HBase MapReduce Integration | MapReduce Over HBase
HBase integration with Hadoop’s MapReduce framework is one of the great features of HBase. So, to learn about it completely, here we are discussing HBase MapReduce Integration in detail.
Moreover, we will see classes, input format, mapper, reducer. Also, we will learn MapReduce over HBase in detail, to understand HBase MapReduce well.
So, let’s start HBase MapReduce Integration.
What is MapReduce?
In order to solve the problem of processing in excess of terabytes of data in a scalable way, MapReduce process was designed.
However, to build such a system that increases in performance linearly with the number of physical machines added, there should be a proper way. Basically, this is what the main purpose of MapReduce.
Moreover, by splitting the data located on a distributed file system, it follows a divide-and-conquer approach. Hence, the servers which are available can access these chunks of data and also can process them as fast as they can.
However, we will have to consolidate the data at the end with this approach. So, MapReduce has this built right into it, again.
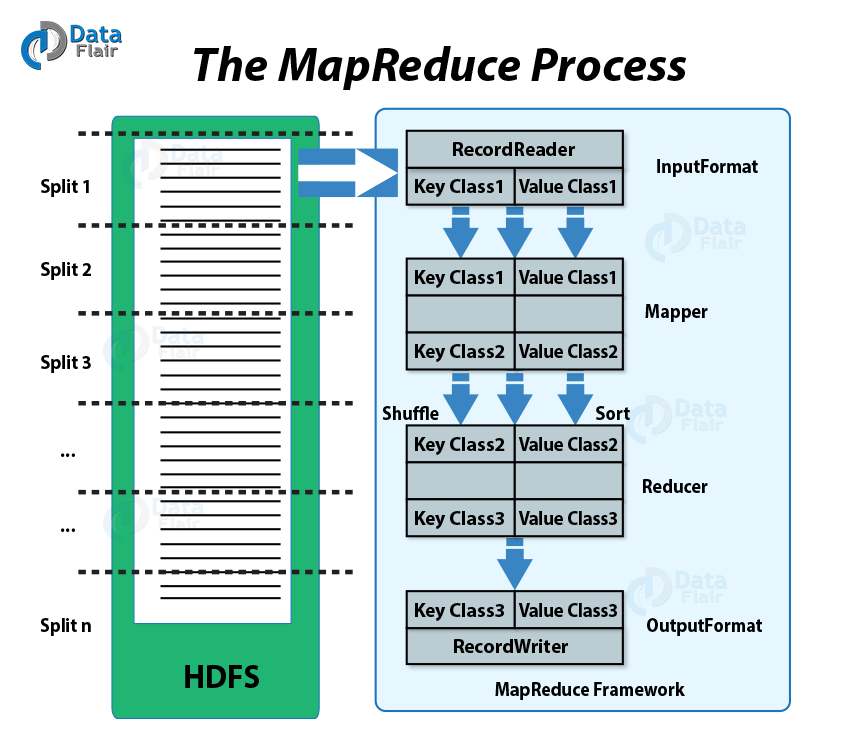
MapReduce Integration
4 Classes in MapReduce
Classes in MapReduce Integration
Here in the above MapReduce process figure, all the classes which are involved in the Hadoop implementation of MapReduce, is shown, let’s learn them in detail:
i. InputFormat
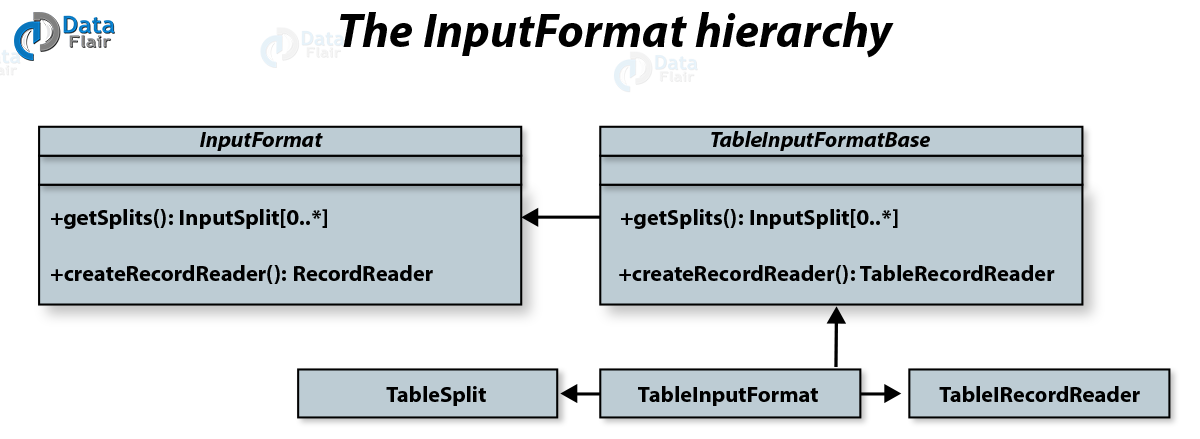
InputFormat in HBase MapReduce Integration
At very first, InputFormat splits the input data and further returns a RecordReader instance which defines the classes of the key and value objects. Also, it helps to iterate over each input record, with the help of next() method.
ii. Mapper
Now, by using the map() method, each record read using the RecordReader is processed, in this step.
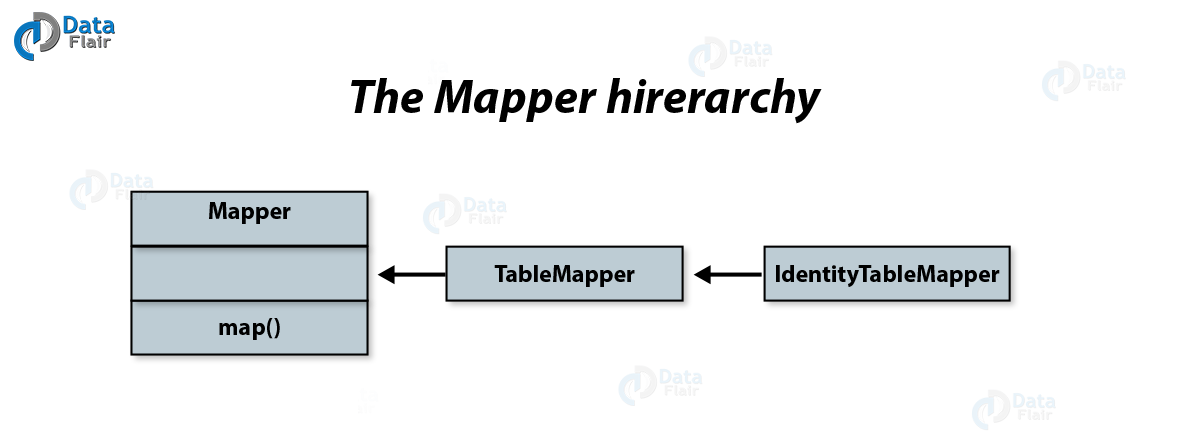
HBase MapReduce Integration Mapper
iii. Reducer
This stage is as same as Mapper stage. Here we use to process the output of a Mapper class after shuffling and sorting of data.
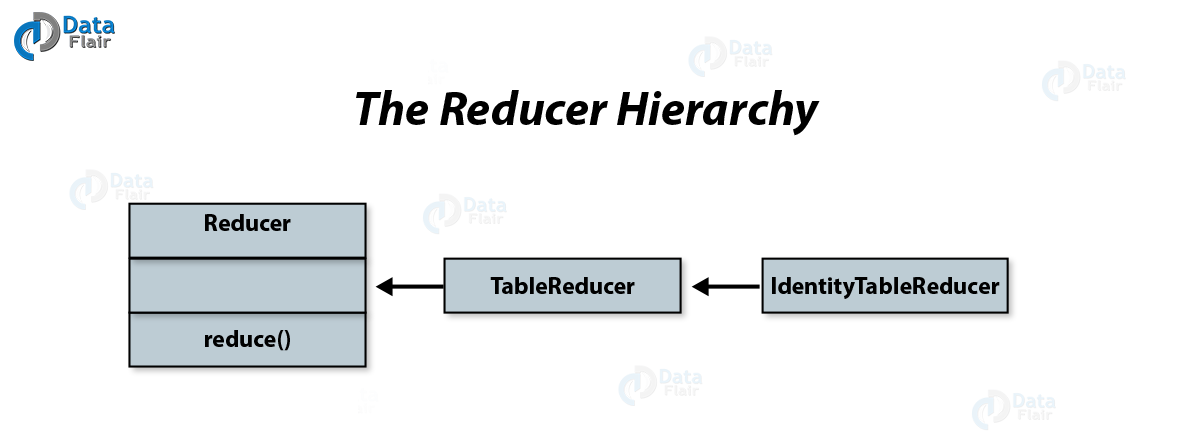
Reducer in HBase MapReduce Integration
iv. OutputFormat
Finally, OutputFormat class hold the data in various locations. Here are some specific implementations which allow output to files, or in the case of the TableOutputFormat class to HBase tables. Moreover, to write the data into the specific HBase output table, it uses a TableRecord Writer.
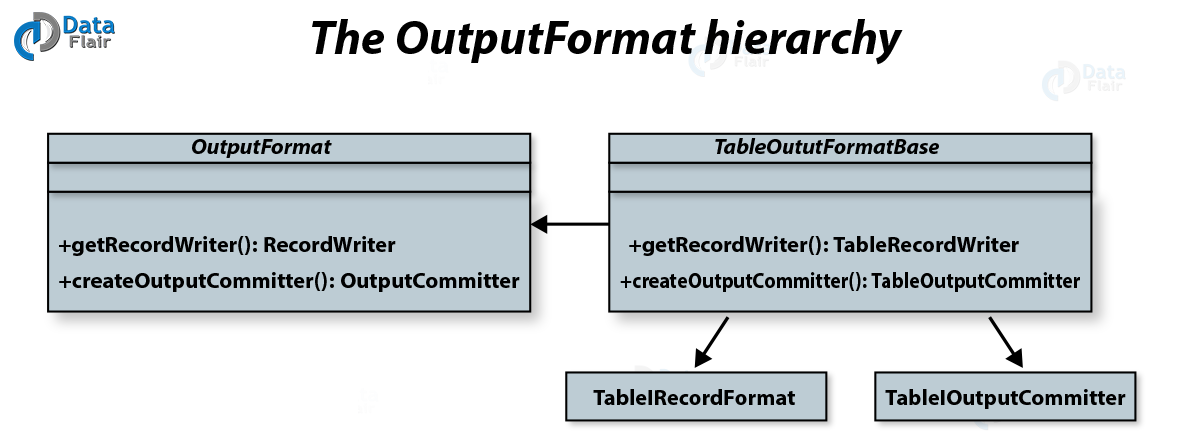
HBase MapReduce OutputFormat Hierarchy
Supporting Classes in MapReduce Integration
Now, in setting up MapReduce jobs over HBase, the MapReduce support comes with the TableMapReduceUtil class. There are some static methods which help to configure a job, hence we can run it with HBase as the source and/or the target.
MapReduce Over HBase
a. Preparation
In order to run a MapReduce job which needs classes from libraries, we’ll need to make such libraries available before the execution of job only. Although, we have two choices, such as:
- Static preparation of all task nodes.
- Supplying everything needed for the job.
i. Static Provisioning
Here, it is very useful to install the JAR file(s) of that library (which is used often) locally on the task tracker machines. Tracked machines are those machines which run the MapReduce tasks. It is possible by following steps:
- At very first, make the copy of the JAR files into a common location on all nodes.
- Further, with full location into the hadoop-env.sh configuration file, into the HADOOP_CLASSPATH variable, add the JAR files:
# Extra Java CLASSPATH elements. Optional. # export HADOOP_CLASSPATH="<extra_entries>:$HADOOP_CLASSPATH"
- Afterward, to make the changes effective, restart all task trackers.
As its name, we can say this technique is quite static, although make sure every update here needs a restart of the task tracker daemons.
ii. Dynamic Provisioning
Basically, we use dynamic provisioning approach, while we need to provide different libraries to each job we want to run, or also if we want to update the library versions along with your job classes.
b. Data Source and Sink
An HBase table can be the source or target of a MapReduce job, or also we can use it as both input and output or we can say, for the input and output types, the third kind of MapReduce template uses a table.
In addition, it also includes setting the TableInputFormat and TableOutputFormat classes into the respective fields of the job configuration.
So, this was all about HBase MapReduce Integration. Hope you like our explanation.
Conclusion: HBase MapReduce Integration
Hence, we have learned all about, HBase MapReduce Integration. We saw the meaning of MapReduce, its classes. Moreover, we saw supporting classes in HBase MapReduce Integration. However, if any doubt occurs regarding integration in HBase MapReduce, feel free to ask in the comment section.
Your opinion matters
Please write your valuable feedback about DataFlair on Google





Does HBase internally use MapReduce?