Distributed TensorFlow | TensorFlow Clustering
Machine Learning courses with 100+ Real-time projects Start Now!!
By now, you’ve seen what TensorFlow is capable of and how to get it up and running in your system. Today, we’ll be looking at how to make a cluster of TensorFlow servers and distributed TensorFlow in our computation (graph) over those clusters.
Moreover, we will see how to define a cluster, assigning model for distributed TensorFlow. Along with this, we will discuss the training methods and training session for distributed TensorFlow.
So, let’s start Distributed TensorFlow and TensorFlow Clustering.
Distributed TensorFlow and TensorFlow Clustering
TensorFlow Clusters are nothing but individual tasks that participate in the complete execution of a graph.
A server contains a master that is used to create sessions and there is a worker that operates on the respective graphs and every task is associated with a server. TensorFlow cluster can also be fragmented into jobs where each job contains more than one task.
Working Model of Distributed TensorFlow
To see a simple example, you can start off by creating a single process cluster as shown below:
# Start a TensorFlow server as a single-process "cluster".
$ python
>>> import tensorflow as tf
>>> c = tf.constant("Hello, distributed TensorFlow!")
>>> server = tf.train.Server.create_local_server()
>>> sess = tf.Session(server.target) # Create a session on the server.
>>> sess.run(c)
'Hello, distributed TensorFlow!'Define TensorFlow Cluster
You start a cluster in tensorFlow, by creating a server per task which runs on each machine but you can run multiple tasks on the same machine.
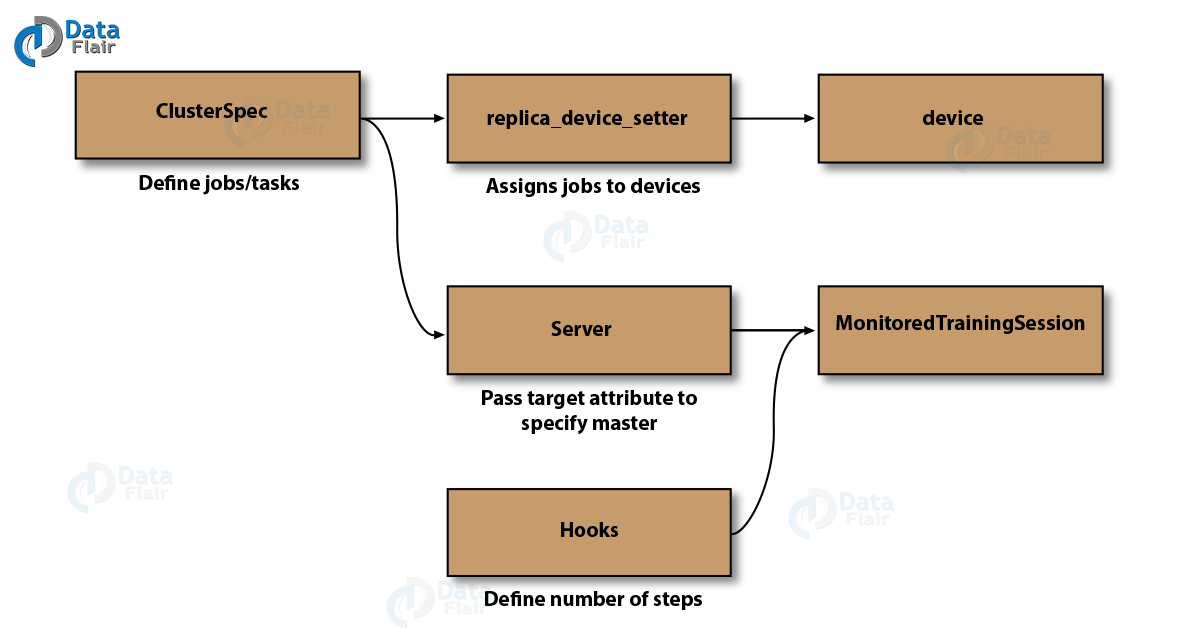
Firstly, you create a TensorFlow cluster specification (master) using tf.train.ClusterSpec. Now, you create a server tf.train.Server, which passes the specification to the constructor, identifying the tasks with a job and an index.
# In task 0:
cluster = tf.train.ClusterSpec({"local": ["localhost:2222", "localhost:2223"]})
server = tf.train.Server(cluster, job_name="local", task_index=0)# In task 1:
cluster = tf.train.ClusterSpec({"local": ["localhost:2222", "localhost:2223"]})
server = tf.train.Server(cluster, job_name="local", task_index=1)Assigning Model Variables and Ops the Worker
We do that using with tf.device that gets assigned to a specific task of a specific job. Nodes left out of this block are automatically assigned to a device by Tensorflow. The device function is also used to distinguish whether the operations run on a CPU or a GPU.
with tf.device("/job:ps/task:0"):
weights_1 = tf.Variable(...)
biases_1 = tf.Variable(...)
with tf.device("/job:ps/task:1"):
weights_2 = tf.Variable(...)
biases_2 = tf.Variable(...)
with tf.device("/job:worker/task:7"):
input, labels = ...
layer_1 = tf.nn.relu(tf.matmul(input, weights_1) + biases_1)
logits = tf.nn.relu(tf.matmul(layer_1, weights_2) + biases_2)
# ...
train_op = ...
with tf.Session("grpc://worker7.example.com:2222") as sess:
for _ in range(10000):
sess.run(train_op)Training
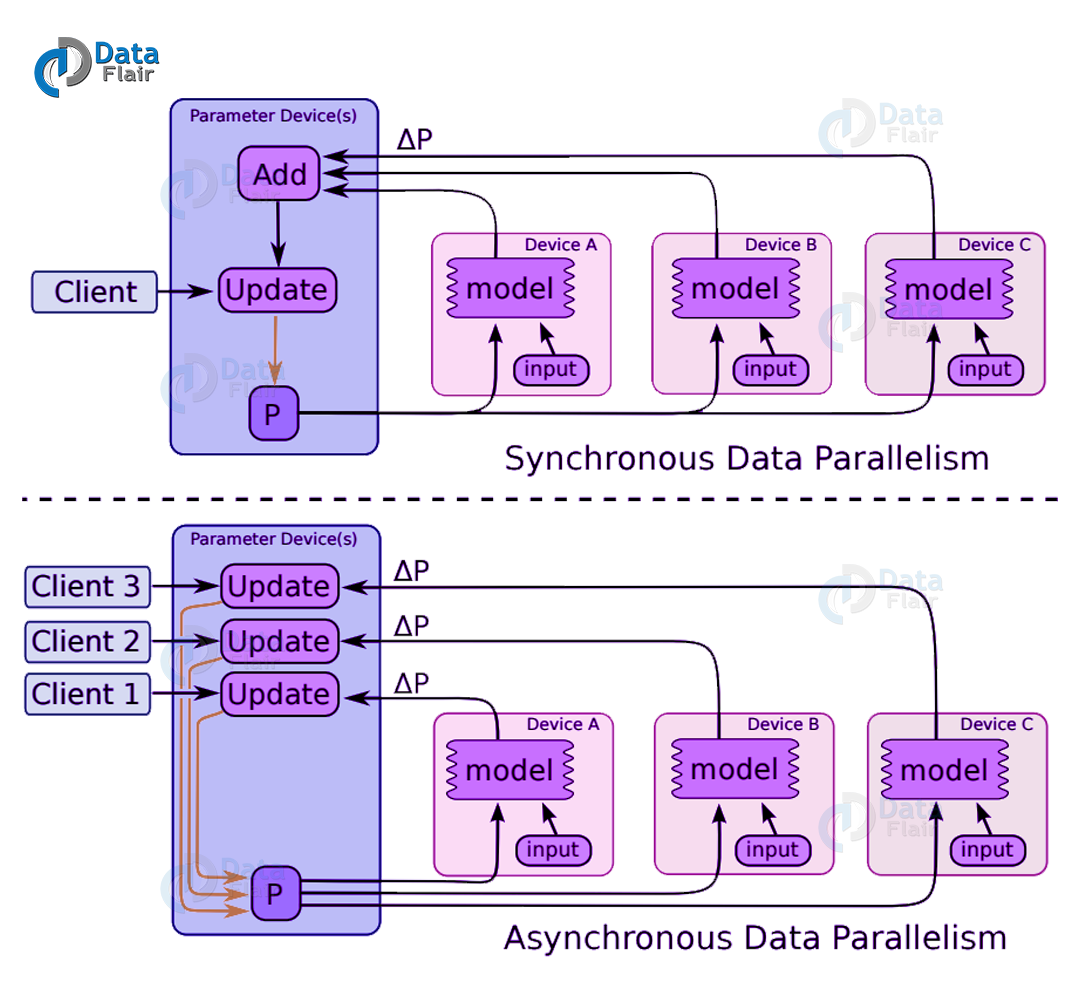
Here, we use the concept of data parallelism wherein the entire graph is settled on a single machine called as the parameter server or ps, while the training operation occurs on multiple machines called as workers. Now, we can specify the structure using one of the following methods:
Distributed TensorFlow- Training
a. In-Graph Replication
Here, the client builds a single tf.Graph , containing one set of parameters (variables attached to /job:ps).
b. Between-Graph Replication
There is a separate client for each /job:worker task, typically in the same process as the worker.
c. Asynchronous Training
Here, each copy of the graph has an exclusive training loop that executes without coordination and is compatible with both forms of replication given above.
d. Synchronous Training
Here, all the copies read the same values for the current parameters, compute gradients in parallel, and then apply them together.
Monitored Training Session
Similar to tf.Session, it handles session initialization and restoring from a checkpoint, saving and closing when completed or when an error occurs. It sets up a master node to initialize the graph, does model checkpointing, exports TensorBoard summaries and starts/stops the sessions. For example
with tf.train.MonitoredTrainingSession(master=server.target,is_chief=(FLAGS.task_index == 0),checkpoint_dir="/tmp/train_logs",hooks=hooks) as mon_sess:
Training Steps For Distributed TensorFlow
Rather than the traditional method of calling a while loop for every with tf.session block, and running the sessions for every iteration, in the monitored training session, you terminate all the instances properly and sync it with saved checkpoints.
Now, you can pass a hook with tf.train.StopAtStepHook to the session object. It defines the last step, after which the ps and workers will shut down. You can try it with
# The StopAtStepHook handles stopping after running given steps.
hooks=[tf.train.StopAtStepHook(last_step=1000000)]
The big picture is similar to what’s been shown below.
Distributed TensorFlow- Training Steps
Joining the Dots
Next, we run a training step asynchronously and see tf.train.SyncReplicasOptimizer for additional details on how to perform the synchronous training. mon_sess.run handles AbortedError in case of preempted ps. We can use the following code:
while not mon_sess.should_stop():
mon_sess.run(train_op)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.register("type", "bool", lambda v: v.lower() == "true")
# Flags for defining the tf.train.ClusterSpec
parser.add_argument(
"--ps_hosts",
type=str,
default="",
help="Comma-separated list of hostname:port pairs"
)
parser.add_argument(
"--worker_hosts",
type=str,
default="",
help="Comma-separated list of hostname:port pairs"
)
parser.add_argument(
"--job_name",
type=str,
default="",
help="One of 'ps', 'worker'"
)
# Flags for defining the tf.train.Server
parser.add_argument(
"--task_index",
type=int,
default=0,
help="Index of task within the job"
)
FLAGS, unparsed = parser.parse_known_args()
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)Thus, you have successfully built a TensorFlow distributed trainer program which implements between-graph replication and asynchronous training.
So, this was all about Distributed TensorFlow. Hope you like our explanation of Cluster in TensorFlow.
Conclusion
Hence, you saw how to run distributed TensorFlow by making clusters and assigning the job to different workers using a master.
It can be very useful while implementing neural networks and other machine learning algorithms where you might encounter a huge number of parameters and there is no other workaround than to distribute the task among different systems and make them work in parallel to save the computational time.
In the next tutorial, we will be learning TensorFlow APIs. Furthermore, if you have any query, feel free to ask through the comment section.
If you are Happy with DataFlair, do not forget to make us happy with your positive feedback on Google




