Data Mining Architecture – Data Mining Types and Techniques
Machine Learning courses with 100+ Real-time projects Start Now!!
In this Data mining Tutorial, we will study Data Mining Architecture. Also, will learn types of Data Mining Architecture, and Data Mining techniques with required technologies drivers.
So, let’s start the Architecture of Data Mining.
What is Data Mining?
We can say it is a process of extracting interesting knowledge from large amounts of data. That is stored in many data sources. Such as file systems, databases, data warehouses. Also, knowledge used to contributes a lot of benefits to business and individual.
Data Mining Architecture
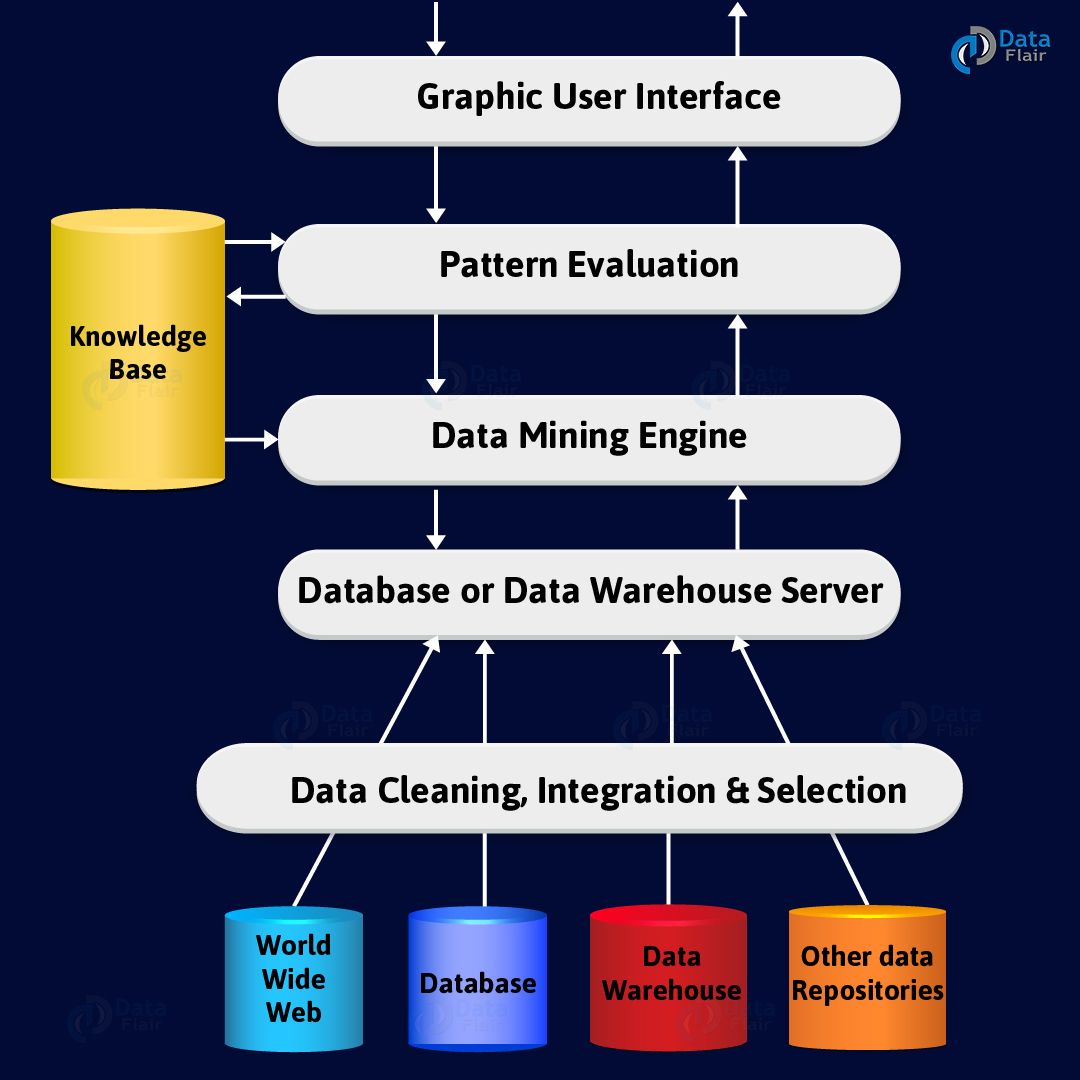
Data mining Architecture system contains too many components. That is a data source, data warehouse server, data mining engine, and knowledge base.
a. Data Sources
There are so many documents present. That is a database, data warehouse, World Wide Web (WWW). That are the actual sources of data. Sometimes, data may reside even in plain text files or spreadsheets. World Wide Web or the Internet is another big source of data.
b. Database or Data Warehouse Server
The database server contains the actual data that is ready to be processed. Hence, the server handles retrieving the relevant data. That is based on the data mining request of the user.
c. Data Mining Engine
In data mining system data mining engine is the core component. As It consists a number of modules. That we used to perform data mining tasks. That includes association, classification, characterization, clustering, prediction, etc.
d. Pattern Evaluation Modules
This module is mainly responsible for the measure of interestingness of the pattern. For this, we use a threshold value. Also, it interacts with the data mining engine. That’s main focus is to search towards interesting patterns.
e. Graphical User Interface
We use this interface to communicate between the user and the data mining system. Also, this module helps the user use the system easily and efficiently. They don’t know the real complexity of the process.
When the user specifies a query, this module interacts with the data mining system. Thus, displays the result in an easily understandable manner.
f. Knowledge Base
In whole data mining process, the knowledge base is beneficial. We use it to guiding the search for the result patterns. The knowledge base might even contain user beliefs and data from user experiences. That can be useful in the process of data mining.
The data mining engine might get inputs from the knowledge. That is the base to make the result more accurate and reliable. The pattern evaluation module interacts with the knowledge base. That is on a regular basis to get inputs and also to update it.
Types of Data Mining Architecture
Data is collected through business transactions and stored in relational database systems. Also, these business processes have been built to provide analytical reports. That is for business users to make decisions. As also data is now stored in database or data warehouse system? So data mining system should be designed to decouple.
This question leads to four possible architectures:
a. No-coupling Data Mining
In this architecture, data mining system does not use any functionality of a database. A no-coupling data mining system retrieves data from a particular data sources.
The no-coupling data mining architecture does not take any advantages of a database. That is already very efficient in organizing, storing, accessing and retrieving data. The no-coupling architecture is considered a poor architecture for data mining system. But it is used for simple data mining processes.
b. Loose Coupling Data Mining
In this architecture, data mining system uses a database for data retrieval. In loose coupling, data mining architecture, data mining system retrieves data from a database. And it stores the result in those systems.
Data mining architecture is for memory-based data mining system. That does not must high scalability and high performance.
c. Semi-Tight Coupling Data Mining
In semi-tight coupling, data mining system uses several features of data warehouse systems. That is to perform some data mining tasks. That includes sorting, indexing, aggregation. In this, some intermediate result can be stored in a database for better performance.
d. Tight Coupling Data Mining
In tight coupling, a data warehouse is treated as an information retrieval component. All the features of database or data warehouse are used to perform data mining tasks. This architecture provides system scalability, high performance, and integrated information.
There are three tiers in the tight-coupling data mining architecture:
i. Data Layer
We can define data layer as a database or data warehouse systems. This layer is an interface for all data sources. Data mining results are stored in the data layer. Thus, we can present to end-user in form of reports or another kind of visualization.
ii. Data mining application layer
It is to retrieve data from a database. Some transformation routine has to perform here. That is to transform data into the desired format. Then we have to process data using various data mining algorithms.
iii. Front-end layer
It provides the intuitive and friendly user interface for end-user. That is to interact with data mining system. Data mining result presented in visualization form to the user in the front-end layer.
Data Mining Techniques
There are several data mining techniques present, mentioned below
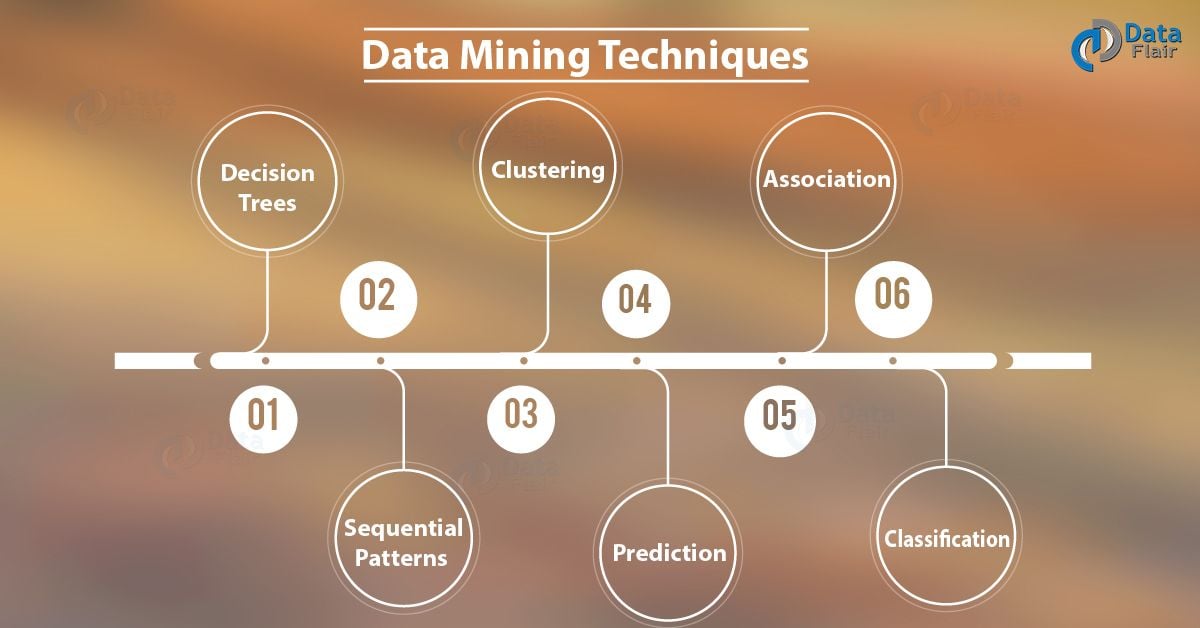
a. Decision Trees
It’s the most common technique, we use for data mining. As because of its simplest structure. The root of decision tree act as a condition. Each answer leads to specific data that help us to determine final decision based upon it.
b. Sequential Patterns
As we use this to discover regular events, similar patterns in transaction data. The historical data of customers helps us to identify the past transactions in a year.
c. Clustering
Having similar characteristics clusters objects have to form, by using automatic method. We use clustering, to define classes. Then suitable objects have to place in each class.
d. Prediction
We use this method defines the relationship between independent and dependent instances.
e. Association
It is also known as relation technique. Also, in this, we have to recognize a pattern. That it is based upon the relationship of items in a single transaction.
Also, we can suggest the technique for market basket analysis. That is to explore the products that customer frequently demands.
f. Classification
This is based on machine learning. We use this to classify each item in a particular set into predefined groups. Although, this method adopts mathematical techniques. Such as neural networks, linear programming, and decision trees and so on.
Required Technological Drivers
As data mining applications are present for all size machines. Such as mainframe, workstations, clouds, client, and server. The size of enterprise applications varies from 10 Gb to 100 Tb. NCR systems are preferring for deliver the applications exceeding 100 Tb. The technological drivers are as
a. Database size
As for maintaining and processing the huge amount of data, we need powerful systems.
b. Query Complexity
To analyze the complex and large number of queries, we need a more powerful system.
Conclusion
As a result, we have studied Data Mining Architecture. Also, learned it’s one of the types. Along with this, we have studied it’s techniques also. Furthermore, if you feel any query feel free to ask in a comment section.
If you are Happy with DataFlair, do not forget to make us happy with your positive feedback on Google




