Word2Vec: TensorFlow Vector Representation Of Words
Machine Learning courses with 100+ Real-time projects Start Now!!
In this TensorFlow article “Word2Vec: TensorFlow Vector Representation Of Words”, we’ll be looking at a convenient method of representing words as vectors, also known as word embeddings.
Moreover, in this TensorFlow word embedding tutorial, we will be looking at scaling with noise-induced training & Word2Vec skip gram model, Along with this, we will discuss how to build graph and training for TensorFlow Word2Vec and also examples of Word2Vec in TensorFlow.
So, let’s start Word2Vec in TensorFlow.
Vector Representation of Words
Most of the models that you’ll work with will have high-dimensional vectors of datasets ranging from pixel values in raw images to power densities in audio tracks.
Now, all the useful information that your image and audio recognition models will need is in this raw data whereas, in the case of working with natural language processing, words are treated as symbols, a Word2Vec example being ‘cat’ that is taken as Id537 and ‘dog’ as Id143.
This allotment is random and provides no information if the data is interrelated. Therefore, representing words as individual identities may lead to sparsity in the dataset, which increases the need for more data for your model. Vector representation of data can, therefore, let you tackle these problems.

Word2vec- (Word Embedding)
The distribution hypothesis, tells that the choice of words in the same context share a common meaning and this can be used by dividing the approach into two categories:
- Count-Based Methods (e.g. Latent Semantic Analysis), and
- Predictive Methods
To say it in simple terms, the former calculates the frequency with which the word occurs repeatedly with its neighbors and then maps this count to a dense vector for every input. On the other hand, the latter tries to predict the word from its neighbors using dense vectors which are the parameters of the model.
Scaling with Noise-Induced Training
The maximum likelihood principle in TensorFlow Word2Vec can be used to maximize the predictability of the next word with a conditional probability where the previous words are given using a softmax regression,
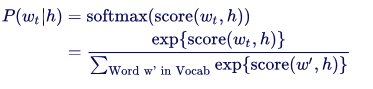
Scaling with Noise-Induced Training
We train the model by maximizing its log-likelihood,
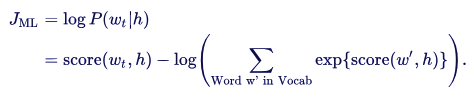
Word2vec
This results in a normalized model but turns out to be costly, since you need to calculate and normalize each probability using the score for all words, at every step of the training.
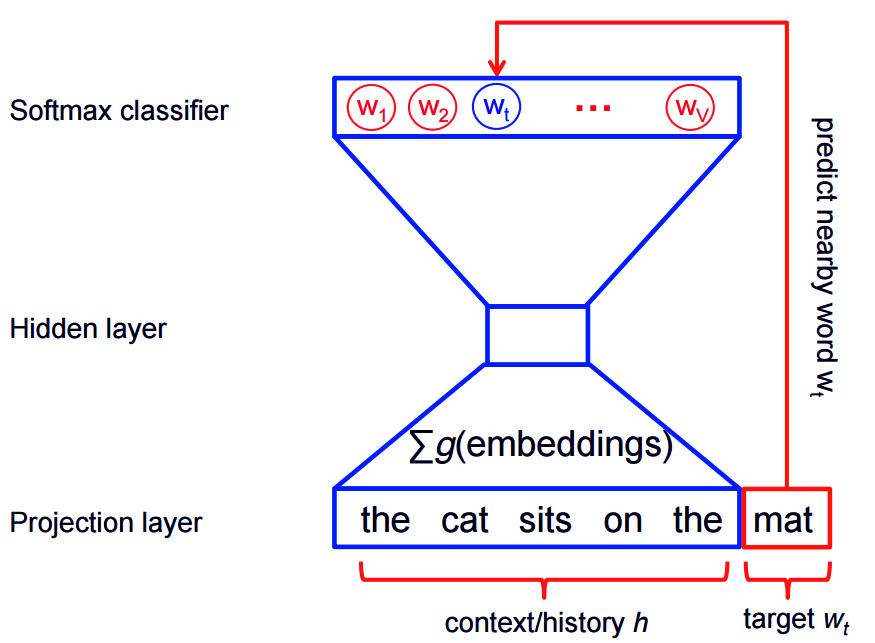
Vector Representation Of Words – Normalised model
The good thing is that for feature learning we do not need a full probabilistic model in Word2Vec. The two models, CBOW and skip-gram, are rather trained by binary classification technique to differentiate the target words from the noise.
The figure given below shows the same for the CBOW model and it can be inverted for the skip-gram model.
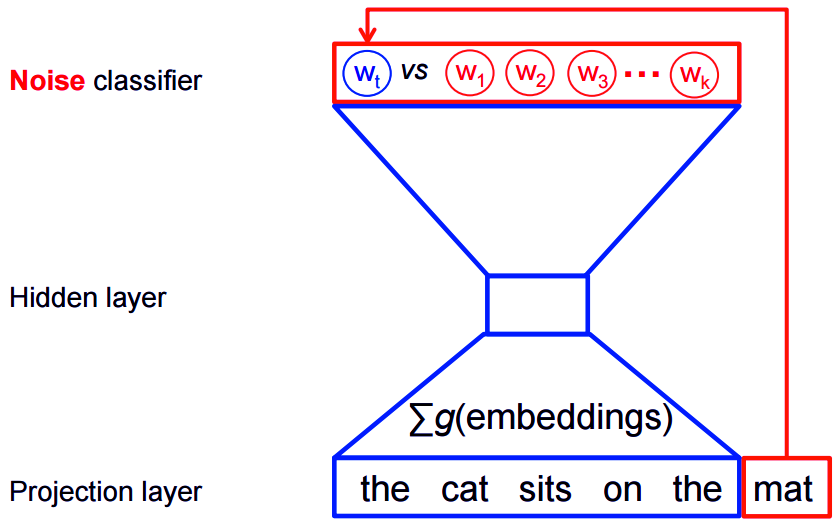
Word2vec CBOW Model – Binary Classification Technique
You can use the estimation loss for noise, with the function tf.nn.nce_loss().
Word2Vec Skip Gram Model
Consider the dataset
The quick brown fox jumped over the lazy dog
Context, here in the scope of this TensorFlow Word2Vec tutorial is defined as the words that fall right at the adjacent sides of a target word.
([the, brown], quick), ([quick, fox], brown), ([brown, jumped], fox), …
As you are already aware skip-gram model does the inverting and tries to predict from the target word, so the prediction goes like ‘the’ and ‘brown’ from ‘quick’, ‘quick’ and ‘fox’ from ‘brown’, etc.
(quick, the), (quick, brown), (brown, quick), (brown, fox), …
Let’s do the training, where the aim is to predict the form quick. You can draw a noise distribution, P(w) using the function initialized with num_noise=1 and let us say that you select sheep as the noisy example.
Now it’s time to update the word embedding parameters to improve the main function by calculating the gradient with respect to the parameters θ. You take small steps towards the gradient and thus updating the embeddings.
The visualization is done by projecting the vectors to 2D using a dimensionality reduction technique. If you look at these visualizations, you will notice that these vectors possess some useful information about words and they’re interconnectedness.
For example, pairs of male-female, verb tense or country-capital relationships.
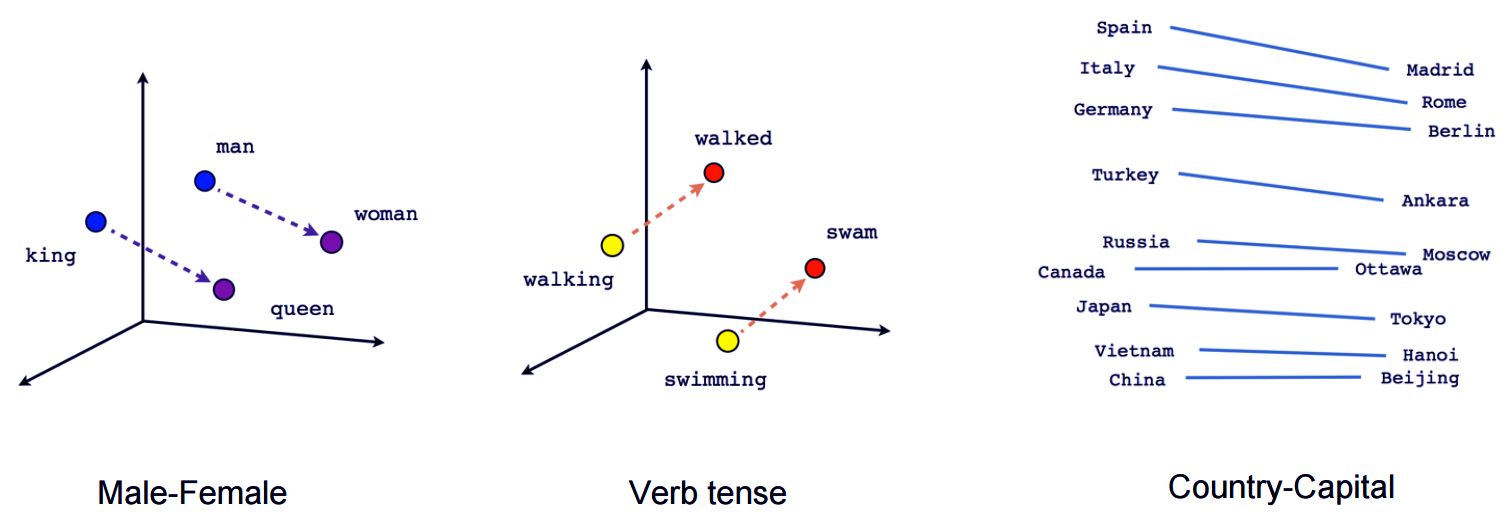
Vector Representation Of Words
Building the Graph of Word2Vec in TensorFlow
You should start with defining the embedded matrix which is really random as shown below.
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))We use a logistic regression model in the vector representation of words to define the estimation loss. Therefore, defining the weights and biases, the code looks like:
nce_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))You can now define skip-gram model graph which will take two inputs, the first one is a group of discrete integers representing the context words and the other input for the target words. Creating the placeholders, the code looks like the following:
train_inputs = tf.placeholder(tf.int32, shape=[batch_size]) train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1]) embed = tf.nn.embedding_lookup(embeddings, train_inputs)
By now, you’ll be having the embeddings for each word and you can now predict the target word.
loss = tf.reduce_mean(
tf.nn.nce_loss(weights=nce_weights,
biases=nce_biases,
labels=train_labels,
inputs=embed,
num_sampled=num_sampled,
num_classes=vocabulary_size))This will create a loss node, and add more nodes for gradient computation and parameter updation. You should use stochastic gradient descent to help you out.
# Using stochastic gradient descent: optimizer = tf.train.GradientDescentOptimizer(learning_rate=1.0).minimize(loss)
Training for Word2Vec With TensorFlow
Use feed_dict to put data into the placeholders and call the session tf.Session.run with the data in a loop:
for inputs, labels in generate_batch(...):
feed_dict = {train_inputs: inputs, train_labels: labels}
_, cur_loss = session.run([optimizer, loss], feed_dict=feed_dict)Visualizing the Learned Embeddings
The visualization is as shown below using t-SNE.
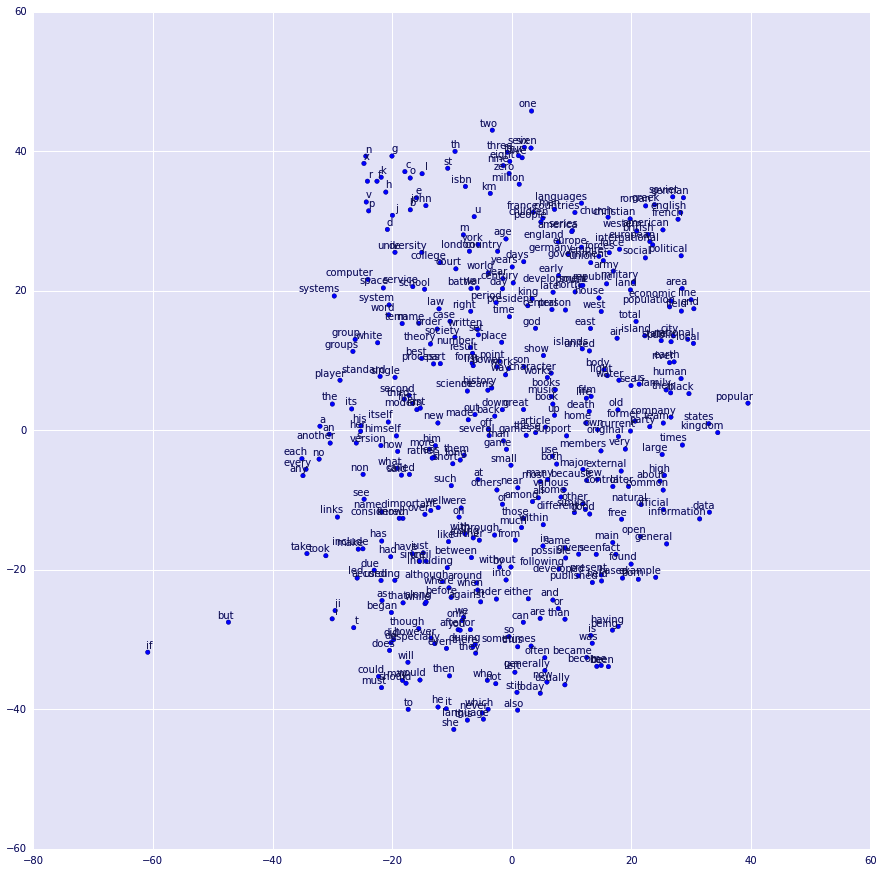
Visualizing the Learned Embeddings
If you look at it closely you will notice that words that are similar cluster near each other as expected.
Evaluating Embeddings
A simple way to evaluate embeddings is to use them to predict semantical and syntactical relationship giving a kind of analogy and thus called an analogical reasoning. A dataset is available for download from download.tensorflow.org.
build_eval_graph() and eval() functions are used to look at the evaluations.
The accuracy affects the choice of hyperparameters. Achieving a good performance requires training over a huge dataset, and you can use properties such as subsampling to get better results.
Optimization in TensorFlow
Tensorflow offers code flexibility and you can create your own loss function by writing an expression for the new objective after which the optimizer will compute the derivatives for you.
Optimization needs to make your work faster and better and you should take a look at the previous article of Tensorflow Optimization for more details.
The code used in this tutorial is simple and the speed is compromised because we use Python for reading and feeding data items. If you find your model has serious complications, we recommend implementing a custom data reader for your problem.
In the case of Skip-Gram modelling, you can take a look at model/tutorials/embeddings/word2vec.py, where it has already been done as an example.
You can always benchmark the results against each other to analyze performance improvements at each stage.
So, this was all about Word2Vec tutorial in TensorFlow. Hope you like our explanation of vector representation as words.
Conclusion
Hence, you saw what word embeddings are, why they are so useful and how to create a simple Word2Vec model. Also, we saw computing the word embeddings efficiently.
Moreover, TensorFlow offers the users flexibility for the users to experiment with their models and optimize the implementation. Lastly, we discussed Word2Vec example. Next up, is the tutorial on improving linear models using external kernel method.
Furthermore, if you have any doubt regarding Word2Vec in TensorFlow, feel free to ask through the comment section.
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google




