Recurrent Neural Network TensorFlow | LSTM Neural Network
Machine Learning courses with 100+ Real-time projects Start Now!!
In our previous TensorFlow tutorial we’ve already seen how to build a convolutional neural network using TensorFlow. Today, we will see TensorFlow Recurrent Neural Network. In this TensorFlow RNN Tutorial, we’ll be learning how to build a TensorFlow Recurrent Neural Network (RNN).
Moreover, we will discuss language modeling and how to prepare data for RNN TensorFlow. Along with Recurrent Neural Network in TensorFlow, we are also going to study TensorFlow LSTM. Also, we will see how to run the code in Recurrent Neural Network in TensorFlow.
So, let’s start the TensorFlow Recurrent Neural Network.
Recurrent Neural Network in TensorFlow
Persistence is a quality that makes humans different from machines. Persistence in the sense that you never start thinking from scratch. You use your previous memory to understand your current learning.
Traditional neural networks do not possess this quality and this shortcoming is overcome using TensorFlow RNN (Recurrent Neural Network).
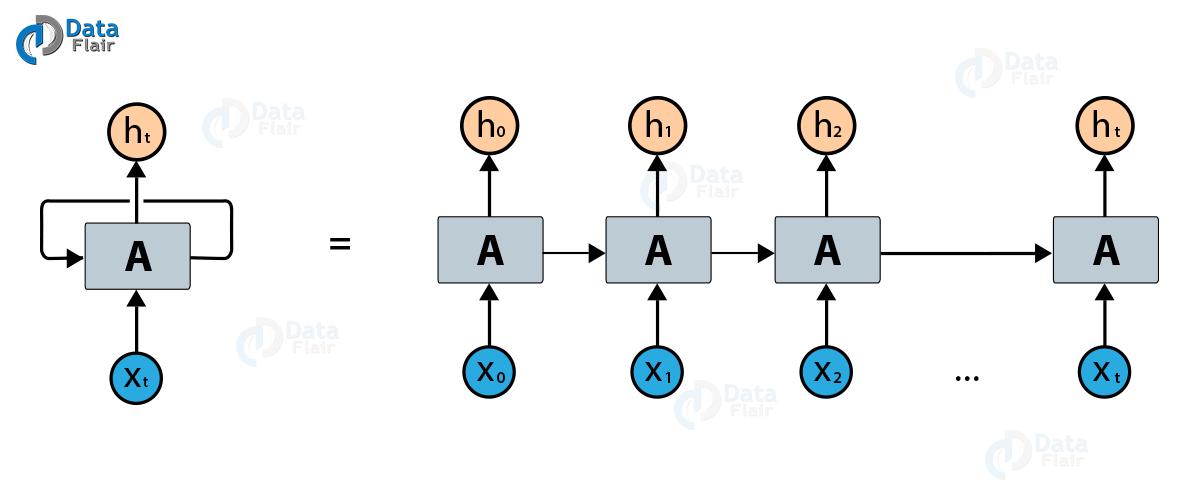
Recurrent Neural Network Tensoflow – What is RNN
RNN Language Modelling
In this TensorFlow Recurrent Neural Network tutorial, you will learn how to train a recurrent neural network on a task of language modeling. The goal of the problem is to fit a model which assigns probabilities to sentences.
It does so, by predicting next words in a text given a history of previous words. For this purpose, we will use the Penn TreeBank (PTB) dataset, which is a popular benchmark and is small and relatively fast to train.
You can solve language modeling problems such as speech recognition, machine translation, or image captioning using TensorFlow Recurrent Neural Network (RNN).
Files Needed for Recurrent Neural Network
From the github repository of TensorFLow, download the files from models/tutorials/rnn/ptb containing ptb_world_lm.py and reader.py.
Preparing the Data
The data required for TensorFlow Recurrent Neural Network (RNN) is in the data/ directory of the PTB dataset from Tomas Mikolov’s webpage.
The dataset is already preprocessed and containing an overall of 10000 different words, including the end-of-sentence marker and a special symbol (\<unk>) for rare words.
In reader.py, you will convert each word to a unique integer identifier, in order to make it easy for the neural network to process the data.
LSTM (Long Short-Term Memory) Network
The core of the RNN model consists of an LSTM cell that processes one word at a time and computes probabilities of the possible values for the next word in the sentence. The memory state of the network is initialized with a vector of zeros and is updated after reading each word.
For computational reasons, you can process data in mini-batches of size batch_size. Every word in a batch should correspond to a time t. The machine learning library will automatically sum the gradients of each batch for you.
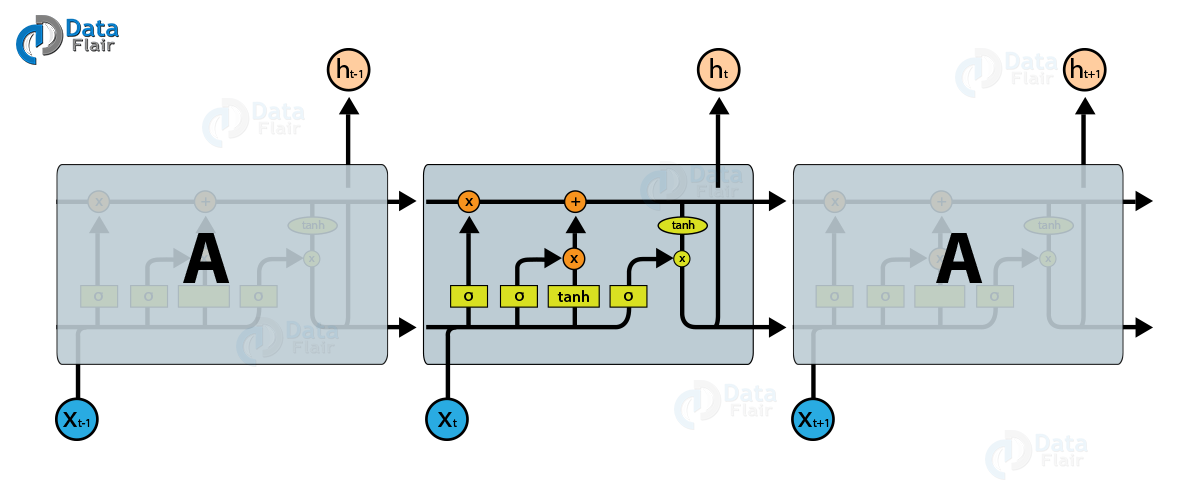
Working of Long Short-Term Neural Network

Long Short-Term Neural Network
t=0 t=1 t=2 t=3 t=4 [The, brown, fox, is, quick] [The, red, fox, jumped, high] words_in_dataset[0] = [The, The] words_in_dataset[1] = [brown, red] words_in_dataset[2] = [fox, fox] words_in_dataset[3] = [is, jumped] words_in_dataset[4] = [quick, high] batch_size = 2, time_steps = 5
The basic pseudocode:
words_in_dataset = tf.placeholder(tf.float32, [time_steps, batch_size, num_features])
lstm = tf.contrib.rnn.BasicLSTMCell(lstm_size)
# Initial state of the LSTM memory.
hidden_state = tf.zeros([batch_size, lstm.state_size])
current_state = tf.zeros([batch_size, lstm.state_size])
state = hidden_state, current_state
probabilities = []
loss = 0.0
for current_batch_of_words in words_in_dataset:
# The value of state is updated after processing each batch of words.
output, state = lstm(current_batch_of_words, state)
# The LSTM output can be used to make next word predictions
logits = tf.matmul(output, softmax_w) + softmax_b
probabilities.append(tf.nn.softmax(logits))
loss += loss_function(probabilities, target_words)
a. Shortened Backpropagation
By design, the output of a recurrent neural network (RNN) depends on arbitrarily distant inputs. Unfortunately, this makes backpropagation computation difficult.
In order to make the learning process tractable, it is common practice to create an “unrolled” version of the network, which contains a fixed number (num_steps) of LSTM inputs and outputs. The model is then trained on this finite approximation of the RNN.
This can be implemented by feeding inputs of length num_steps at a time and be performing a backward pass after each such input block.
The following code creates a graph which performs a shortened backpropagation:
# Placeholder for the inputs in a given iteration.
words = tf.placeholder(tf.int32, [batch_size, num_steps])
lstm = tf.contrib.rnn.BasicLSTMCell(lstm_size)
# Initial state of the LSTM memory.
initial_state = state = tf.zeros([batch_size, lstm.state_size])
for i in range(num_steps):
# The value of state is updated after processing each batch of words.
output, state = lstm(words[:, i], state)
# The rest of the code.
# ...
final_state = statePerforming an iteration over the whole dataset in Recurrent Neural Network TensorFlow:
# A numpy array holding the state of LSTM after each batch of words.
numpy_state = initial_state.eval()
total_loss = 0.0
for current_batch_of_words in words_in_dataset:
numpy_state, current_loss = session.run([final_state, loss],
# Initialize the LSTM state from the previous iteration.
feed_dict={initial_state: numpy_state, words: current_batch_of_words})
total_loss += current_loss
b. Inputs
The word identities will be embedded into a dense representation (Word2Vec) before feeding to the LSTM. This allows the model to efficiently represent the knowledge about particular words and can be written as:
# embedding_matrix is a tensor of shape [vocabulary_size, embedding size] word_embeddings = tf.nn.embedding_lookup(embedding_matrix, word_ids)
The embedding matrix will be initialized randomly and the model will learn to differentiate the meaning of words just by looking at the data.
c. Cost Function
We want to minimize the average negative log probability of the target words:
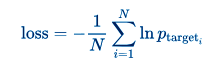
Cost Function
It is easy to implement but the function sequence_loss_by_example is already available, so you can use it.
The average per-word perplexity is equal to
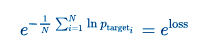
LSTM- Average per-word
You need to monitor this value throughout the training process.
d. Stacking the Memories (LSTMs)
To give the model more expressive power, we can add multiple layers of LSTMs to process the data. The output of the first layer will become the input of the second and so on.
We have a class called MultiRNNCell that makes the implementation smooth:
def lstm_cell():
return tf.contrib.rnn.BasicLSTMCell(lstm_size)
stacked_lstm = tf.contrib.rnn.MultiRNNCell(
[lstm_cell() for _ in range(number_of_layers)])
initial_state = state = stacked_lstm.zero_state(batch_size, tf.float32)
for i in range(num_steps):
# The value of state is updated after processing each batch of words.
output, state = stacked_lstm(words[:, i], state)
# The rest of the code.
# ...
final_state = stateRunning the Code in RNN
Before running the code in Recurrent Neural Network in TensorFlow, make sure to download the PTB dataset, as discussed at the beginning of this tutorial. Then, extract the PTB dataset in your home directory as follows:
tar xvfz simple-examples.tgz -C $HOME
Note: For Windows users, it might be a little different.
Now, clone the repository from github and run the following commands:
cd models/tutorials/rnn/ptb python ptb_word_lm.py --data_path=$HOME/simple-examples/data/ --model=small
There are 3 supported model configurations in the tutorial code: “small”, “medium” and “large”. The difference between them is in the size of the LSTMs and the set of hyperparameters used for training.
The larger the model, the better results it should get.
So, this was all about TensorFlow Recurrent Neural Network. Hope you like our explanation.
Conclusion
Hence, in this Recurrent Neural Network TensorFlow tutorial, we saw that recurrent neural networks are a great way of building models with LSTMs and there are a number of ways through which you can make your model better such as decreasing the learning rate schedule and adding dropouts between LSTM layers.
Moreover, we discussed the process of language modeling and preparation of data for RNN TensorFlow. Along with this, we also saw what is RNN in TensorFlow.
In addition, we discussed how can we run code for RNN TensorFlow. Furthermore, for any query regarding TensorFlow RNN, feel free to ask in the comment section.
You give me 15 seconds I promise you best tutorials
Please share your happy experience on Google




