NameNode High Availability in Hadoop HDFS
1. NameNode High Availability: Objective
In this Blog about Hadoop NameNode High Availability HDFS, you can read all about how hadoop high availability is achieved in Hadoop HDFS? This HDFS tutorial will provide you a complete introduction to HDFS Namenode, Hadoop high availability architecture, HDFS and its implementation. Quorum Journal Nodes and Fencing of NameNode in hadoop is also covered in this blog. if at any point you face a query on HDFS NameNode High Availability, just comment.
NameNode High Availability in Hadoop HDFS
2. Introduction to HDFS NameNode
Hadoop Distributed FileSystem-HDFS is the world’s most reliable storage system. HDFS is a FileSystem of Hadoop designed for storing very large files.
HDFS architecture follows master /slave topology in which master is NameNode and slaves is DataNode. Namenode stores meta-data i.e. number of blocks, their location, replicas and other details. This meta-data is available in memory in the master for faster retrieval of data. NameNode maintains and manages the slave nodes, and assigns tasks to them. It should be deployed on reliable hardware as it is the centerpiece of HDFS.
Before Hadoop 2.0.0, the NameNode was a single point of failure (SPOF) in an HDFS cluster. Each cluster had a single NameNode, and if NameNode fails, the cluster as a whole would be out services. The cluster will be unavailable until the NameNode restarts or brought on a separate machine.
NameNode SPOF problem limit availability in following ways:
- Planned maintenance activities like software or hardware upgrades on the Namenode would result in downtime of the Hadoop cluster.
- If any unplanned event triggers, like machine crash, then cluster would be Unavailable unless an operator restarted the new namenode.
Now let us move ahead with the NameNode high availability feature
Learn: Architecture of HDFS
3. Hadoop NameNode High Availability Architecture
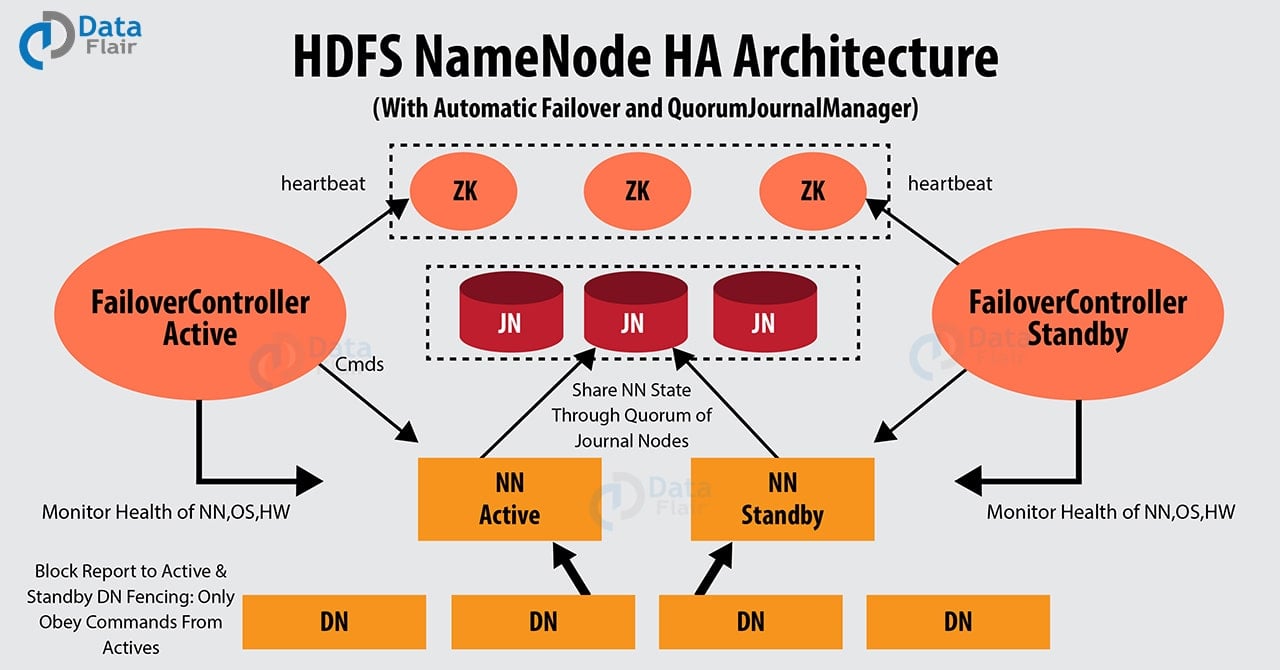
HDFS NameNode High Availability Architecture
Hadoop 2.0 overcomes this SPOF by providing support for many NameNode. HDFS NameNode High Availability architecture provides the option of running two redundant NameNodes in the same cluster in an active/passive configuration with a hot standby.
- Active NameNode – It handles all client operations in the cluster.
- Passive NameNode – It is a standby namenode, which has similar data as active NameNode. It acts as a slave, maintains enough state to provide a fast failover, if necessary.
If Active NameNode fails, then passive NameNode takes all the responsibility of active node and cluster continues to work.
Issues in maintaining consistency in the HDFS High Availability cluster are as follows:
- Active and Standby NameNode should always be in sync with each other, i.e. they should have the same metadata. This permit to reinstate the Hadoop cluster to the same namespace state where it got crashed. And this will provide us to have fast failover.
- There should be only one NameNode active at a time. Otherwise, two NameNode will lead to corruption of the data. We call this scenario as a “Split-Brain Scenario”, where a cluster gets divided into the smaller cluster. Each one believes that it is the only active cluster. “Fencing” avoids such scenarios. Fencing is a process of ensuring that only one NameNode remains active at a particular time.
After Hadoop High availability architecture let us have a look at the implementation of Hadoop NameNode high availability.
Learn: How MapReduce works
4. Implementation of NameNode High Availability Architecture
In HDFS NameNode High Availability Architecture, two NameNodes run at the same time. We can Implement the Active and Standby NameNode configuration in following two ways:
- Using Quorum Journal Nodes
- Using Shared Storage
4.1. Using Quorum Journal Nodes
QJM is an HDFS implementation. It is designed to provide edit logs. It allows sharing these edit logs between the active namenode and standby namenode.
For High Availability, standby namenode communicates and synchronizes with the active namenode. It happens through a group of nodes or daemons called “Journal nodes”. The QJM runs as a group of journal nodes. There should be at least three journal nodes.
For N journal nodes, the system can tolerate at most (N-1)/2 failures and continue to function. So, for three journal nodes, the system can tolerate the failure of one {(3-1)/2} of them.
When an active node performs any modification, it logs modification to all journal nodes.
The standby node reads the edits from the journal nodes and applies to its own namespace in a constant manner. In the case of failover, the standby will ensure that it has read all the edits from the journal nodes before promoting itself to the Active state. This ensures that the namespace state is completely synchronized before a failure occurs.
To provide a fast failover, the standby node must have up-to-date information about the location of data blocks in the cluster. For this to happen, IP address of both the namenode is available to all the datanodes and they send block location information and heartbeats to both NameNode.
Learn: Erasure Coding
Any doubt yet HDFS NameNode High Availability? Please Comment.
4.1.1. Fencing of NameNode
For the correct operation of an HA cluster, only one of the namenodes should active at a time. Otherwise, the namespace state would deviate between the two namenodes. So, fencing is a process to ensure this property in a cluster.
- The journal nodes perform this fencing by allowing only one namenode to be the writer at a time.
- The standby namenode takes the responsibility of writing to the journal nodes and prohibit any other namenode to remain active.
- Finally, the new active namenode can perform its activities.
Learn: What is HDFS Disk Balancer
4.2. Using Shared Storage
Standby and active namenode synchronize with each other by using “shared storage device”. For this implementation, both active namenode and standby namenode must have access to the particular directory on the shared storage device (.i.e. Network file system).
When active namenode perform any namespace modification, it logs a record of the modification to an edit log file stored in the shared directory. The standby namenode watches this directory for edits, and when edits occur, the standby namenode applies them to its own namespace. In the case of failure, the standby namenode will ensure that it has read all the edits from the shared storage before promoting itself to the Active state. This ensures that the namespace state is completely synchronized before failover occurs.
To prevent the “split-brain scenario” in which the namespace state deviates between the two namenode, an administrator must configure at least one fencing method for the shared storage.
Learn: HDFS Federation
This was all on HDFS Namenode High Availability Tutorial.
5. NameNode High Availability – Conclusion
Concluding this article on NameNode High availability, I would say that Hadoop 2.0 HDFS HA provide for single active namenode and single standby namenode. But some deployments need a high degree of fault-tolerance. Hadoop new version 3.0, allows the user to run many standby namenodes. For example, configuring five journalnodes and three namenode. As a result hadoop cluster is able to tolerate the failure of two nodes rather than one.
See Also-
If you have any query about HDFS namenode high availability, so, please leave a comment.
Your 15 seconds will encourage us to work even harder
Please share your happy experience on Google


what is the difference in HA with NFS and QJM , which one is more preferable?
In QJM only active namenode writes to the journal nodes and not stanby.
I’m trying to execute this command through ansible playbook: “hadoop-daemon.sh start journalnode”
The playbook execution result shows that the command is run successfully, as below:
TASK [Start nodes] ******************************************************************************************************
changed: [192.168.100.191]
changed: [192.168.100.193]
changed: [192.168.100.192]
However, when I check back, it is not done.
This command is working perfectly when I am executing it manually.
When I did some research, it appears that it may be because ansible commands run under different user than when you run it manually.
Any idea how to resolve this? I have not created any user. Is there any default user? All environment variables are set. How to create a user ID for journal nodes?
QJM is default implemenation of hdfs?
qjm is default implementation?
Please explain that how the election done for Active NameNode