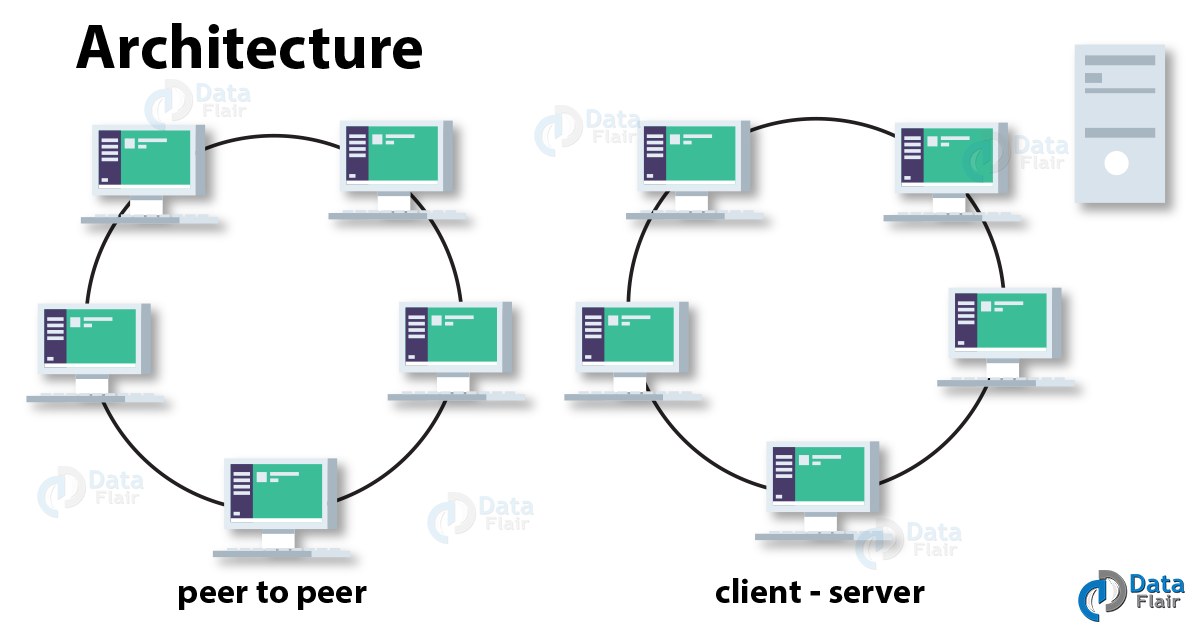
b. Peer-to-peer Architecture
Some databases work on master-slave architecture in Cassandra and some work on peer-to-peer.
Cassandra features – Peer-to-peer architecture
In master-slave architecture, there is the main unit and the rest communicate with that unit. Whereas, in a peer-to-peer architecture, several units communicate with each other. Apache Cassandra follows peer-to-peer architecture.
Therefore, there is no single point of failure. Also in any of the data centers, we cannot add a specific number of nodes to any cluster. Cassandra has a robust architecture with exceptional characteristics.
Let’s take a look at Cassandra Data Model
c. Elastic Scalability
Elastic Scalability is one of the biggest advantages. That is, you can easily scale-up or scale-down the cluster in Cassandra. There is a flexibility for adding or deleting any number of nodes from the cluster without disturbances.
That is, there is no need of restarting the cluster while scaling up or scaling down. Because of this, Cassandra has a very high throughput for the highest number of nodes.
Moreover, there is zero downtime or any pause during scaling. Hence read and write throughput increases simultaneously without delay.
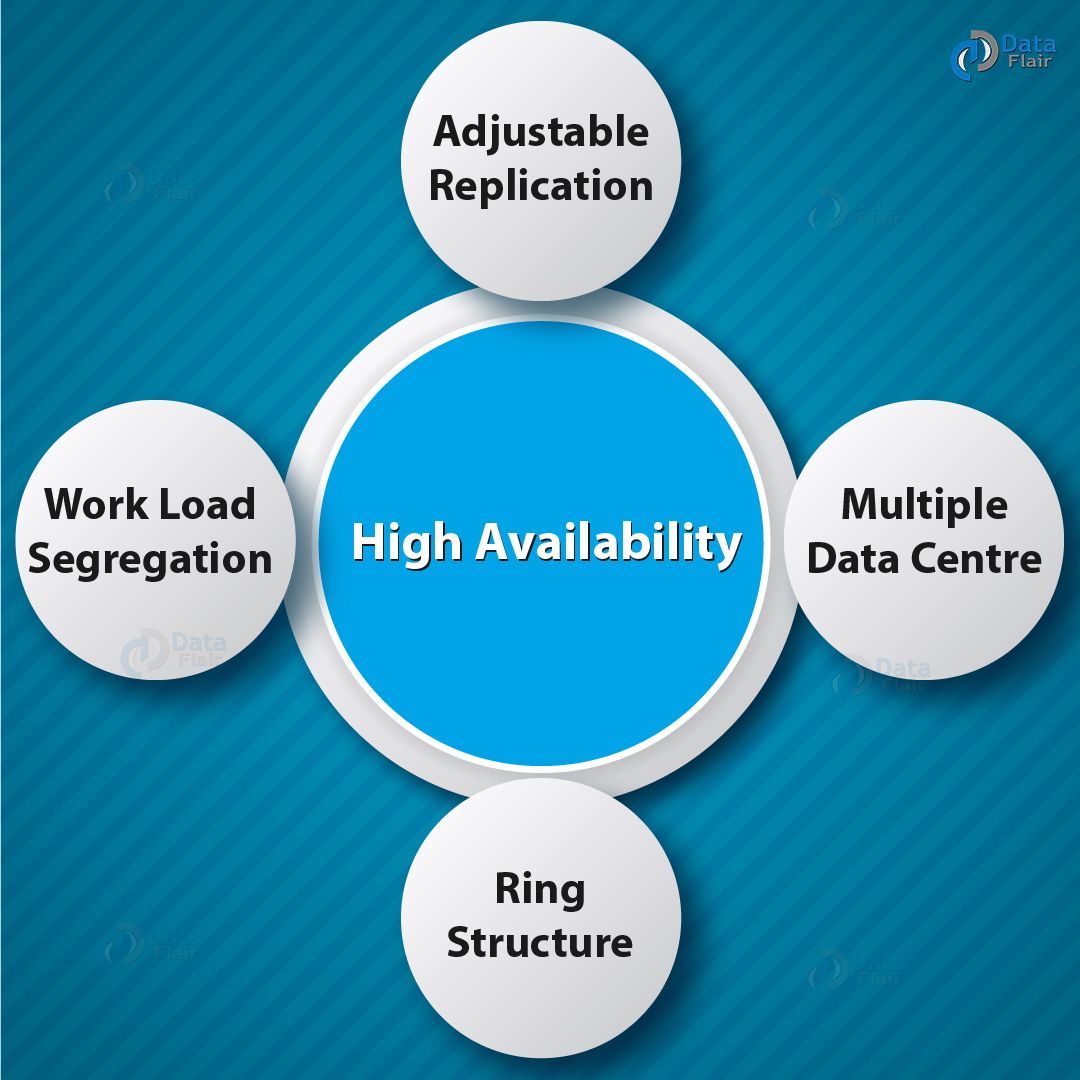
d. High Availability and Fault Tolerance
Data Replication is the storage of data at multiple locations.
Cassandra Features – High Availability
Do you know about Cassandra Curd Operation
Because of data replication, Cassandra is highly available and fault tolerant. Basically, if one node fails, the data is readily available in different nodes. Therefore, we can retrieve the data from those nodes. The user sets the number of replication.
According to that number, you can replicate each row in a cluster based on the row key. Data replication can be across multiple data centers. Evidently, this leads to high-level back-up and recovery competencies.
e. High Performance
Cassandra database has one of the best performance as compared to other NoSQL database.
Cassandra Features – High Performance
You must know about Cassandra Documented Shell Commands
Developers wanted to utilize the capabilities of many multi-core machines. This is the base of development of Cassandra. Cassandra has proven itself to be excellently reliable when it comes to a large set of data.
Therefore, Cassandra is used by a lot of organizations which deal with huge amount of data on a daily basis. Furthermore, they are ensured about the data, as they cannot afford to lose the data.
f. Column-Oriented
Cassandra’s data model is column-oriented. In other databases, column name contains metadata, whereas, columns in Cassandra also contain actual data. In Cassandra, columns are stored based on column names. Therefore, there are a number of columns contained in rows.
Do you know Cassandra Data Definition Command
g. Tunable Consistency

Cassandra Features – Tunable Consistency
Basically, there are two types of consistency in Cassandra, Eventual consistency and Strong Consistency. The developer can choose any of them according to his requirement. As soon as the cluster accepts the write, eventual consistency makes it sure that the client approves.
Whereas, Strong consistency make sure that any update is broadcasted to all the nodes or machines where the particular data is suited. Moreover, the mixture of the two consistency is also a possibility.
h. Schema-Free
There is a flexibility in Cassandra to create columns within the rows. That is, Cassandra is known as the schema-optional data model. Since each row may not have the same set of columns, there is no need to show all the columns needed by the application at the surface.
Therefore, Schema-less/Schema-free database in a column family is one of the most important Cassandra features.
Let’s discuss Cassandra vs RDBMS
So, this is all about Cassandra Features. Hope you like it.
3. Conclusion – Cassandra Features
Hence, in this article, we have covered the key Features of Cassandra. Moreover, we learned about the different features as open source, peer-to-peer architecture, elastic scalability, high availability and fault tolerance, high performance, column-oriented, tunable consistency, and schema-free.
Furthermore, if you have any query, feel free to ask in a comment section.
See also-
Cassandra Collection Data Types
For reference
If you are Happy with DataFlair, do not forget to make us happy with your positive feedback on Google





I see 8 features