TensorFlow Linear Model Using Kernel Methods
Machine Learning courses with 100+ Real-time projects Start Now!!
In this TensorFlow tutorial, for TensorFlow Linear Model, we will be learning the preparation and loading of MNIST dataset. Also, we will look at how to train a simple linear model in TensorFlow.
We will get to know, how to improve the linear model which will use in TensorFlow by adding explicit kernel methods to the model. This article is for the ones who have the knowledge of kernel and Support Vector Machines(SVMs).
So, let’s start the TensorFlow Linear Model with Kernel Methods.
TensorFlow Linear Model Using Kernel Methods
Explicit kernel mappings are supported by TensorFlow for dense purposes solely. At later releases extended support will be provided by TensorFlow.
You will be using tf.contrib.learn which a is high-level API used for machine learning along with MNIST dataset. The following contents will be taught:
- Load and prepare the MNIST dataset.
- Make a linear model, train it and then evaluate it on eval data.
- How to substitute the linear model with the kernel linear model, retrain it and then evaluate it.
Preparing and Loading the MNIST Dataset
Run the following:
data = tf.contrib.learn.datasets.mnist.load_mnist()
This will load the whole dataset and as you are already aware the data is split into validation data, test data and training data.
You’ll be using validation and training data to evaluate and train the models respectively. It is a good practice to convert your data to tensors for convenient use. A function that will add operations to the TensorFlow graph could be used which will create sub-batches to be used further.
The tf.train.shuffle_batch operation converts the numpy array to a tensor, making it easier to specify the batch_size. Also, to shuffle the input for every execution, the input_fn Ops should be used. The code for doing the same is as follows:
import numpy as np
import tensorflow as tf
def get_input_fn(dataset_split, batch_size, capacity=10000, min_after_dequeue=3000):
def _input_fn():
images_batch, labels_batch = tf.train.shuffle_batch(
tensors=[dataset_split.images, dataset_split.labels.astype(np.int32)],
batch_size=batch_size,
capacity=capacity,
min_after_dequeue=min_after_dequeue,
enqueue_many=True,
num_threads=4)
features_map = {'images': images_batch}
return features_map, labels_batch
return _input_fn
data = tf.contrib.learn.datasets.mnist.load_mnist()
train_input_fn = get_input_fn(data.train, batch_size=256)
eval_input_fn = get_input_fn(data.validation, batch_size=5000)Training a Simple TensorFlow Linear Model
It is time now to start the training process. You will include tf.contrib.learn.LinearClassifier which has 10 digits represented by the 10 classes.
image_column = tf.contrib.layers.real_valued_column('images', dimension=784)
A LinearClassifier is constructed, trained and evaluated using:
import time
image_column = tf.contrib.layers.real_valued_column('images', dimension=784)
estimator = tf.contrib.learn.LinearClassifier(feature_columns=[image_column], n_classes=10)
start = time.time()
estimator.fit(input_fn=train_input_fn, steps=2000)
end = time.time()
print('Elapsed time: {} seconds'.format(end - start))
eval_metrics = estimator.evaluate(input_fn=eval_input_fn, steps=1)
print(eval_metrics)
The results are shown as follows:

In addition to experimenting with the (training) batch size and the number of training steps, there are a couple of other parameters that can be altered.
There are a variety of available optimizers from which you can choose the one which minimizes the loss. An example is given below, that creates a linear classifier that follows FTRL strategy of optimization.
optimizer = tf.train.FtrlOptimizer(learning_rate=5.0, l2_regularization_strength=1.0)
estimator = tf.contrib.learn.LinearClassifier(
feature_columns=[image_column], n_classes=10, optimizer=optimizer)
The maximum accuracy with this model turns out to be around 93%
Technical details
You will now get to know about the technical details. The use of the Random Fourier Features to map the input data is crucial to the process. It maps a vector x∈RD to x‘∈RD
via the following relation:
TensorFlow Linear Model
where,
TensorFlow Linear Model- Regression formula
with the element-wise application.
You might notice, the values of Ω and b are sampled from distributions only if the mapping satisfies the given property:
The RHS of the expression above is a Gaussian kernel function which is most widely used function in the field of ML as it measures similarity in a vector space which is higher dimensional than the original one.
Kernel Classifier in TensorFlow Linear Model
tf.contrib.kernel_methods.KernelLinearClassifier is an estimator which integrates the kernel mappings the rectilinear model.
The constructor of the estimator is identical to that of the linear classifier and has an additional optionality to list out kernel mappings which can be applied to each feature used by the classifier. The following code will tell how to replace LinearClassifier with KernelLinearClassifier.
image_column = tf.contrib.layers.real_valued_column('images', dimension=784)
optimizer = tf.train.FtrlOptimizer(
learning_rate=50.0, l2_regularization_strength=0.001)
kernel_mapper = tf.contrib.kernel_methods.RandomFourierFeatureMapper(
input_dim=784, output_dim=2000, stddev=5.0, name='rffm')
kernel_mappers = {image_column: [kernel_mapper]}
estimator = tf.contrib.kernel_methods.KernelLinearClassifier(
n_classes=10, optimizer=optimizer, kernel_mappers=kernel_mappers)
start = time.time()
estimator.fit(input_fn=train_input_fn, steps=2000)
end = time.time()
print('Elapsed time: {} seconds'.format(end - start))
eval_metrics = estimator.evaluate(input_fn=eval_input_fn, steps=1)
print(eval_metrics)There is one additional parameter to KernelLinearClassifier which is a python dictionary from feature_columns. Using random Fourier features, the code below tells the classifier to the map the initial images to a 2K-D vector:
kernel_mapper = tf.contrib.kernel_methods.RandomFourierFeatureMapper(
input_dim=784, output_dim=2000, stddev=5.0, name='rffm')
kernel_mappers = {image_column: [kernel_mapper]}
estimator = tf.contrib.kernel_methods.KernelLinearClassifier(
n_classes=10, optimizer=optimizer, kernel_mappers=kernel_mappers)Note the stddev parameter. It is the standard deviation of the kernel.
The results of running the above code summarize in the given table below. You can further increase the accuracy by increasing the output dimension of the mapping and by adjusting the standard deviation.

Kernel Classifier in TensorFlow Linear Model
Kernel Standard Deviation (Stddev)
The classification quality in TensorFlow Linear Model is very sensitive to the value of stddev. The below table shows the accuracy of the classifier on the valuation data for different values of stddev. The optimal value is 5.
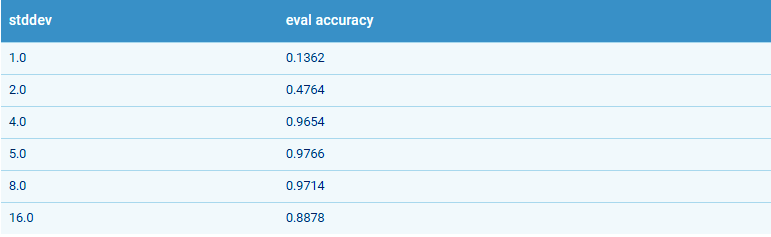
Kernel Standard Deviation
a. Output dimension
The larger the output dimension of the mapping, the closer is the inner product of two mapped vectors giving a newly improved classification accuracy. It can think of as output dimension being equal to the number of weights of the rectilinear model.
The degree of freedom of the model is directly proportional to the dimension. However, after a certain limit, the accuracy starts to saturate as you increase the vector dimension, with the downside of increased time.
This is shown in the below two Figures that depict the accuracy vs output dimension and the training time, respectively.
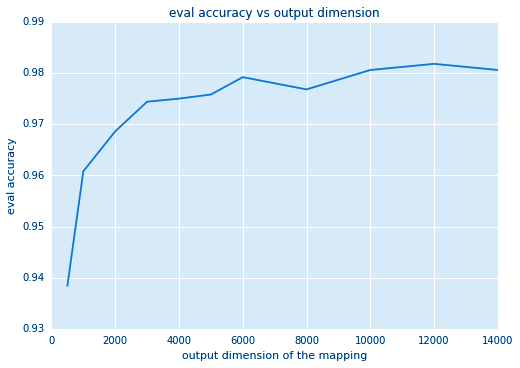
Output Dimension of Kernel Standard Deviation
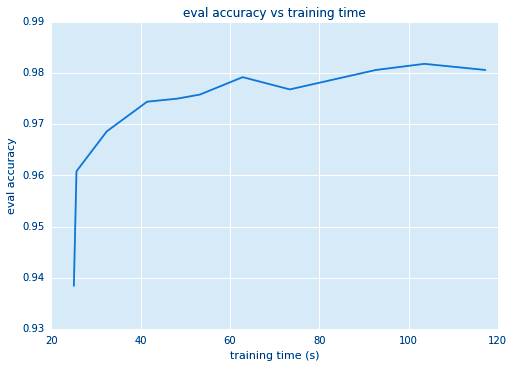
Eval accuracy vs training time in kernel stddev
So, this was all about TensorFlow Linear model with Kernel Methods. Hope you like our explanation,
Conclusion
Hence, in this TensorFlow Linear Model tutorial, we saw the linear model with the kernel method. Moreover, we discussed logistics regressions model, the regression formula.
Also, we discussed preparing the MNIST dataset, Kernel classifier, and Standard Deviation of Kernel. Still, if any doubt regarding TensorFlow Linear Model, ask in the comment tab.
You give me 15 seconds I promise you best tutorials
Please share your happy experience on Google




