Sqoop Connectors and Drivers (JDBC Driver) – Latest Guide
While it comes to the Hadoop ecosystem, the use of words “connector” and “driver” interchangeably, mean completely different things in the context of Sqoop. For every Sqoop invocation, we need both Sqoop Connectors and driver. However, there is a lot of confusion about the use and understanding of these Sqoop concepts.
In this article, we will learn the whole concept of Sqoop Connectors and Drivers in Sqoop. Also, we will see an example of Sqoop connector and Sqoop driver to understand both. Moreover, we will see how Sqoop connectors partition, Sqoop connectors format Sqoop connectors extractor and Sqoop connectors loader.
Let’s start discussing how we use these concepts in Sqoop to transfer data between Hadoop and other systems.

Sqoop Connectors | Sqoop Drivers
What is Sqoop Driver?
Basically, in Sqoop “driver” simply refers to a JDBC Driver. Moreover, JDBC is nothing but a standard Java API for accessing relational databases and some data warehouses. Likewise, the JDK does not have any default implementation also, the Java language prescribes what classes and methods this interface contains.
In addition, for writing their own implementation each database vendor is responsible. However, that will communicate with the corresponding database with its native protocol.
Let’s revise Sqoop Validation–Interfaces & Limitations of Sqoop Validate
To be more specific each database vendor creates drivers. Usually, they are offered with restrictive licenses which prohibits them to be shipped with the Sqoop distribution. Hence we need to download the drivers separately also install them into Sqoop prior to its use.
3. What are the Sqoop Connectors?
Basically, for communication with relational database systems, Structured Query Language (SQL) programing language is designed. Almost every database has its own dialect of SQL, there is a standard prescribing how the language should look like. Usually, the basics are working the same across all databases, although, some edge conditions might be implemented differently.
However, SQL is a very general query processing language. So, we can say for importing data or exporting data out of the database server, it is not always the optimal way.
In addition, by using Sqoop Connectors, Sqoop can overcome the differences in SQL dialects supported by various databases along with providing optimized data transfer. To be more specific connector is a pluggable piece. That we use to fetch metadata about transferred data (columns, associated data types, …). Also to drive the data transfer itself in the most efficient manner.
Moreover, there is a basic connector that is shipped with Sqoop. That is what we call Generic JDBC Connector in Sqoop. However, by name, it’s using only the JDBC interface for accessing metadata and transferring data. So we can say this many not the most optimal for your use case still this connector will work on most of the databases out of the box. Also, Sqoop ships with specialized connectors.
Like for MySQL, PostgreSQL, Oracle, Microsoft SQL Server, DB2, and Netezza. Hence, we don’t need to download extra connectors to start transferring data. Although, we have special connectors available on the internet which can add support for additional database systems or improve the performance of the built-in connectors.
Read about Sqoop HCatalog Integration in detail
Now, let’s see how Sqoop connectors partition, format their output, extract data and load data:
a. Sqoop Connectors – Partitioner
Basically, it generates conditions to be used by the extractor. Also, it varies in how it partitions data transfer based on the partition column data type. Although, each strategy roughly takes on the following form:
(upper boundary – lower boundary) / (max partitions)
However, to partition the data the primary key will be used unless otherwise specified.
There are various data types are currently supported. Such as:
- TINYINT
- SMALLINT
- INTEGER
- BIGINT
- REAL
- FLOAT
- DOUBLE
- NUMERIC
- DECIMAL
- BIT
- BOOLEAN
- DATE
- TIME
- TIMESTAMP
- CHAR
- VARCHAR
- LONGVARCHAR
Let’s know about Sqoop Eval-Commands and Query Evaluation in Sqoop
b. Sqoop Connectors – Extractor
The JDBC data source is queried using SQL during the extraction phase. Basically, on the basis of our configuration, this SQL will vary.
- The SQL statement generated will take on the form SELECT * FROM <table name> if Table name is provided.
- The SQL statement generated will take on the form SELECT <columns> FROM <table name> if Table name and Columns are provided, then.
- Moreover, the provided SQL statement will be used if Table SQL statement is provided.
However, the conditions generated by the partitioner are appended to the end of the SQL query to query a section of data.
Also, the Generic JDBC connector in sqoop extracts CSV data usable by the CSV Intermediate Data Format.
c. Sqoop Connectors – Loader
Basically, the JDBC data source is queried using SQL, during the loading phase. Also, on the basis of our configuration, this SQL will vary.
- The SQL statement generated will take on the form INSERT INTO <table name> (col1, col2, …) VALUES (?,?,..), if Table name is provided.
- The SQL statement generated will take on the form INSERT INTO <table name> (<columns>) VALUES (?,?,..) if Table name and Columns are provided.
- The provided SQL statement will be used if Table SQL statement is provided.
By the CSV Intermediate Data Format, this connector expects to receive CSV data consumable.
Read about the Important difference between Apache Sqoop vs Flume
d. Sqoop Connectors – Destroyer
Also, this connector performs two operations in the destroyer in the TO direction:
- Also, copy the contents of the staging table to the desired table.
- Moreover, Clear the staging table.
- Likewise, in the FROM direction, no operations can perform.
How to use Sqoop Drivers and Connectors?
Let’s see how Sqoop connects to the database to demonstrate how we use drivers and connectors.
How to use Sqoop Connectors
Sqoop will try to load the best performance depends on specified command-line arguments and all available connectors. Basically, with Sqoop scanning this process begins all extra manually downloaded connectors to confirm if we can use one.
Read about Sqoop List Tables – Arguments and Examples
Also, note that since there are no manually installed connectors present also no installed connectors identify themselves as candidates, hence Sqoop will check the JDBC URL. Also, it will help to see if you are connecting to a database for which a built-in special connector is available.
(For example, for the jdbc:mysql:// URL that is used for MySQL, Sqoop will pick up the MySQL Connector, which is optimized for MySQL.) Ultimately, Sqoop will default to the Generic JDBC Connector if we can not use any connector.
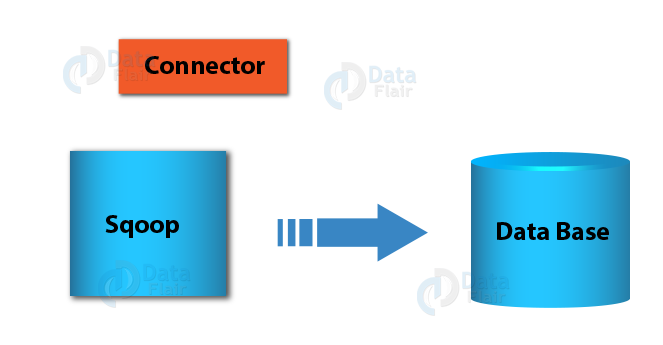
How to use Connectors in Sqoop
The next step after selecting the connector is to choose the JDBC driver in Sqoop. As most connectors are specialized for a given database and most databases have only one JDBC driver available, the connector itself determines which driver should be used. (For example, the MySQL connector will always use the MySQL JDBC Driver called Connector/J.)
The only exception is the Generic JDBC Connector in Sqoop, which isn’t tied to any database and thus can’t determine what JDBC Driver should be used. In that case, you have to supply the driver name in the –driver parameter on the command line. But be careful: Using the –driver parameter will always force Sqoop to use the Generic JDBC Connector regardless of if a more specialized connector is available.
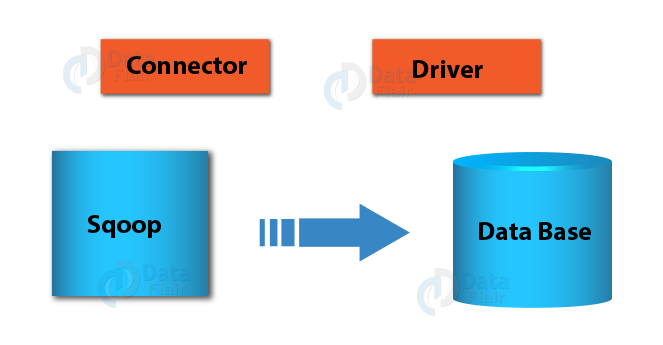
How to use Sqoop Drivers
Ultimately, we have determined both Sqoop connector and driver. After that, we can establish the connection between the Sqoop client and the target database. Let’s see it diagram below.
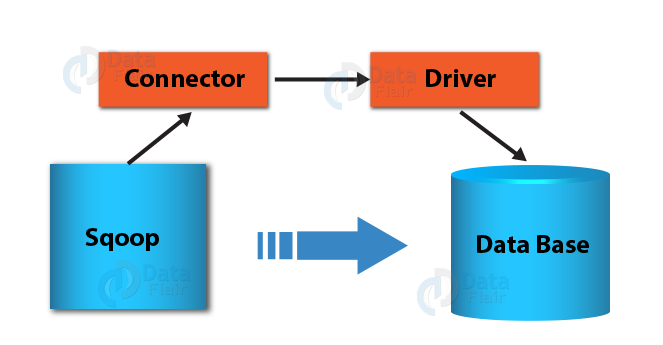
How to use Drivers in Sqoop
Conclusion – Sqoop Connectors
Hence, in this Sqoop tutorial, we study what is Sqoop Connectors and what is Sqoop Driver. Also, we discuss Sqoop connectors partitions, Extract, loader and destroyers. In conclusion, we hope that this article has clarified the differences between Sqoop Connectors and drivers.
Furthermore, we have seen why we need both to transfer data between relational databases and Hadoop ecosystem. Still, if any doubt occurs regarding Sqoop Connectors and Driver, feel free to contact us through the comment section.
Refer Sqoop Books for more learning.
For reference
Did you like this article? If Yes, please give DataFlair 5 Stars on Google





Very informative article However unnecessary use of “moreover”, “however”, “In addition to” , “basically” ,”Usually”, “Although”. I find every another statement having these words. It made my reading tough. Hope you will take it positively.