Lambda Architecture – The New Big Data Architecture
In this blog, we will discuss Lambda Architecture big data. Also, Lambda Architecture applications, advantages as well as disadvantages of Lambda Architecture in Big Data. Moreover, we will discuss Lambda Architecture in detail, how it works.
What is Lambda Architecture
This is the new big data architecture. Also, this was designed to ingest and process. Also, to query both fresh and historical (batch) data in a single data architecture.
We use this architecture is to solve the problem of computing arbitrary functions. Also, the problems contain three layers:
- Batch layer,
- Serving layer, and
- Speed layer
Basically, we used to call the batch layer a “data lake” system like Hadoop. Also, use this historical archive to hold all of the data ever collected. Moreover, this layer helps into supports batch query. Also, we use batch processing to generate analytics or ad hoc.
Secondly, we used to call the speed layer a combination of queuing, streaming.
Also, the speed layer is like the batch layer in that it computes similar analytics.It except that it computes that analytics in real-time on only the most recent data. The analytics the batch layer calculates.
For example
it may be based on data one hour old. It is the speed layer’s responsibility to calculate real-time analytics. That is based on fast-moving data that is zero to one hour old.
The third layer – we used to call the serving layer handles serving up results. Also, combined with both the speed and batch layer.
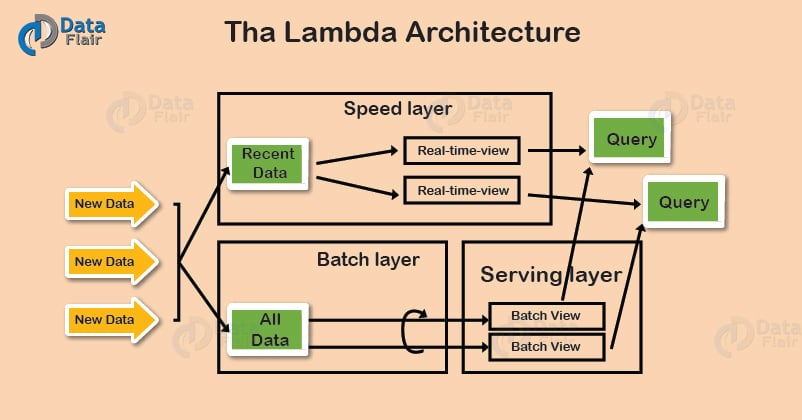
Lambda Architecture – Working
a. As all data enters in the system it will be dispatched to both the batch layer and the speed layer for processing.
b. The batch layer has the two most important functions:
- managing the master dataset
- to pre-compute the batch views.
c. Also, we use serving layer to indexes the batch views. Thus, they can be queried in low-latency, ad-hoc way.
d. The speed layer compensates for the high latency of updates to the serving layer. Also deals with recent data only.
e. We can answer any incoming query by merging results from batch views and real-time views.
Typical Lambda Applications
As we know it is an emerging paradigm in Big Data computing. However, log ingestion and accompanying analytics are use cases of Lambda-based applications.
Moreover, log messages often are created at a high velocity. Also, they are immutable. Also, we can call it as the “fast data”. The ingestion of each log message does not require a response to the entity that delivered the data. It is a one-way data pipeline.
For example
We can say that the analytics for website click logs could be counting page hits and page popularity.
Advantages of Lambda Architectures
As a result, emphasizes retaining the input data unchanged. Also, the discipline of modeling data transformation.
Moreover, this is one of the things that makes large MapReduce workflows tractable. As it enables you to debug each stage independently.
This highlights the problem of reprocessing data. As the reprocessing process is one of the key challenges of stream processing. Also, by this process, input data over again to re-derive output. This is a completely obvious but often ignored requirement. Also, a code will always change.
Disadvantages of Lambda Architectures
There is a problem with Lambda Architecture. That is to maintain the code. Also, that needs to produce the same result in two complex distributed systems. That is exactly as painful as it seems like it would be.
To do programming in frameworks like Storm and Hadoop is complex. Also, the code ends up being towards the framework it runs on.
Why can’t the stream processing system be improved to handle the full problem set in its target domain?
To fix this we have only one approach that is we need to have a language or either framework. Moreover, that abstracts over both the real-time and batch framework.
You can easily write your code using this higher-level framework. Then it “compiles down” to stream processing or MapReduce under the covers. “Summingbird” is the only framework that can easily do this. Furthermore, this will definitely make things a little better, but I don’t think it solves the problem.
Conclusion
As a result, we have studied What is Lambda Architecture. Also, Lambda Architecture working and applications, Lambda Architectures limitations, and benefits of Lambda Architectures.
I hope this New Big Architecture will clear your concept about its working too. Furthermore, if you have any query, feel free to ask in the comment section.
Did we exceed your expectations?
If Yes, share your valuable feedback on Google




