HBase Architecture – Regions, Hmaster, Zookeeper
In this HBase tutorial, we will learn the concept of HBase Architecture. Moreover, we will see the 3 major components of HBase, such as HMaster, Region Server, and ZooKeeper.
Along with this, we will see the working of HBase Components, HBase Memstore, HBase Compaction in Architecture of HBase. This HBase Technology tutorial also includes the advantages and limitations of HBase Architecture to understand it well.
So, let’s start HBase Architecture.
What is HBase Architecture?
Basically, there are 3 types of servers in a master-slave type of HBase Architecture. They are HBase HMaster, Region Server, and ZooKeeper. Let’s start with Region servers, these servers serve data for reads and write purposes.
That means clients can directly communicate with HBase Region Servers while accessing data. Further, the HBase Master process handles the region assignment as well as DDL (create, delete tables) operations. And finally, a part of HDFS, Zookeeper, maintains a live cluster state.
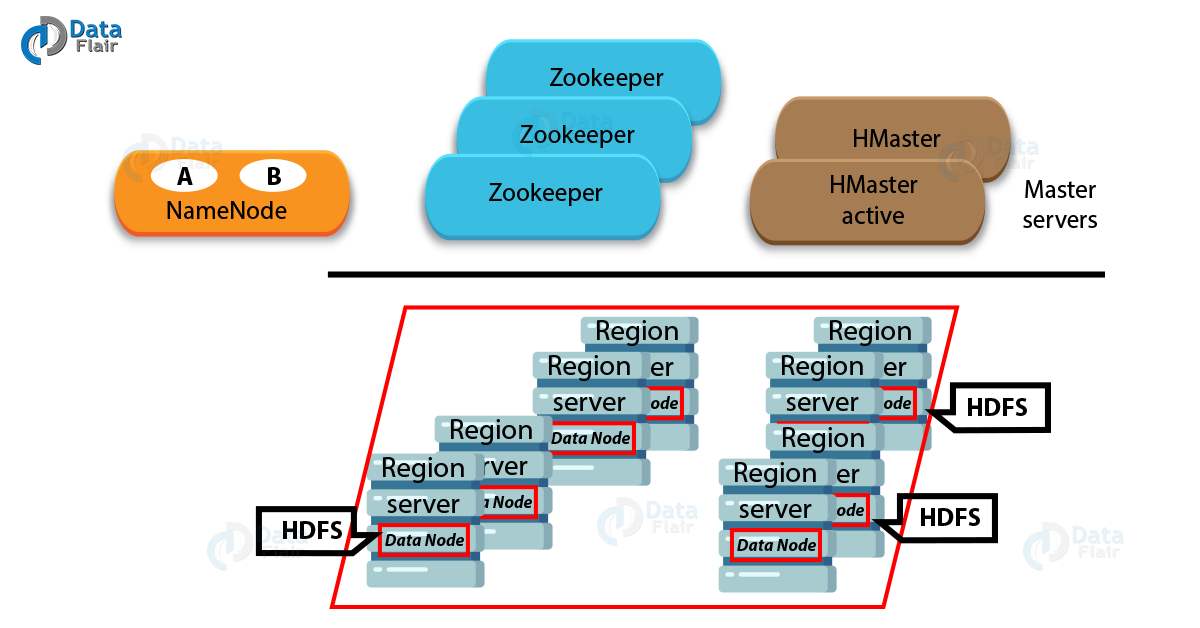
What is HBase Architecture
In addition, the data which we manage by Region Server further stores in the Hadoop DataNode. And, all HBase data is stored in HDFS files. Then for the data served by the RegionServers, Region Servers are collocated with the HDFS DataNodes, which also enable data locality.
Here, data locality refers to putting the data close to where we need. Make sure, when we write HBase data it is local, but while we move a region, it is not local until compaction.
Moreover, for all the physical data blocks the NameNode maintains Metadata information that comprise the files.
HBase Architecture – Regions
In HBase Architecture, a region consists of all the rows between the start key and the end key which are assigned to that Region. And, those Regions which we assign to the nodes in the HBase Cluster, is what we call “Region Servers”.
Basically, for the purpose of reads and writes these servers serves the data. While talking about numbers, it can serve approximately 1,000 regions. However, we manages rows in each region in HBase in a sorted order.
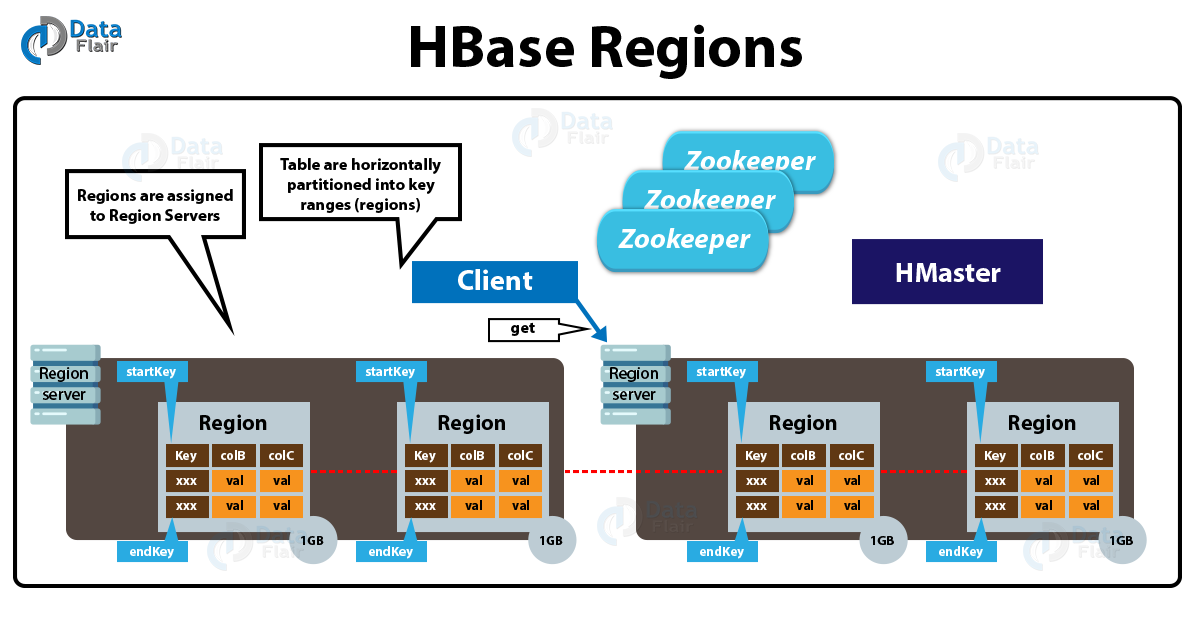
HBase Architecture – Regions
These Regions of a Region Server are responsible for several things, like handling, managing, executing as well as reads and writes HBase operations on that set of regions. The default size of a region is 256MB, which we can configure as per requirement.
HBase Architecture – HMaster
HBase master in the architecture of HBase is responsible for region assignment as well as DDL (create, delete tables) operations.
There are two main responsibilities of a master in HBase architecture:
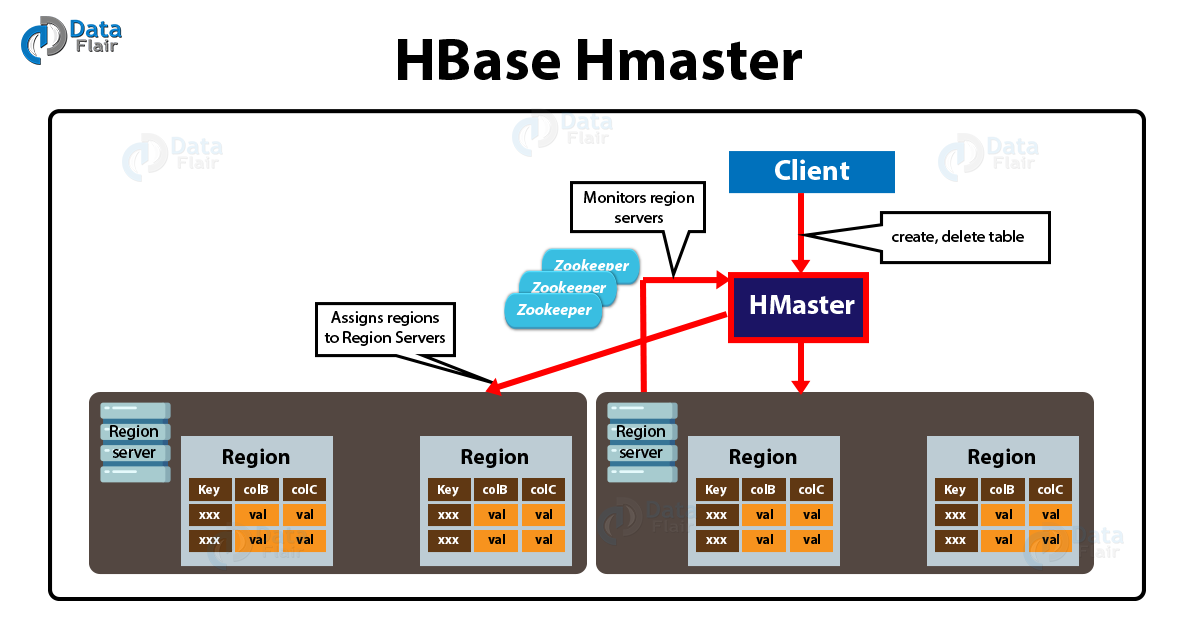
The Architecture of HBase – HMaster
a. Coordinating the region servers
Basically, a master assigns Regions on startup. Also for the purpose of recovery or load balancing, it re-assigns regions.
Also, a master monitors all RegionServer instances in the HBase Cluster.
b. Admin functions
Moreover, it acts as an interface for creating, deleting and updating tables in HBase.
ZooKeeper in HBase Architecture
However, to maintain server state in the HBase Cluster, HBase uses ZooKeeper as a distributed coordination service.
Basically, which servers are alive and available is maintained by Zookeeper, and also it provides server failure notification. Moreover, in order to guarantee common shared state, Zookeeper uses consensus.
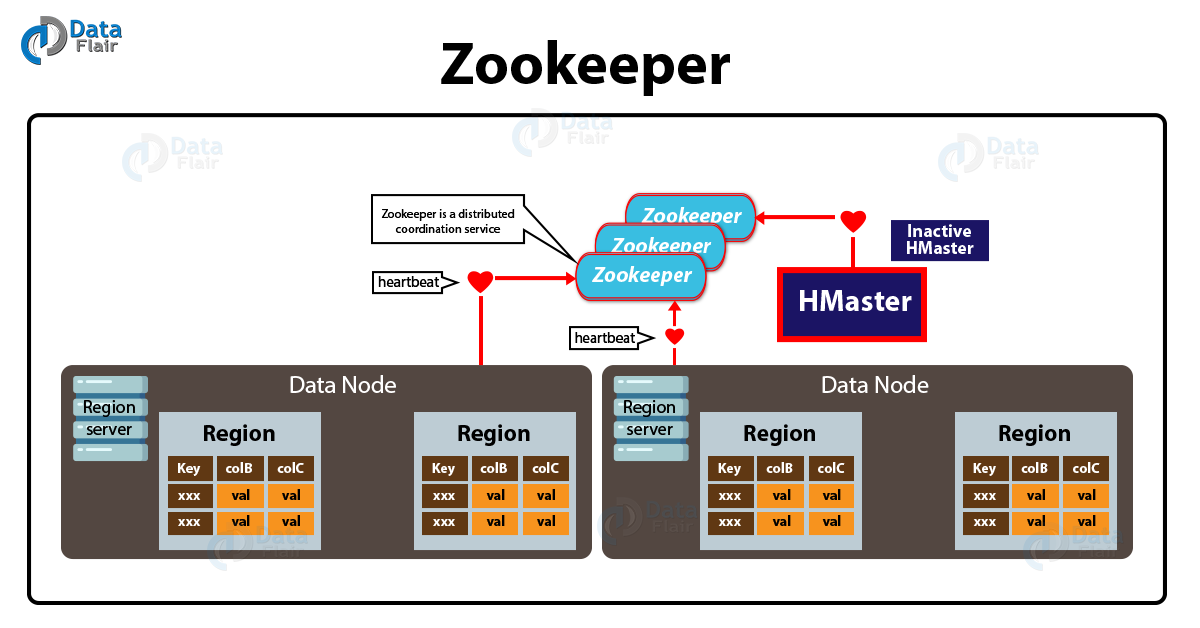
HBase Architecture – Zookeeper
How HBase Components Works?
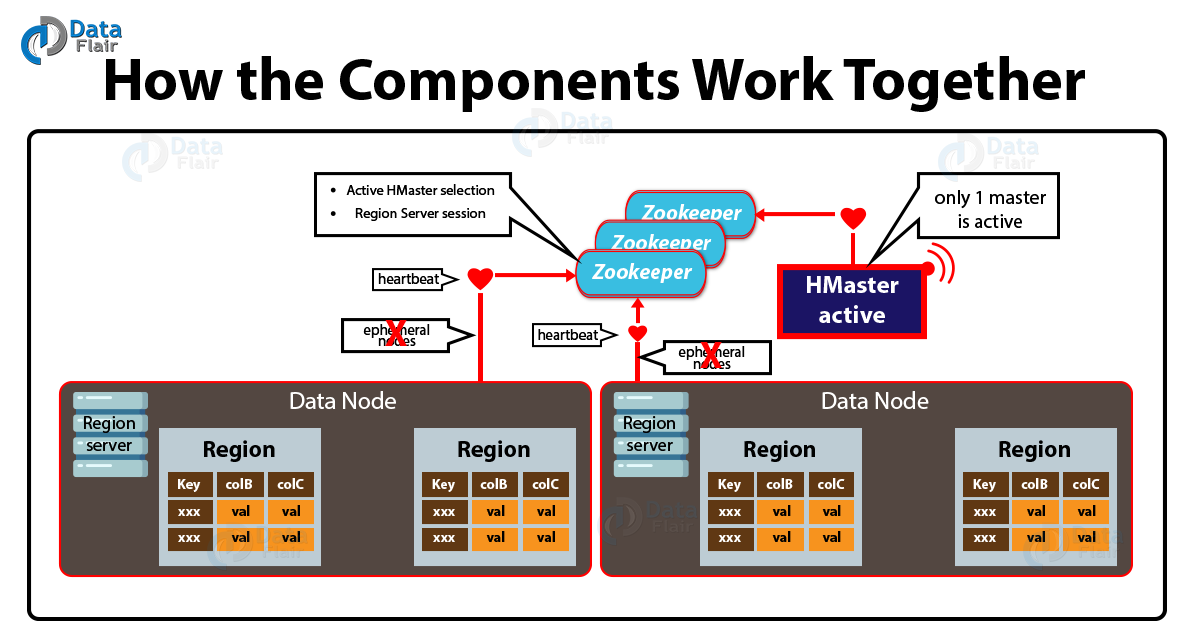
As we know, to coordinate shared state information for members of distributed systems, HBase uses Zookeeper. Further, active HMaster, as well as Region servers, connect with a session to ZooKeeper. Then for active sessions, ZooKeeper maintains ephemeral nodes by using heartbeats.
Ephemeral nodes mean znodes which exist as long as the session which created the znode is active and then znode is deleted when the session ends.
HBase Architecture – working of Components
In addition, each Region Server in HBase Architecture produces an ephemeral node. Further, to discover available region servers, the HMaster monitors these nodes.
Also for server failures, it monitors these nodes. Moreover, to make sure that only one master is active, Zookeeper determines the first one and uses it.
As a process, the active HMaster sends heartbeats to Zookeeper, however, the one which is not active listens for notifications of the active HMaster failure.
Although, the session gets expired and the corresponding ephemeral node is also deleted if somehow a region server or the active HMaster fails to send a heartbeat. Then for updates, listeners will be notified of the deleted nodes.
Further, the active HMaster will recover region servers, as soon as it listens for region servers on failure. Also, when inactive one listens for the failure of active HMaster, the inactive HMaster becomes active, if an active HMaster fails.
HBase Architecture – Read or Write
When the first time a client reads or writes to HBase:
- Basically, the client gets the Region server which helps to hosts the META Table from ZooKeeper.
- Moreover, in order to get the region server corresponding to the row key, the client will query the.META. server, it wants to access. However, along with the META Table location, the client caches this information.
- Also, from the corresponding Region Server, it will get the Row.
HBase META Table
META Table is a special HBase Catalog Table. Basically, it holds the location of the regions in the HBase Cluster.
- It keeps a list of all Regions in the system.
- Structure of the .META. table is as follows:
- Key: region start key, region id
- Values: RegionServer
- It is like a binary tree.
Region Server Components in HBase Architecture
There are following components of a Region Server, which runs on an HDFS data node:
- WAL
It is a file on the distributed file system. Basically, to store new data that hasn’t yet been persisted to permanent storage, we use the WAL. Moreover, we also use it for recovery in the case of failure.
- BlockCache
It is the read cache. The main role of BlockCache is to store the frequently read data in memory. And also, the data which is least recently used data gets evicted when full.
- MemStore
It is the write cache. The main role of MemStore is to store new data which has not yet been written to disk. Also, before writing to disk, it gets sorted.
- Hfiles
These files store the rows as sorted KeyValues on disk.
HBase Write Steps (1)
The first step is to write the data to the write-ahead log, while the client issues a put request:
– To the end of the WAL file, all the edits are appended which is stored on disk.
– In case a server crashes, the WAL is used, to recover not-yet-persisted data.
HBase Write Steps (2)
As soon as the data is written to the WAL, it is placed in the MemStore. After that acknowledgment of the put, the request returns to the client.
HBase MemStore
It updates in memory as sorted KeyValues, the same as it would be stored in an HFile. There is one MemStore per column family. The updates are sorted per column family.
Compaction in HBase Architecture
Compaction in HBase Architecture
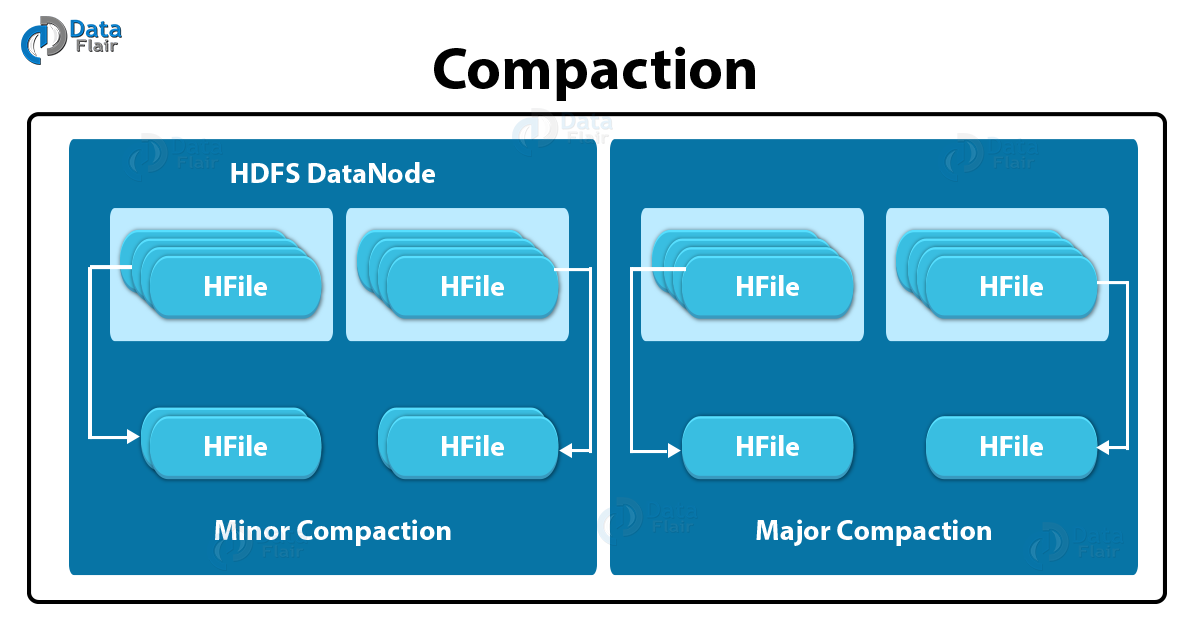
In order to reduce the storage and reduce the number of disks seeks needed for a read, HBase combines HFiles. This entire process is what we call compaction. It selects few HFiles from a region and combines them. Compaction is of two types, such as:
- Minor Compaction
As you can see in the image, HBase picks smaller HFiles automatically and then recommits them to bigger HFiles. This process is what we call Minor Compaction. For committing smaller HFiles to bigger HFiles, it performs merge sort.
- Major Compaction
HBase merges and recommits the smaller HFiles of a region to a new HFile, in Major compaction, as you can see in the image. Here, in the new HFile, the same column families are placed together. In this process, it drops deleted as well as expired cell.
However, it is a possibility that input-output disks and network traffic might get congested during this process. Hence, generally during low peak load timings, it is scheduled.
Region Split in HBase
Region Split in HBase
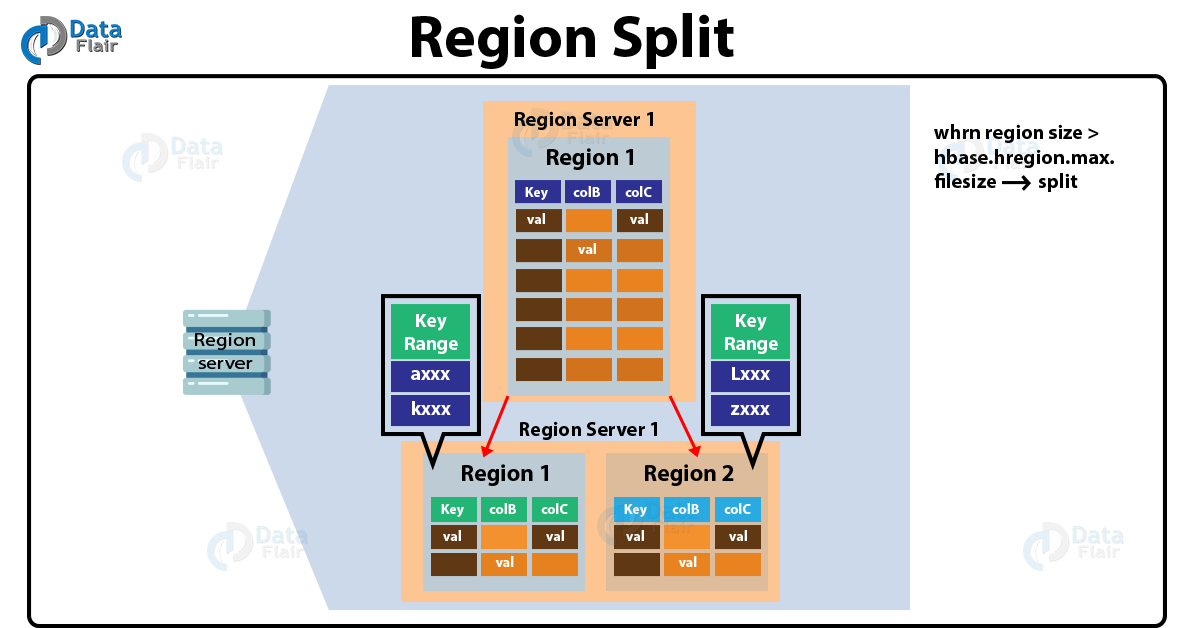
The region has two child regions in HBase Architecture, whenever a region becomes large. Here each region represents exactly a half of the parent region. Afterward, we report this split to the HMaster.
However, until the HMaster allocates them to a new Region Server for load balancing, we handle this by the same Region Server.
HDFS Data Replication
Basically, primary node handles all Writes and Reads. And, HDFS replicates the write-ahead logs as well as HFile blocks. However, these replication process of HFile block happens automatically.
Moreover, to provide the data safety, HBase relies on HDFS because it stores its files.
The process is, one copy is written locally, while data is written in HDFS. Then we replicate it to a secondary node, and after that third copy is written to a tertiary node.
HBase Crash Recovery
- ZooKeeper notifies to the HMaster about the failure, whenever a Region Server fails.
- Afterward, too many active Region Servers, HMaster distributes and allocates the regions of crashed Region Server. Also, the HMaster distributes the WAL to all the Region Servers, in order to recover the data of the MemStore of the failed Region Server.
- Furthermore, to build the MemStore for that failed region’s column family, each Region Server re-executes the WAL.
- However, Re-executing that WAL means updating all the change that was made and stored in the MemStore file because, in WAL, the data is written in timely order.
- Therefore, we recover the MemStore data for all column family just after all the Region Servers executes the WAL.
Advantages of HBase Architecture
There are some benefits which HBase Architecture offers:
a. Strong consistency model
– All readers will see same value, while a write returns.
b. Scales automatically
– While data grows too large, Regions splits automatically.
– To spread and replicate data, it uses HDFS.
c. Built-in recovery
– It uses Write Ahead Log for recovery.
d. Integrated with Hadoop
– On HBase MapReduce is straightforward.
Limitations With Apache HBase
a. Business continuity reliability
– Write Ahead Log replay very slow.
– Also, a slow complex crash recovery.
– Major Compaction I/O storms.
So, this was all about HBase Architecture. Hope you like our explanation.
Conclusion – HBase Architecture
Hence, in this HBase architecture tutorial, we saw the whole concept of HBase Architecture. Moreover, we saw 3 HBase components that are region, Hmaster, Zookeeper.
Also, we discussed, advantages & limitations of HBase Architecture. So, if any doubt occurs regarding HBase Architecture, feel free to ask through the comment tab.
If you are Happy with DataFlair, do not forget to make us happy with your positive feedback on Google





Great tutorial! Thanks for sharing!
Q. Region Split in HBase.
ANS: Below are the sequence of operations:
i. A region is decided to be split when store file size goes above hbase.hregion.max.filesize or according to defined region split policy.
ii. At this point this region is divided into two by region server.
iii. Region server creates two reference files for these two child regions.
iv. These reference files are stored in a new directory called splits under parent directory.
v. Exactly at this point, parent region is marked as closed or offline so no client tries to read or write to it.
vi. Now region server creates two new directories in splits directory for these two child regions.
vii. If steps till 6 are completed successfully, Region server moves both child regions directories under table directory.
viii. The META table is now informed of the creation of two new regions, along with an update in the entry of parent region that it has now been split and is offline. (OFFLINE=true , SPLIT=true)
ix. The reference files are very small files containing only the key at which the split happened and also whether it represents top half or bottom half of the parent region.
x. There is a class called “HalfHFileReader” which then utilizes these two reference files to read the original data file of parent region and also to decide as which half of the file has to be read.
xi. Both regions are now brought online by region server and start serving requests to clients.
xii. As soon as the child regions come online, a compaction is scheduled which rewrites the HFile of parent region into two HFiles independent for both child regions.
xiii. As this process in step 12 completes, both the HFiles cleanly replace their respective reference files. The compaction activity happens under .tmp directory of child regions.
xiv. With the successful completion till step 13, the parent region is now removed from META and all its files and directories marked for deletion.
Finally Master server is informed by this Region server about two new regions getting born. Master now decides the fate of the two regions as to let them run on same region server or to move it to another region server.