Data Mining Process – Cross-Industry Standard Process For Data Mining
Machine Learning courses with 100+ Real-time projects Start Now!!
In this Data Mining Tutorial, we will study the Data Mining Process. Further, we will study the cross-industry data mining process (CRISP-DM). We will try to cover everything in detail for the better understanding process of data mining.
So, let’s start Phases of Data Mining Process.
What is Data Mining?
Data mining is the latest technology. As it is a process of discovering hidden valuable knowledge by analyzing a large amount of data. Also, we have to store that data in different databases.
As data mining is a very important process. It becomes an advantage for various industries. Such as manufacturing, marketing, etc. to increase their business efficiency. Therefore, the needs for a standard data mining process increased dramatically.
This data mining process must be reliable. Also, this process is repeatable by business people no knowledge of this process.
Stages of Data Mining Process
Data Mining Process is classified into two stages: Data preparation or data preprocessing and data mining
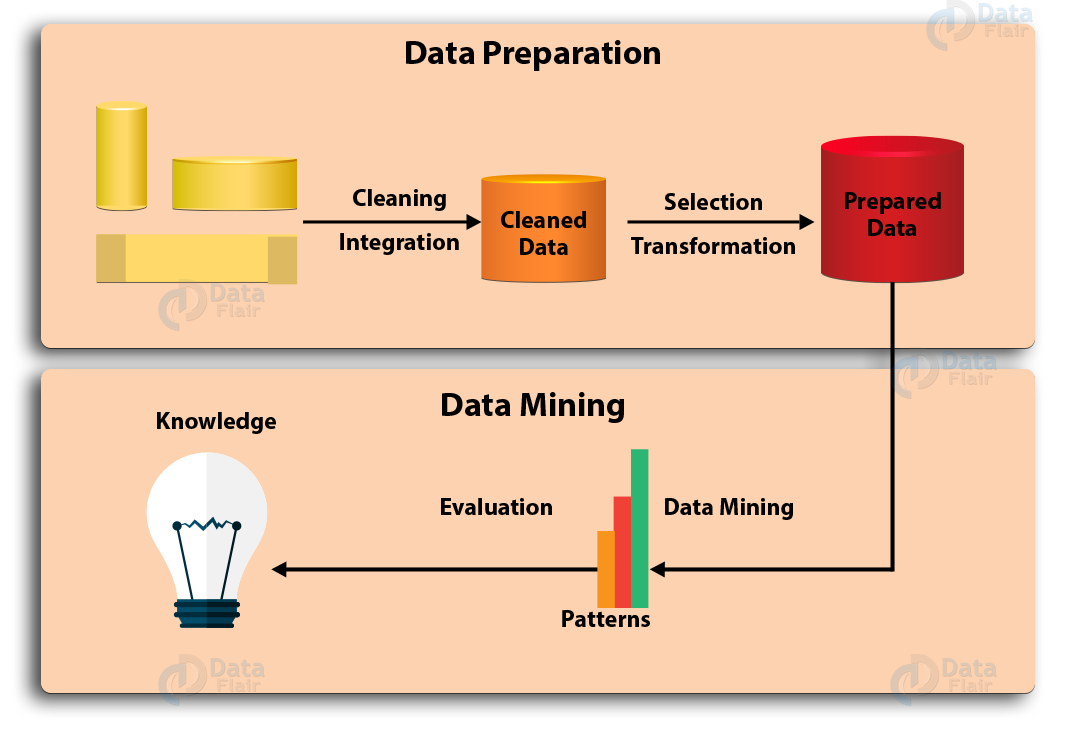
Stages of Data Mining Process
Data preparation process includes data cleaning, data integration, data selection and data transformation. Whereas the second phase includes data mining, pattern evaluation, and knowledge representation.
a. Data Cleaning
In the phase of data mining process, data gets cleaned. As we know data in the real world is noisy, inconsistent and incomplete.
It includes a number of techniques. Such as filling in the missing values, combined compute. The output of the data cleaning process is adequately cleaned data.
b. Data Integration
In this phase of Data Mining process data in integrated from different data sources into one. As data lies in different formats in a different location.
We can store data in a database, text files, spreadsheets, documents, data cubes, and so on. Although, we can say data integration is so complex, tricky and difficult task. That is because normally data doesn’t match the different sources.
We use metadata to reduce errors in the data integration process. Another issue faced is data redundancy. In this case, the same data might be available in different tables in the same database. Data integration tries to reduce redundancy to the maximum possible level. As without affecting the reliability of data.
c. Data Selection
This is the process by which data relevant to the analysis is retrieved from the database. As this process requires large volumes of historical data for analysis. So, usually, the data repository with integrated data contains much more data than actually required. From the available data, data of interest needs to be selected and stored.
d. Data Transformation
In this process, we have to transform and consolidate the data into different forms. That must be suitable for mining. Normally this process includes normalization, aggregation, generalization etc.
For example, a data set available as “-5, 37, 100, 89, 78” can be transformed as “-0.05, 0.37, 1.00, 0.89, 0.78”. Here data becomes more suitable for data mining. After data integration, the available data is ready for data mining.
e. Data Mining
In this phase of Data Mining process, we have applied methods to extract patterns from the data. As these methods are complex and intelligent. Also, this mining includes several tasks. Such as classification, prediction, clustering, time series analysis and so on.
f. Pattern Evaluation
The pattern evaluation identifies the truly interesting patterns. That is representing knowledge based on different types of interesting measures. A pattern is considered to be interesting if it is potentially useful. Also, easily understandable by humans.
Further, it validates some hypothesis. That someone wants to confirm new data with some degree of certainty.
g. Knowledge Representation
In the phase of Data Mining process, we have to represent data to the user in an appealing way. Also, that information is mined from the data. To generate output different techniques are need to be applied.
Cross-Industry Standard Process For Data Mining (CRISP-DM)
Cross-Industry Standard Process consists of six phases. Also, it’s a cyclical process.
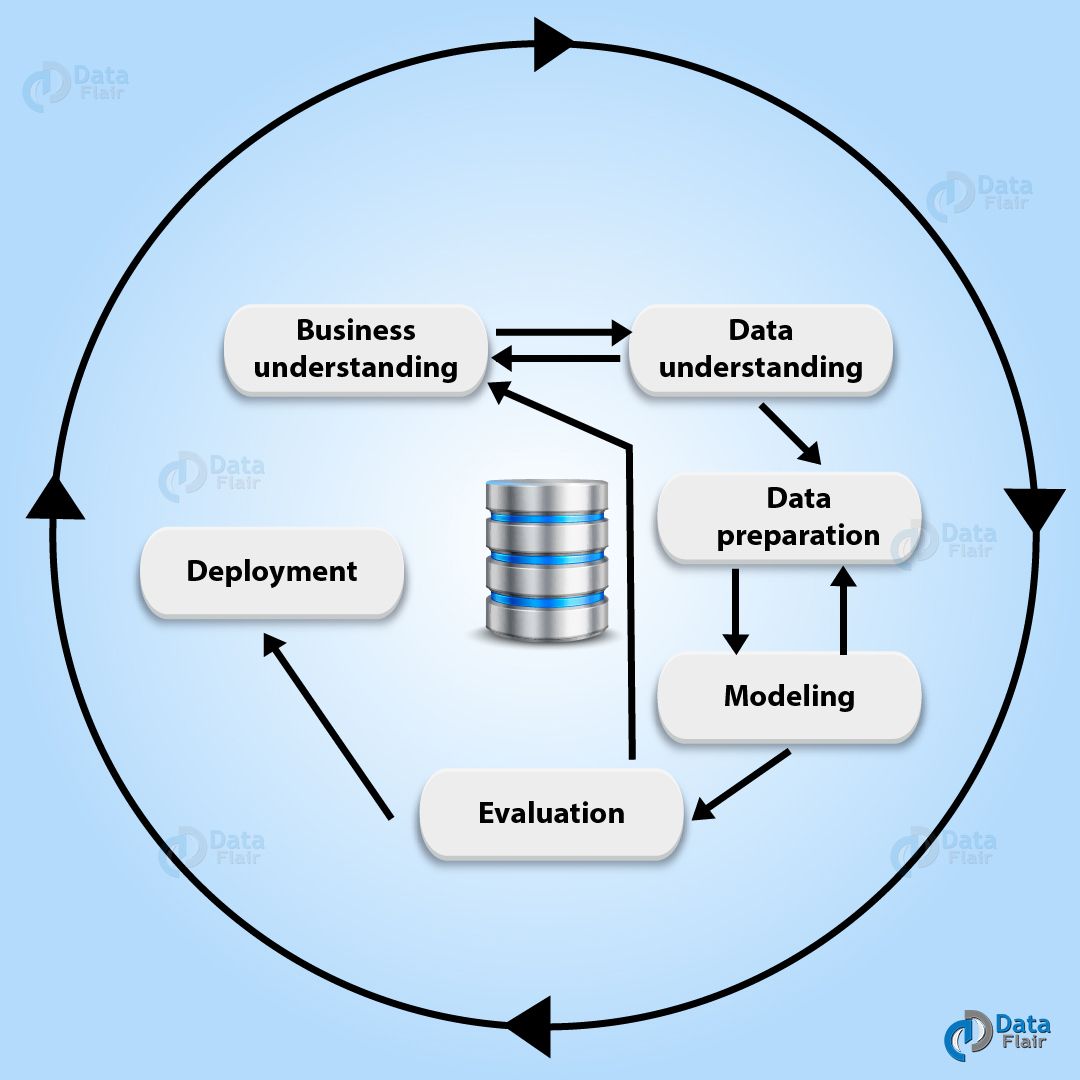
Stages of Data Mining Process
a. Business Understanding
- First, we have to understand the requirements. Then have to find what are the business requirements.
- Next, the current situation has to access by finding out the different resources, assumptions. Also, by considering other important factors.
- Then, to achieve the business objectives we need to create data mining.
- Finally, we have to establish a new data mining plan to achieve both business and data mining goals. The plan should be as detailed as possible.
b. Data Understanding
- First, this phase starts with the collection of initial data. As in this, we have to collect data from available sources. As we have to collect data to get familiar with the data. Also, in order to make data collection, we need some activities that need to perform. Such as data load and data integration.
- Next, the “gross” or “surface” properties of acquired data need to examine and report.
- Then, we need to explore the data needs by tackling the data mining questions. That can be addressed using querying, reporting, and visualization.
- Finally, have to examine the data quality by answering some important questions. Such as “Is the acquired data complete?”, “Is there any missing values in the acquired data?”
c. Data Preparation
In this data, the preparation process our 90% time consumed in our project. Also, it’s outcome is the final data set.
Once we identify the data sources, then we need to select, clean, construct and have to format in the desired form. The data exploration task has to be done at a greater depth. That need to be carry during this phase to notice the patterns. That is based on business understanding.
d. Modelling
- First, we have to select modelling techniques that we need to use for the prepared dataset.
- Next, we have to generate a test scenario to validate the quality and validity of the model.
- Then, by using modelling tools we have to prepare one or more models on the dataset.
- Finally, by involving these models need to assess involving stakeholders. That is to make sure that created models are met business initiatives.
e. Evaluation
- Particularly, in this case, have to evaluate the result in the context of the business goal.
- In this phase, due to new patterns, new business requirements occurs. That patterns have to discover in the model results or from other factors. Gaining business understanding is an iterative process in data mining. The go or no-go decision must make in this step to move to the deployment phase.
f. Deployment
The information, which we gain through data mining process, we need to present it. The information has to represent in such a way that stakeholders can use it whenever they want it. Based on the business requirements, the deployment phase could be creating a report.
Also, as complex as a repeatable data mining process across the organization. In this plans for deployment, maintenance, have to create for implementation. and also future supports. From the project point, the final report needs to summary the project experiences. And, the review the project to see what need to improved created learned lessons.
The CRISP-DM offers a uniform framework for experience documentation and guidelines. In addition, the CRISP-DM can apply in various industries with different types of data.
So, this was all about Data Mining Process Tutorial. Hope you like our explanation.
Conclusion
As a result, we have studied the Data Mining Process. Along with this have learned stages of data with diagram and cross-industry standard process(CRISP-DM). Furthermore, if you feel any query feel free to ask in a comment section.
We work very hard to provide you quality material
Could you take 15 seconds and share your happy experience on Google





Hello Data Flair,
I’m currently writing my bachelor thesis on data and text mining and I was wondering which source you used for the figure “stages of data mining process”. It would help me lot!
Amazing article by the way – keep it going!
Hi Philips,
Thanks for commenting on “Data Mining Process”. We are glad that our Data Mining Tutorial, helps in your thesis.
Our bloggers refer to a gamut of books, blogs, scholarly articles, white papers, and other resources before producing a tutorial to bring you the best. You can explore our platform for more resources to find your way through your thesis and improve the quality of work you produce.
Best of Luck For your Thesis and keep visiting.
Regard,
Data-Flair
Example of data mining