Apache Sqoop Architecture – How Sqoop works Internally
As we discussed the complete introduction to Sqoop in our previous article “Apache Sqoop – Hadoop Ecosystem Component”. In this article “Sqoop Architecture and Working”, we will learn about Sqoop Architecture. Also, we will learn to work with Sqoop to understand well. But before Sqoop architecture let’s have a look at Sqoop introduction to brush up your Knowledge.
What is Sqoop?
Basically, using RDBMS applications generally interacts with the relational database. Therefore it makes relational databases one of the most important sources that generate Big Data. However, in the relational structures, such data is stored in RDB Servers. Although, by offering feasible interaction between the relational database server and HDFS, Sqoop plays the vital role in Hadoop ecosystem.
To be more specific, it is a tool that aims to transfer data between HDFS (Hadoop storage) and relational database servers. Such as MySQL, Oracle RDB, SQLite, Teradata, Netezza, Postgres and many more. In addition, imports data from relational databases to HDFS. Also, exports data from HDFS to relational databases.
Moreover, Sqoop can transfer bulk data efficiently between Hadoop and external data stores. Like as enterprise data warehouses, relational databases, etc.
However, it is very interesting to know that this is how Sqoop got its name.
“SQL to Hadoop & Hadoop to SQL”.
Moreover, to import data from external datastores into Hadoop ecosystem tools we use Sqoop. Such as Hive & HBase.
Since we know what is Apache Sqoop now. Thus, let’s understand Sqoop Architecture and Working now.
Sqoop Architecture and Working
By using the below diagram, Let’s understand Apache Sqoop 2 Architecture and how Sqoop works internally:
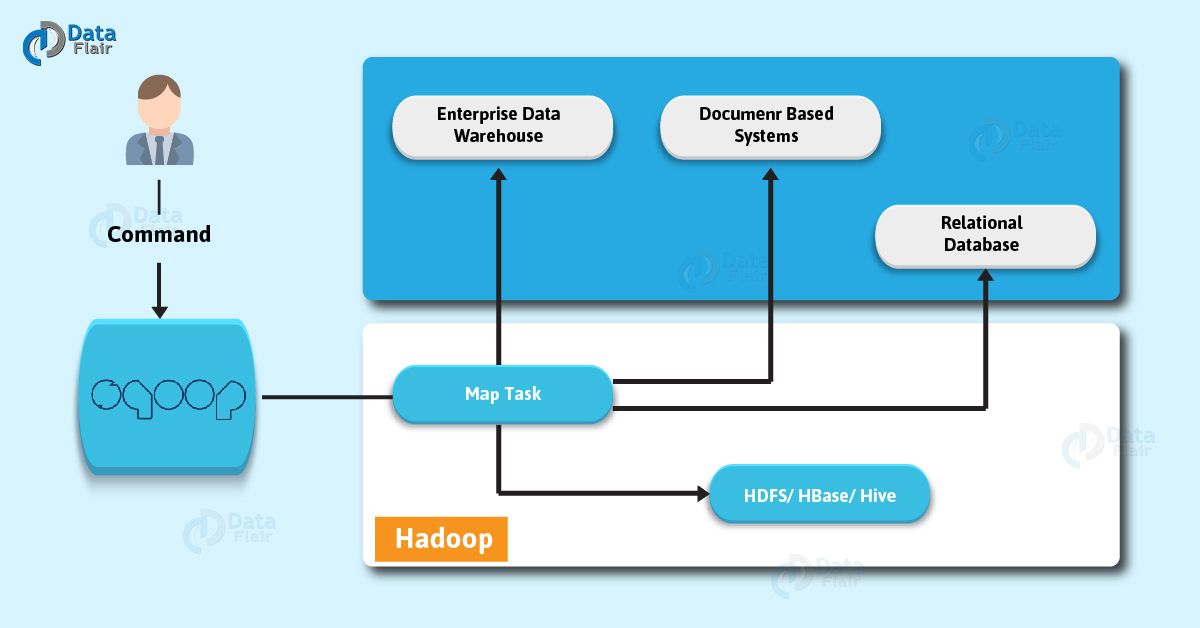
Sqoop Architecture
Basically, a tool which imports individual tables from RDBMS to HDFS is what we call Sqoop import tool. However, in HDFS we treat each row in a table as a record.
Moreover, our main task gets divided into subtasks, while we submit Sqoop command. However, map task individually handles it internally. On defining map task, it is the subtask that imports part of data to the Hadoop Ecosystem. Likewise, we can say all map tasks import the whole data collectively.
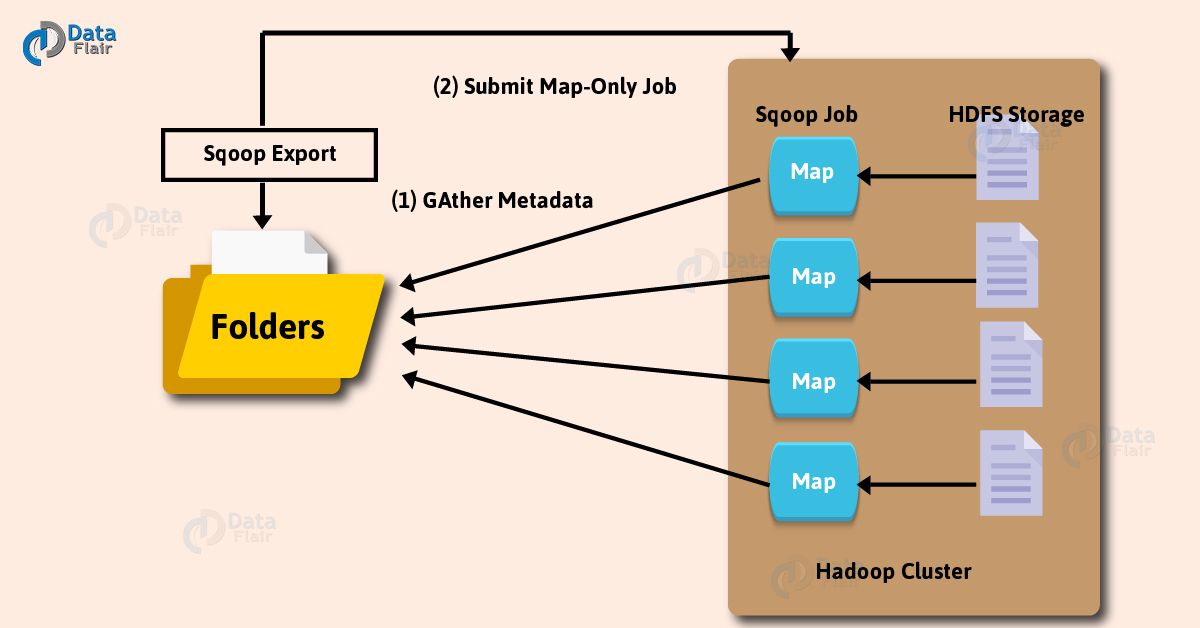
How sqoop Work internally
However, Export also works in the same way.
A tool which exports a set of files from HDFS back to an RDBMS is a Sqoop Export tool. Moreover, there are files which behave as input to Sqoop which also contain records. Those files what we call as rows in the table.
Moreover, the job is mapped into map tasks, while we submit our job, that brings the chunk of data from HDFS. Then we export these chunks to a structured data destination.
Likewise, we receive the whole data at the destination by combining all these exported chunks of data. However, in most of the cases, it is an RDBMS (MYSQL/Oracle/SQL Server).
In addition, in case of aggregations, we require reducing phase. However, Sqoop does not perform any aggregations it just imports and exports the data. Also, on the basis of the number defined by the user, map job launch multiple mappers.
In addition, each mapper task will be assigned with a part of data to be imported for Sqoop import. Also, to get high-performance Sqoop distributes the input data among the mappers equally. Afterwards, by using JDBC each mapper creates the connection with the database. Also fetches the part of data assigned by Sqoop. Moreover, it writes it into HDFS or Hive or HBase on the basis of arguments provided in the CLI.
Conclusion
As a result, we have seen the complete Sqoop Architecture and its working. Still, if you feel to ask any query, feel free to ask in the comment section.
See also-
Sqoop List Databases & Sqoop List Tables
For reference
We work very hard to provide you quality material
Could you take 15 seconds and share your happy experience on Google





These tutorials are good but it repeats the same statement more times. Lot of repetitive information which does not look good. And the construction of the sentences also not good. These makes the reader quit.