Cassandra Data Model | How Cassandra Stores Data
Placement-ready Courses: Enroll Now, Thank us Later!
1. Objective
In our last Cassandra article, we discussed Apache Cassandra Architecture. In this Cassandra tutorial, we will learn about the Cassandra Data Model. It is different from other DBMS. Data Model of Cassandra is basically the way a technology stores data.
Moreover, this article will teach us how Cassandra stores data. Also, in this Cassandra data model tutorial, we will see Cassandra Cluster and Cassandra Keyspace.
So, let’s begin the Cassandra Data Model.

Cassandra Data Model | How Cassandra Stores Data
2. Cluster in Cassandra Data Model
In Cassandra Data model, Cassandra database stores data via Cassandra Clusters. Clusters are basically the outermost container of the distributed Cassandra database. The database is distributed over several machines operating together.
Every machine acts as a node and has their own replica in case of failures. These nodes are arranged in a ring format as a cluster.
3. What is Cassandra Keyspace?
In the Cassandra Data Model, Cassandra Keyspace is a container for data. It contains many attributes. The basic attributes are:-
a. Replication Factor
It basically signifies the number of copies of a data. In other words, the number of nodes in a cluster that are copies of a data.
Apache Cassandra Books: Best Books To Learn Cassandra
b. Replica Placement Strategy
It replicates the data in a Cassandra Cluster. There are two types of strategies, namely:
- Simple Strategy (for single data center)
- Network Topology Strategy (for multiple data centers).
c. Cassandra Column Families
Column Family in Cassandra is a collection of rows, which contains ordered columns. They represent a structure of the stored data. These Cassandra Column families are contained in Keyspace. There is at least one Column family in each Keyspace.
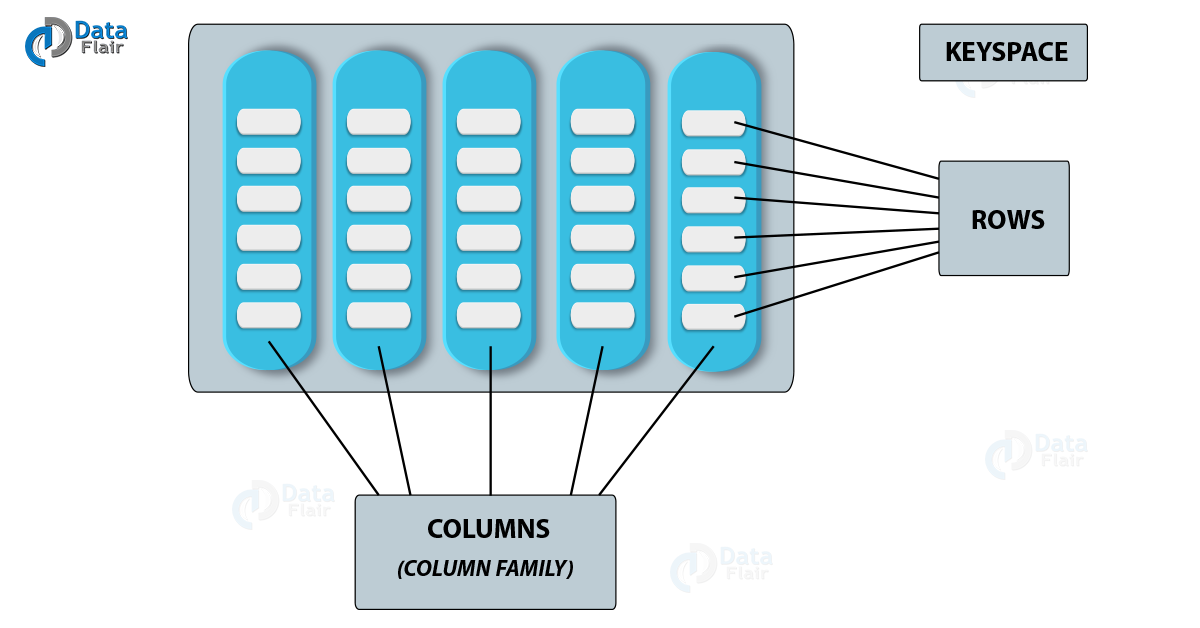
Cassandra Data Model- Column Family in Cassandra
The rows in each column are once again the collection of many columns. The columns are the basic unit of the data structure in Cassandra. Columns have three values stored in them. They are key or columns name, timestamp and value.
Furthermore, the columns in these rows can be added or removed as the requirement of the user. Whereas the Cassandra column families are predefined and hence, cannot be changed. There is also a super column family and that super Column family is Table with a collection of many columns.
It increases the efficiency of a program. It groups all the columns used regularly as binds them in a single space.
Let’s revise Cassandra Documented Shell Commands
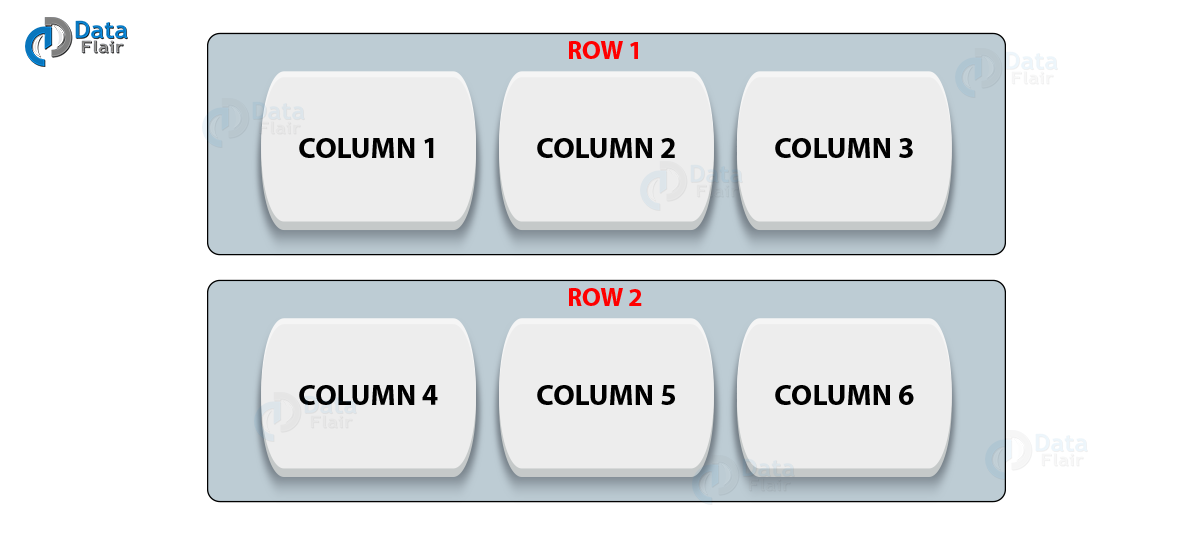
Cassandra Data Model- Rows in Cassandra Column Family
Cassandra Column family has many attributes some of them are:
i. Keys cached
Number of locations to keep cached per SSTable.
ii. Rows cached
A number of rows whose content will be cached in memory.
iii. Preload row cache
Gives you an option to pre-populate the row cache.
Learn Apache Cassandra API
So, this was all about the Cassandra Data Model. Hope you like our explanation of how to store data in Cassandra.
4. Conclusion: Cassandra Data Model
Hence, we understood the data model of Cassandra. Moreover, we saw Cassandra Cluster and Cassandra Keyspace and its attributes. At last, we discussed the replication factor, the replica placement strategy, and Cassandra Column family in detail.
In our next article, we will go through the Data types used in Cassandra. Furthermore, if you have any query, feel free to ask in the comment section.
See also –
Cassandra Curd Operation
You give me 15 seconds I promise you best tutorials
Please share your happy experience on Google





Hi
How much fast cassandra is while writing, reading and processing it and again writing into database compare to hbase.
Consider a scenario where I am writing data into database daily basis. Then by weekly or monthly I want to read the data, process it and write into database. Here I wanted to know is cassandra fast enough to processing and writing as compare to HBASE.