Machine Learning courses with 100+ Real-time projects Start Now!!
1. Text Mining – Objective
Through this Text Mining Tutorial, we will learn what is Text Mining, a process of Text Mining, Text Mining Applications, approaches, issues, areas, and Advantages and Disadvantages of Text Mining.

Text Mining in Data Mining – Concepts, Process & Applications
2. What is Text Mining?
Text Mining is also known as Text Data Mining. The purpose is too unstructured information, extract meaningful numeric indices from the text. Thus, make the information contained in the text accessible to the various algorithms. Information can extracte to derive summaries contained in the documents. Hence, you can analyze words, clusters of words used in documents. In the most general terms, text mining will “turn text into numbers”. Such as predictive data mining projects, the application of unsupervised learning methods.
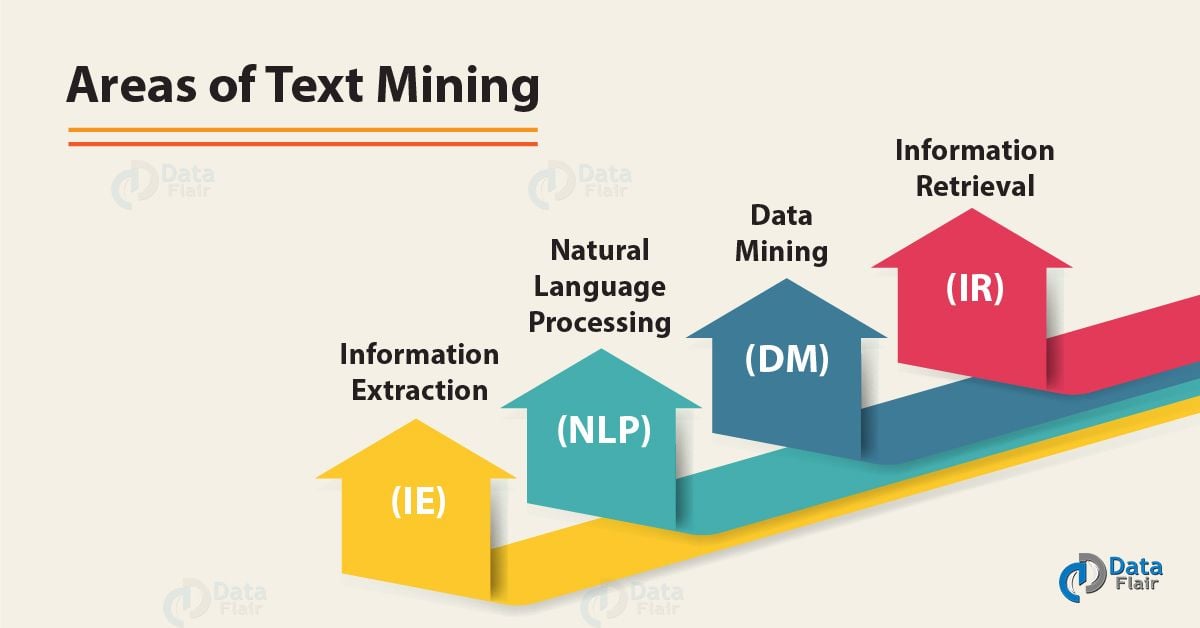
3. Areas of Text Mining in Data Mining
Following are the areas of text mining in Data Mining:
Areas of Text Mining in Data Mining
a. Information Retrieval (IR)
Information retrieval is regarded as an extension to document retrieval. That the documents that are returned are processed to condense. Thus document retrieval follow by a text summarization stage. That focuses on the query posed by the user. IR systems help in to narrow down the set of documents that are relevant to a particular problem. As text mining involves applying very complex algorithms to large document collections. Also, IR can speed up the analysis significantly by reducing the number of documents.
b. Data Mining (DM)
Data mining can
loosely describe as looking for patterns in data. It can more characterize as the extraction of hidden from data. Data mining tools can predict behaviours and future trends. Also, it allows businesses to make positive, knowledge-based decisions. Data mining tools can answer business questions. Particularly that have
traditionally been too time-consuming to resolve. They search databases for hidden and unknown patterns.
c. Natural Language Processing (NLP)
NLP is one of the oldest and most challenging problems. It is the study of human language. So those computers can understand natural languages as humans do. NLP research pursues the vague question of how we understand the meaning of a sentence or a document. What are the indications we use to understand who did what to whom? The role of NLP in text mining is to deliver the system in the information extraction phase as an input.
d. Information Extraction (IE)
Information Extraction is the task of automatically extracting structured information from unstructured. In most of the cases, this activity includes processing human language texts by means of NLP.
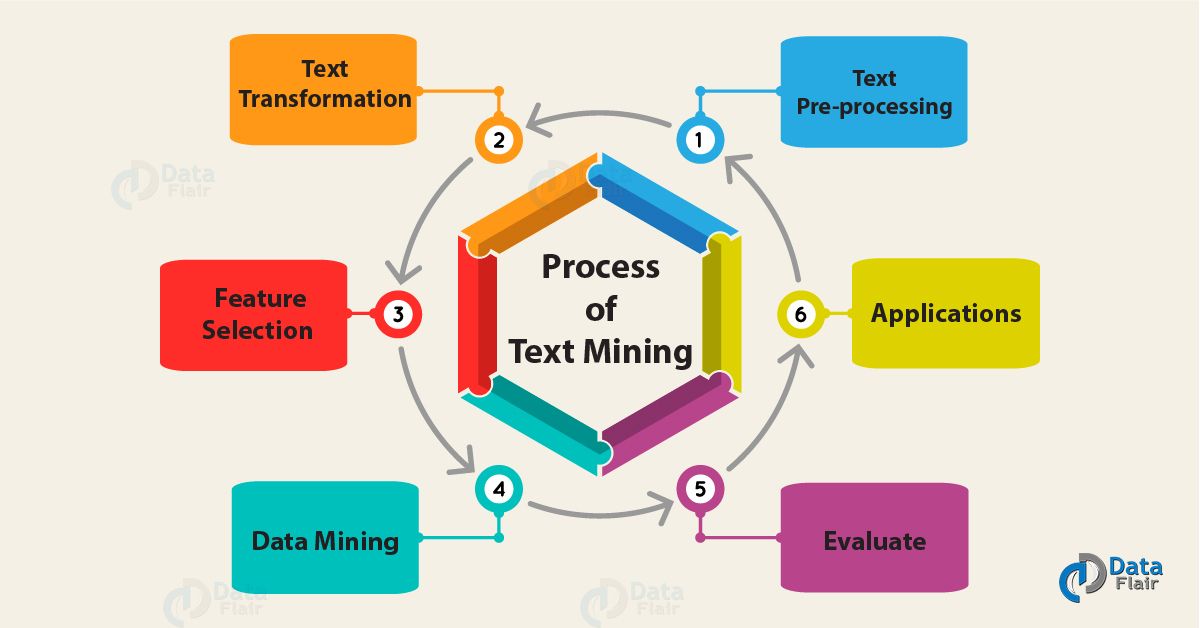
4. Text Mining Process
A process of Text mining involves a series of activities to perform to mine the information. These activities are:
The process of Text Mining
a. Text Pre-processing
It involves a series of steps as shown in below:
Text Cleanup means removing any unnecessary or unwanted information. Such as remove ads from web pages, normalize text converted from binary formats.
Tokenizing is simply achieved by splitting the text into white spaces.
Part-of-Speech (POS) tagging means word class assignment to each token. Its input is given by the tokenized text. Taggers have to cope with unknown words (OOV problem) and ambiguous word-tag mappings.
b. Text Transformation (Attribute Generation)
A text document is represented by the words it contains and their occurrences. Two main approaches to document representation are:
i. Bag of words
ii. Vector Space
c. Feature Selection (Attribute Selection)
Feature selection also is known as variable selection. It is the process of selecting a subset of important features for use in model creation. Redundant features are the one which provides no extra information. Irrelevant features provide no useful or relevant information in any context.
d. Data Mining
At this point, the Text mining process merges with the traditional process. Classic Data Mining techniques are used in the structured database. Also, it resulted from the previous stages.
e. Evaluate
Evaluate the result, after evaluation, the result discard.
f. Applications
Text Mining applies in a variety of areas. Some of the most common areas are
These days web contains a treasure of information about subjects. Such as persons, companies, organizations, products, etc. that may be of wide interest. Web Mining is an application of data mining techniques. That need to discover hidden and unknown patterns from the Web. Web mining is an activity of identifying term implied in a large document collection. It says C which denotes by a mapping i.e. C →p [10].
Users exchange information with others about subjects of interest. Everyone wants to understand specific diseases, to inform about new therapies. Also, these expert forums also represent seismographs for medical. E-mails, e-consultations, and requests for medical advice. That is via the internet have been analyzed using quantitative or qualitative methods.
Big enterprises and headhunters receive thousands of resumes from job applicants every day. Extracting information from resumes with high precision and recall is not easy. Automatically extracting this information can the first step in filtering resumes. Hence, automating the process of resume selection is an important task.
5. Approaches to Text Mining in Data Mining
Using well-tested methods and understanding the results of text mining. Once a data matrix has been computed from the input documents. And words found in those documents, various well-known analytic techniques. AS it is used for further processing those data including methods for clustering.
“Black-box” approaches to text mining and extraction of concepts. There are text mining applications which offer “black-box” methods. That need to extract “deep meaning” from documents with little human effort. These text mining applications rely on proprietary algorithms.
6. Numericizing Text
Following are issues and considerations for Numericizing Text.
i. Large numbers of large documents
Examples of scenarios using large numbers of small were given earlier. But, if your intent is to extract “concepts” from only a few documents that are very large. Then analyses are less powerful because the “number of cases” in this case is very small. While the “number of variables” (extracted words) is very large.
ii. Excluding certain characters, short words, numbers, etc
Excluding numbers, certain characters can be done easily. But before the indexing of the input documents starts. You may also want to exclude “rare words,”. As defined as those that only occur in a small percentage of the processed documents.
iii. Include lists, exclude lists (stop-words)
This is useful when you want to search for particular words. Also, classifying the input documents based on the frequencies. Also, “stop-words,” i.e., terms that are to exclude from the indexing can define. Typically, a default list of English stop words includes “the”, “a”, “of”, “since,”. That is words that are used in the respective language very frequently. But communicate very little unique information about the contents of the document.
iv. Synonyms and phrases
Synonyms, such as “sick” or “ill”, or words that are used in particular phrases. Where they denote unique meaning and can combine for indexing.
“Microsoft Windows” might be such a phrase. That is a specific reference to the computer operating system. But has nothing to do with the common use of the term “Windows”. As it might, for example, use in descriptions of home improvement projects.
v. Stemming algorithms
An important pre-processing step before indexing of input documents. As it begins is the stemming of words. The term “stemming” refers to the reduction of words to their roots. So that, for example, different grammatical forms.
vi Support for different languages
Stemming, synonyms, the letters that are permitted in words. Also, are highly language dependent operations. Therefore, support for different languages is important.
7. Incorporating Text Mining Results
Incorporating Text Mining Results in Data Mining Projects, after significant words have been extracted from a set of input documents. And after singular value decomposition has been applied to extract salient semantic dimensions. Typically the next and most important step is to use the extracted information.
a. Graphics (visual data mining methods)
Depending on the purpose of the analyses, in some instances. We need extraction of semantic dimensions alone. As it can be a useful outcome if it clarifies the underlying structure.
b. Clustering and factoring
You can use cluster analysis methods to identify groups of documents. Also, to identify groups of similar input texts. This type of analysis also useful in the context of market research studies.
For example- of new car owners. You can also use Factor Analysis and Principal Components and Classification Analysis.
c. Predictive data mining
Another possibility is to use the raw as predictor variables in mining projects.
8. Text Mining Applications
Unstructured text is very common. And may represent the majority of information available to a particular research.
Text Mining Application
a. Analyzing open-ended survey responses
In survey research, it is not uncommon to include various open-ended questions. That is pertaining to the topic under investigation. The idea is to permit respondents to express their “views”. Also, opinions without constraining them to particular dimensions or a particular response format.
b. Automatic processing of messages, emails, etc
Another common application is to aid in the automatic classification of texts.
It is possible to “filter” out automatically most undesirable “junk email”. That is based on certain terms or words that are not likely to appear in legitimate messages. Although, instead identify undesirable electronic mail. In this manner, such messages can automatically discard. Such automatic systems for classifying electronic messages can also be useful in applications. That messages need to route to the most appropriate department. At the same time, the emails are screened for inappropriate or obscene messages. That are automatically returned to the sender with a request to remove the offending words or content.
c. Analyzing warranty or insurance claims, diagnostic interviews, etc
In some business domains, the majority of information is collected in open-ended.
Warranty claims or initial medical interviews can summarize in brief narratives. Increasingly, those notes are collected electronically. So those types of narratives are readily available for input. This information can then usefully exploit to, Likewise, in the medical field. Also, open-ended descriptions by patients of their own symptoms. That might yield useful clues for the actual medical diagnosis.
d. Investigating competitors by crawling their websites
Another type of application is to process the contents of Web pages in a particular domain.
You could go to a Web page, and begin “crawling” the links you find there to process all Web pages that are referenced. In this manner, you could derive a list of terms and documents available at that site. Hence determine the most important terms and features that are described.
9. Advantages & Disadvantages of Text Mining
Following are the pros and cons of Text Mining in Data Mining:
a. Advantages of Text Mining
Web mining essentially has many advantages. That make this technology attractive to corporations including the government agencies. This technology has enabled e-commerce to do personalized marketing. As it includes eventually results in higher trade volumes. The government agencies are using this technology to classify threats. The predicting capability can benefit the society by identifying criminal activities. The companies can establish a better customer relationship. Exactly by giving them exactly what they need. Companies can understand the needs of the customer better. Further, they can react to customer needs faster.
b. Disadvantages of Text Mining
Web mining the technology itself doesn’t create issues. Although, this technology when used on data of personal nature might cause concerns.
The most criticized ethical issue involving web mining is the invasion of privacy. Privacy is considered lost when information concerning an individual is obtained. The obtained data will analyze, and clustered to form profiles. Also, the data will make anonymous before clustering. So that no individual can link directly to a profile. But usually, the group profiles are used as if they are personal profiles. Thus these applications de-individualize the users by judging them by their mouse clicks.
De-individualization can define as a tendency of judging and treating people. Particularly, on the basis of group characteristics.
Another important concern is that the companies collecting the data. That is for a specific purpose might use the data for a totally different purpose. And this essentially violates the user’s interests. The growing trend of selling personal data as a commodity encourages website owners. That is to trade personal data obtained from their site. This trend has increased the amount of data being captured. Also, traded increasing the likeliness of one’s privacy being invaded.
So, this was all about Text Mining in data Mining. Hope you like our explanation.
10. Conclusion
As a result, we have studied what is Text Mining. Also, have learned a process, approaches along with applications and pros and cons of Text Mining. I hope this blog will help you to understand Text Mining. Furthermore, if you have any query, feel free to ask in a comment section.
See Also-
You give me 15 seconds I promise you best tutorials
Please share your happy experience on Google






BEST DETAILS OF TEXT MINING
Hi Shruti,
It’s our pleasure you like our “Text Mining in Data Mining” Tutorial. As you enjoy reading this Data Mining Tutorial, hope you are giving a chance to other interesting topics of the same technology. We refer you to must go for Data Mining Interview Questions to check you learning.
Regards,
Data-Flair
How the text transformation will be achieved?? Example techniques