HDFS Erasure Coding in Big Data Hadoop – An Introduction
Explore what is Erasure Coding in HDFS, and why this feature is introduced in Hadoop 3.0
In this article, we will study HDFS Erasure Coding in detail. The article explains the reason for introducing Erasure Coding, what is HDFS Erasure Coding, algorithms used for Erasure Coding, architecture changes done in Hadoop HDFS for Erasure Coding, and working of Erasure Coding HDFS with an example.
At last, we also see the advantages and limitations of HDFS Erasure Coding.
Let us first see the reason for introducing Erasure Coding.
Problem with Replication Mechanism in HDFS
To provide fault tolerance, HDFS replicates blocks of a file on different DataNodes depending on the replication factor.
So if the default replication factor is 3, then there will be two replicas of the original block.
Each replica uses 100% storage overhead, thus results in 200% storage overhead. These replicas consume other resources as well, like network bandwidth.
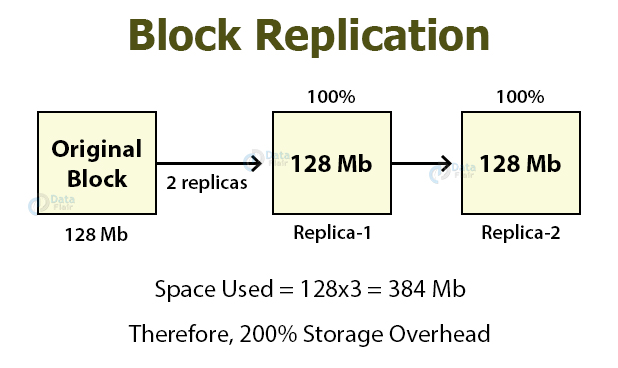
Also, the replicas of cold and warm datasets that have low I/O activities and accessed rarely during normal operations use the same resources as the original dataset.
In N-way replication, there is N-1 fault tolerance with 1/n storage efficiency.
Thus this replication increases the storage overhead and seems to be expensive.
Therefore, HDFS uses Erasure Coding in place of replication to provide the same level of fault tolerance with storage overhead to be not more than 50%.
A replication factor of an Erasure Coded file is always one, and we cannot change it.
What is HDFS Erasure Coding?
Erasure Coding in Hadoop 3 is the solution to the expensive 3x default replication.
In storage systems, the Redundant Array of Inexpensive Disks (RAID) uses Erasure Coding.
RAID implements Erasure Coding by striping, that is, dividing logically sequential data such as file into smaller units (bit, byte, or block) and storing consecutive units on different disks.
For each strip of the original dataset, a certain number of parity cells are calculated based on the Erasure Coding algorithm (discussed later in this article) and stored, the process known as encoding.
The error in any striping cell can be recovered from the calculation based on the remaining data and parity cells; the process known as decoding.
Thus using Erasure Coding in HDFS improves storage efficiency while providing the same level of fault tolerance and data durability as traditional replication-based HDFS deployment.
For example:
A file with six blocks having replication factor 3 will consume a total of 18 blocks of disk space (6*3=18).
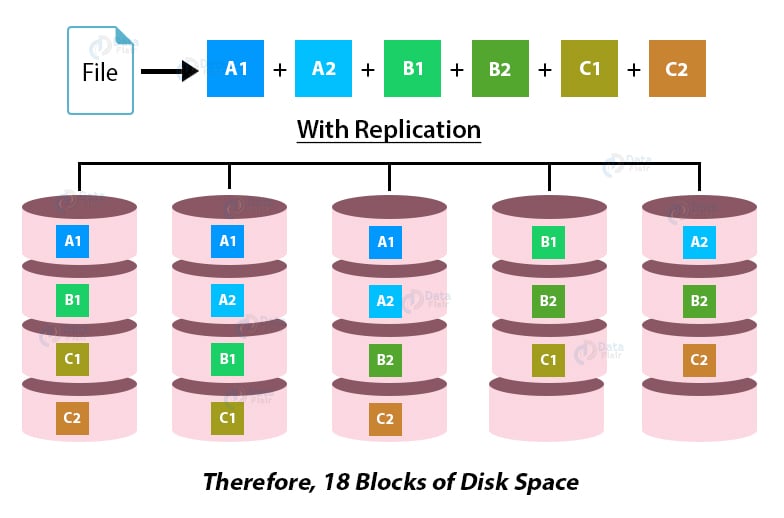
On the other hand, with Erasure Coding, a file with six blocks will consume only nine blocks of disk space (6 data, 3 parity).
Thus requires only 50% storage overhead.
Algorithm for HDFS Erasure Coding
HDFS Erasure Coding uses EC algorithms to calculate the parity for each data block (cell). The different algorithms for Erasure Coding are:
1. XOR Algorithm
Its an algorithm based on XOR operation which provides the simplest form of erasure coding. XOR operation is associative and generates 1 parity bit from an arbitrary number of data bits.
For example, if we have 3 data cells, then using XOR operation, we can calculate the parity bit like 1 ⊕ 0 ⊕ 1 ⊕ 1 = 1.
If any of the data bit gets lost, it gets recovered by XORing the remaining bits and the parity bit.
XOR algorithm generates only 1 parity bit for any number of data cell inputs, so it can tolerate only 1 failure.
Thus it is insufficient for systems like HDFS, which need to handle multiple failures.
The fault tolerance in the XOR algorithm is one, and storage efficiency is 75%.
2. Reed-Solomon Algorithm
Reed-Solomon Algorithm overcomes the limitation of the XOR algorithm.
It uses linear algebra operation to generate multiple parity cells so that it can tolerate multiple failures.
RS algorithm multiplies ‘m’ data cells with a Generator Matrix (GT) to get extended codeword with m data cells and n parity cells.
If the storage fails, then storage can be recovered by multiplying the inverse of the generator matrix with the extended codewords as long as ‘m’ out of ‘m+n’ cells are available.
“The fault tolerance in RS is up to ‘n,’ i.e., the number of parity cells and storage efficiency is m/m+n where m is data cell and n is parity cell.”
Architecture of Hadoop Erasure Coding
In order to support Erasure Coding, HDFS architecture undergoes some changes. The architecture changes are:
1. NameNode Extension
The files in HDFS are stripped into block groups. Each block group contains a certain number of internal blocks. The new protocol named hierarchical block was introduced to reduce NameNode memory consumption from these additional blocks.
The block group ID can be deduced from the ID of any of its internal blocks. This allows for the management at the block group level rather than at the block level.
2. Client Extensions
The main Input/Output logic of the HDFS client implemented in DFSInputStream and DFSOutputStream has extended with data striping and EC support into DFSStripedInputStream and DFSStripedOutputStream.
The basic principle behind the client extensions is to enhance the client’s read and write paths to work on the multiple internal blocks in a block group in parallel.
- The DFSStripedOutputStream on the output/write path manages a set of data streamers, on the output/write path, one for each DataNode storing an internal block in the current block group. The data streamers mostly work asynchronously. The operations on the whole block group, including allocating a new block group, ending the current block group, and so forth, were handled by the coordinator.
- The DFSStripedInputStream on the input/read path translates a requested logical byte range of data as ranges into internal blocks stored on DataNodes. Then it issues read requests in parallel. During failures, it issues additional read requests for decoding.
3. DataNode Extensions
For background recovery of failed erasure-coded blocks, DataNode runs an additional ErasureCodingWorker (ECWorker).
Similar to replication, the NameNode detects the Failed EC blocks and selects a DataNode to perform the recovery task. The recovery work is passed as a heartbeat response to the NameNode.
The ErasureCodingWorker performs the following three tasks to reconstruct the failed EC block.
- Read the data from source nodes using a dedicated thread pool.
- Decode the data and generate output data.
- Transfer the generated data blocks to the target nodes.
4. HDFS Erasure coding policies
File and directories in HDFS cluster can have different erasure coding and replication policies to accommodate heterogeneous workloads.
The HDFS erasure coding policy combines how to encode and decode a file. Each policy is defined using these two pieces of information:
1. The EC schema: EC schema includes:
- the numbers of data blocks and parity blocks in an EC group (e.g., 6+3)
- the codec algorithm (e.g., Reed-Solomon, XOR).
2. The size of a striping cell.
Working of Hadoop Erasure Coding

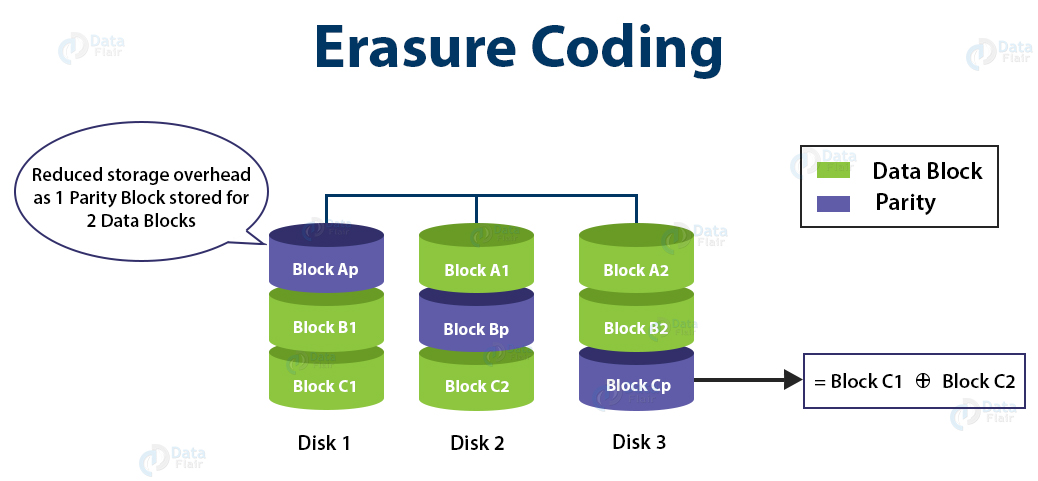
Let us understand the working of Erasure Coding in HDFS with the help of an example.
In the GIF, we can see a file XYZ, divided into 6 blocks (A1, A2, B1, B2, C1, and C2).
Using Erasure Coding Algorithm, the parity block is calculated (Ap for A1 and A2, Bp for B1 and B2, and Cp for C1 and C2 ).
If Block A1 is lost, then by using A2 and the parity block Ap, A1 can be recovered.
If block C1 is lost then by using C2 and the parity block Cp, C1 can be recovered.
Advantages of HDFS Erasure Coding in Hadoop
- Online EC support – Erasure coding provides online EC support, i.e., writing data immediately in EC format, and thus avoiding a conversion phase and saving storage space. Also, this online EC enhances multiple disk spindles in parallel, which is desirable in clusters with high-end networking.
- Simplify file operations between federated namespaces – Erasure Coding naturally distributes a small file to multiple DataNodes. It also eliminates the need to bundle multiple files into a single coding group. This simplifies file operations such as quota reporting, deletion, and migration between federated namespaces.
- Low overhead – The storage overhead in Erasure Coding is only 50%.
- Two-way Recovery – HDFS block errors are discovered and recovered not only while reading the path but also, we can check it actively in the background.
- Compatibility – HDFS users can easily use the advanced and basic features, including snapshot, encryption, appending, caching, and so forth on erasure-coded data.
Limitations of HDFS Erasure Coding
- Due to substantial technical challenges, Erasure Coded files do not support certain HDFS file writes operations like hflush, hsync, and append.
- Erasure coding puts additional demands on the cluster in terms of CPU and network.
- Erasure coding adds additional overhead in the reconstruction of the data due to performing remote reads.
Conclusion
Thus after reading the HDFS Erasure Coding article, we can conclude that the erasure coding reduces the storage overhead and provides the same level of fault tolerance as 3x replication.
Erasure Coding is only one such feature of Hadoop, explore more such HDFS features.
I hope you liked this blog on HDFS Erasure Coding.
If you have any queries, please let us know by leaving a comment.
Keep Learning!!
If you are Happy with DataFlair, do not forget to make us happy with your positive feedback on Google





Great little article. Should Stripping be Striping?