Data Block in HDFS – HDFS Blocks & Data Block Size
Have you ever thought about how the Hadoop Distributed File system stores files of large size?
Hadoop is known for its reliable storage. Hadoop HDFS can store data of any size and format.
HDFS in Hadoop divides the file into small size blocks called data blocks. These data blocks serve many advantages to the Hadoop HDFS. Let us study these data blocks in detail.
In this article, we will study data blocks in Hadoop HDFS. The article discusses:
- What is a HDFS data block and the size of the HDFS data block?
- Blocks created for a file with an example.
- Why are blocks in HDFS huge?
- Advantages of Hadoop Data Blocks
Let us first begin with an introduction to the data block and its default size.
What is a data block in HDFS?
Files in HDFS are broken into block-sized chunks called data blocks. These blocks are stored as independent units.
The size of these HDFS data blocks is 128 MB by default. We can configure the block size as per our requirement by changing the dfs.block.size property in hdfs-site.xml
Hadoop distributes these blocks on different slave machines, and the master machine stores the metadata about blocks location.
All the blocks of a file are of the same size except the last one (if the file size is not a multiple of 128). See the example below to understand this fact.
Example
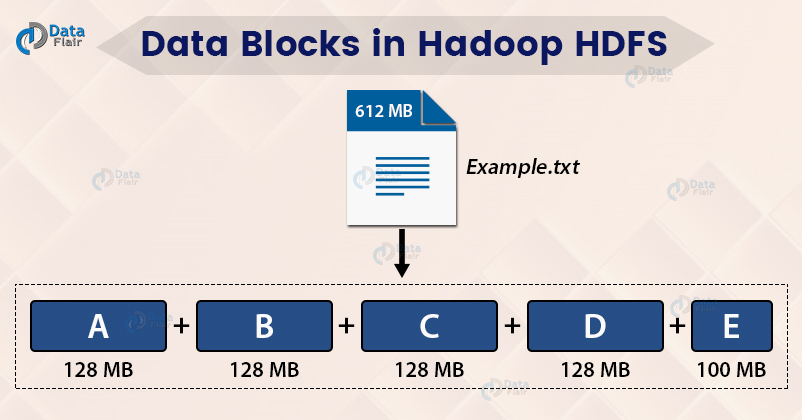
Suppose we have a file of size 612 MB, and we are using the default block configuration (128 MB). Therefore five blocks are created, the first four blocks are 128 MB in size, and the fifth block is 100 MB in size (128*4+100=612).
From the above example, we can conclude that:
- A file in HDFS, smaller than a single block does not occupy a full block size space of the underlying storage.
- Each file stored in HDFS doesn’t need to be an exact multiple of the configured block size.
Now let’s see the reasons behind the large size of the data blocks in HDFS.
Why are blocks in HDFS huge?
The default size of the HDFS data block is 128 MB. The reasons for the large size of blocks are:
- To minimize the cost of seek: For the large size blocks, time taken to transfer the data from disk can be longer as compared to the time taken to start the block. This results in the transfer of multiple blocks at the disk transfer rate.
- If blocks are small, there will be too many blocks in Hadoop HDFS and thus too much metadata to store. Managing such a huge number of blocks and metadata will create overhead and lead to traffic in a network.
Advantages of Hadoop Data Blocks
1. No limitation on the file size
A file can be larger than any single disk in the network.
2. Simplicity of storage subsystem
Since blocks are of fixed size, we can easily calculate the number of blocks that can be stored on a given disk. Thus provide simplicity to the storage subsystem.
3. Fit well with replication for providing Fault Tolerance and High Availability
Blocks are easy to replicate between DataNodes thus, provide fault tolerance and high availability.
4. Eliminating metadata concerns
Since blocks are just chunks of data to be stored, we don’t need to store file metadata (such as permission information) with the blocks, another system can handle metadata separately.
Conclusion
We can conclude that the HDFS data blocks are blocked-sized chunks having size 128 MB by default. We can configure this size as per our requirements. The files smaller than the block size do not occupy the full block size. The size of HDFS data blocks is large in order to reduce the cost of seek and network traffic.
The article also enlisted the advantages of data blocks in HDFS.
You can even check the number of data blocks for a file or blocks location using the fsck Hadoop command.
If you like this article on HDFS blocks or if you have any query regarding this, just drop a comment in the comment section and we will get back to you.
Happy Learning!!
Did you like this article? If Yes, please give DataFlair 5 Stars on Google





Thank You for your post. Nice Tutorial. It is very helpful.
Glad, our tutorial helped you is such a pleasure for us. We are regularly updating our content for more informative articles on HDFS for readers like you. Keep reading our blogs and keep sharing your experience with us.
Very nicely explained HDFS Blocks, but I have one doubt in your example you mentioned a file with 518 MB of size which will create 5 data blocks in HDFS the last one will occupy only 6 MB which will leave 122 MB of free space. Would this space be filled up when we are writing next file of lets say same size 518 MB. Or this space will be wasted.
Space won’t be wasted, Actually, it will create a smaller block.
For Example: if we want to write a file of size 10 MB, then 10 MB sized block will be allocated rather than 128 MB.
As you saying that 10 MB sized block will be allocated rather than 128MB but here we have fixed 128MB block only right. So how it will store 10MB data , will it create new 10MB block for this storage? Can you pls explain little deeper
Lets say block size is 64MB and updated to 128MB, the new data after updation will be storing as per 128MB. What about the old data? Will it be same or we can update that also as per 128MB?
Yes, when you update the block size (from 64 MB to 128 MB) in the configuration file (hdfs-site.xml), newer data will be created with the recent block size ie 128 MB.
Now the old data will remain in 64 MB block size, but yes, we can update it to 128 MB block size, for this you can run copy command (or distcp), make sure to delete older data.
I have a question here, as shown in the above example block size is 128MB, and the last block of a file is 6MB, My question is what will happen with the remaining space in that data block, will that be reused if yes then how it works?
If the data size is less than block size then small sized block will be allocated. like in the given example since the remaining data is merely 6 MB (which is less than the block size) a block of size 6 MB will be allocated.
I have a question, What is Block scanner and how it works??
200MB size data stored in 2 blocks, to move 2 blocks of data into other path or server into single. Can this be done by command without changing default value of hdfs-site.xml ??
Please do reply, thanks.
Hey Mutturaj,
HDFS Framework will automatically create the blocks and copy them in the cluster, we don’t need to run any commands, for details about data write, please refer:
HDFS data read & write operations for complete information.
Hope, you get the answer.
Thank you for saving my grades =) !
We are glad that the readers are liking our content. Keep visiting DataFlair for regular updates on Big Data & Data Science world.
What could be the max size of block, like you said by default it is 128, but what could be the max block size?
How many blocks can be assigned to a single data node?
Great article
Hii dataflair, pls apply a scroll on your sidebar as well .. it is causing a lot of problem, Rest, it has “Quality” content.
Thanks