Hadoop Pig Tutorial: A Comprehensive Guide to Pig Hadoop
While it comes to analyze large sets of data, as well as to represent them as data flows, we use Apache Pig. It is nothing but an abstraction over MapReduce. So, in this Hadoop Pig Tutorial, we will discuss the whole concept of Hadoop Pig.
Apart from its Introduction, it also includes History, need, its Architecture as well as its Features. Moreover, we will see, some Comparisons like Pig Vs Hive, Apache Pig Vs SQL and Hadoop Pig Vs MapReduce.
So, let’s start the Hadoop Pig Tutorial.
What is Hadoop Pig?
Hadoop Pig is nothing but an abstraction over MapReduce. While it comes to analyze large sets of data, as well as to represent them as data flows, we use Apache Pig. Generally, we use it with Hadoop. By using Pig, we can perform all the data manipulation operations in Hadoop.
In addition, Pig offers a high-level language to write data analysis programs which we call as Pig Latin. One of the major advantages of this language is, it offers several operators.
Through them, programmers can develop their own functions for reading, writing, and processing data.
It has following key properties such as:
- Ease of programming
Basically, when all the complex tasks comprised of multiple interrelated data transformations are explicitly encoded as data flow sequences, that makes them easy to write, understand, and maintain.
- Optimization opportunities
It allows users to focus on semantics rather than efficiency, to optimize their execution automatically, in which tasks are encoded permits the system.
- Extensibility
In order to do special-purpose processing, users can create their own functions.
Hence, programmers need to write scripts using Pig Latin language to analyze data using Apache Pig.
However, all these scripts are internally converted to Map and Reduce tasks. It is possible with a component, we call as Pig Engine. That accepts the Pig Latin scripts as input and further convert those scripts into MapReduce jobs.
Next in Hadoop Pig Tutorial is it’s History.
Hadoop Pig Tutorial – History
Apache Pig was developed as a research project, in 2006, at Yahoo. Basically, to create and execute MapReduce jobs on every dataset it was created. By Apache incubator, Pig was open sourced, in 2007.
Then the first release of Apache Pig came out in 2008. Further, Hadoop Pig graduated as an Apache top-level project, in 2010.
Why Do We Need Apache Pig?
While performing any MapReduce tasks, there is a case Programmers who are not so good at Java normally used to struggle to work with Hadoop. Thus, we can say, Pig is a boon for all such programmers because:
- Without having to type complex codes in Java, using Pig Latin, programmers can perform MapReduce tasks easily.
- It also helps in reduce the length of codes, since Pig uses multi-query approach. Let’s understand it with an example. Here an operation that would require us to type 200 lines of code (LoC) in Java can be easily done by typing as less as just 10 LoC in Apache Pig. Hence, it shows, Pig reduces the development time by almost 16 times.
- When you are familiar with SQL, it is easy to learn Pig. Because Pig Latin is SQL-like language.
- It offers many built-in operators, in order to support data operations such as joins, filters, ordering, and many more. Also, it offers nested data types that are missing from MapReduce such as tuples, bags, and maps.
Further in the Hadoop Pig Tutorial, lets understand where can we use Pig.
Hadoop Pig Tutorial – Using Pig
There are several scenarios, where we can use Pig. Such as:
- While data loads are time sensitive.
- Also, while processing various data sources.
- While we require analytical insights through sampling.
Where Not to Use Pig?
Also, there are some Scenarios, where we can not use. Such as:
- While the data is completely unstructured. Such as video, audio, and readable text.
- Where time constraints exist. Since Pig is slower than MapReduce jobs.
- Also, when more power is required to optimize the codes, we cannot use Pig.
Architecture of Hadoop Pig
Here, the image, which shows the architecture of Apache Pig.
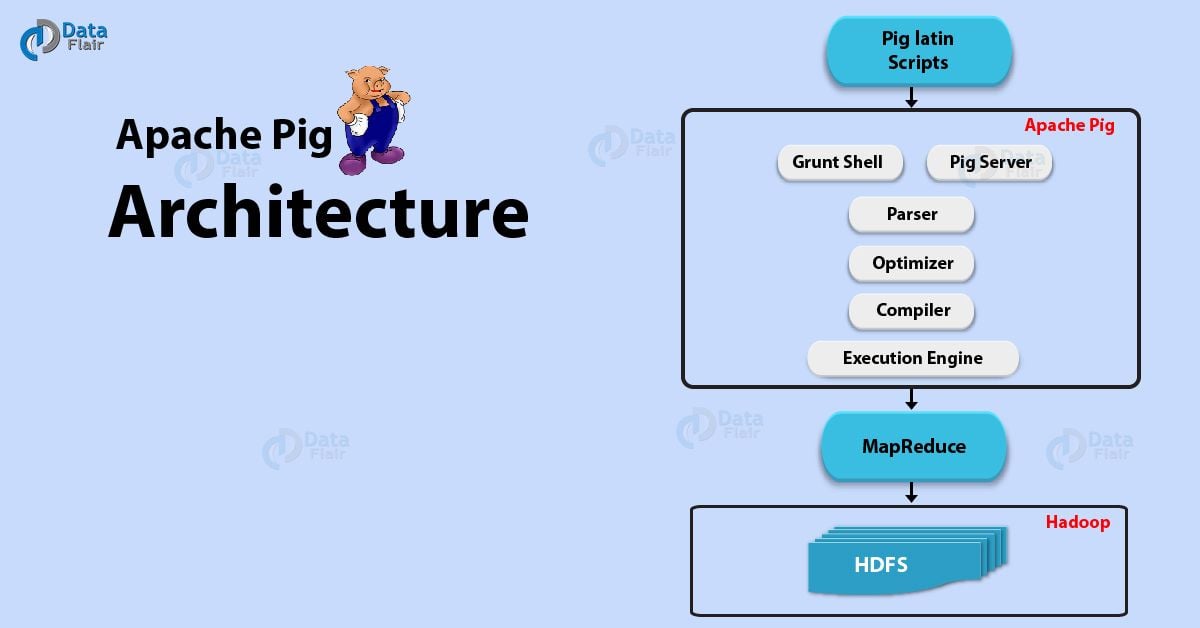
Apache Pig Architecture: Hadoop Pig Tutorial
Now, you can see, several components in the Hadoop Pig framework. The major components are:
i. Parser
At first, all the Pig Scripts are handled by the Parser. Basically, Parser checks the syntax of the script, does type checking, and other miscellaneous checks. Afterward, Parser’s output will be a DAG (directed acyclic graph). That represents the Pig Latin statements as well as logical operators.
Basically, the logical operators of the script are represented as the nodes and the data flows are represented as edges, in the DAG (the logical plan).
ii. Optimizer
Further, DAG is passed to the logical optimizer. That carries out the logical optimizations. Like projection and push down.
iii. Compiler
It compiles the optimized logical plan into a series of MapReduce jobs.
iv. Execution Engine
At last, MapReduce jobs are submitted to Hadoop in a sorted order. Hence, these MapReduce jobs are executed finally on Hadoop, that produces the desired results.
Hadoop Pig Tutorial – Pig Features
Now in the Hadoop Pig Tutorial is the time to learn the Features of Pig which makes it what it is. There are several features of Pig. Such as:
i. Rich set of operators
In order to perform several operations, Pig offers many operators. Such as join, sort, filer and many more.
ii. Ease of programming
Since you are good at SQL, it is easy to write a Pig script. Because of Pig Latin as same as SQL.
iii. Optimization opportunities
In Apache Pig, all the tasks optimize their execution automatically. As a result, the programmers need to focus only on the semantics of the language.
iv. Extensibility
Through Pig, it is easy to read, process, and write data. It is possible by using the existing operators. Also, users can develop their own functions.
v. UDFs
By using Pig, we can create User-defined Functions in other programming languages like Java. Also, can invoke or embed them in Pig Scripts.
vi. Handles all kinds of data
Pig generally analyzes all kinds of data. Even both structured and unstructured. Moreover, it stores the results in HDFS.
Recommended Skills prior to learning Pig
Such as:
- Basic knowledge of Linux Operating System
- Fundamental programming skills
Pig Vs MapReduce
Some major differences between Hadoop Pig and MapReduce, are:
- Apache Pig
It is a data flow language.
- MapReduce
However, it is a data processing paradigm.
- Hadoop Pig
Pig is a high-level language.
- MapReduce
Well, it is a low level and rigid.
- Pig
In Apache Pig, performing a Join operation is pretty simple.
- MapReduce
But, in MapReduce, it is quite difficult to perform a Join operation between datasets.
- Pig
With a basic knowledge of SQL, any novice programmer can work conveniently with Pig.
- MapReduce
But, to work with MapReduce, exposure to Java is essential.
- Hadoop Pig
Generally, it uses multi-query approach, thereby reducing the length of the codes to a great extent.
- MapReduce
Although, to perform the same task it needs almost 20 times more the number of lines.
- Apache Pig
Here, we do not require any compilation. Every Pig operator is converted internally into a MapReduce job, at the time of execution.
- MapReduce
It has a long compilation process.
Hadoop Pig Vs SQL
Here, are the major differences between Apache Pig and SQL.
- Pig
It is a procedural language.
- SQL
While it is a declarative language.
- Pig
Here, the schema is optional. Although, without designing a schema, we can store data. However, it stores values as $01, $02 etc.
- SQL
In SQL, Schema is mandatory.
- Pig
In Pig, data model is nested relational.
- SQL
In SQL, data model used is flat relational.
- Pig
Here, we have limited opportunity for Query Optimization.
- SQL
While here we have more opportunity for query optimization.
Also, Apache Pig Latin −
- offer splits in the pipeline.
- Provides developers to store data anywhere in the pipeline.
- It also Declares execution plans.
- Offers operators to perform ETL (Extract, Transform, and Load) functions.
Any doubt yet in Hadoop Pig Tutorial. Please Comment.
Apache Pig Vs Hive
Basically, to create MapReduce jobs, we use both Pig and Hive. Also, we can say, at times, Hive operates on HDFS as same as Pig does. So, here we are listing few significant points those set Apache Pig apart from Hive.
- Hadoop Pig
Pig Latin is a language, Apache Pig uses. Originally, it was created at Yahoo.
- Hive
HiveQL is a language, Hive uses. It was originally created at Facebook.
- Pig
It is a data flow language.
- Hive
Whereas, it is a query processing language.
- Pig
Moreover, it is a procedural language which fits in pipeline paradigm.
- Hive
It is a declarative language.
- Apache Pig
Also, can handle structured, unstructured, and semi-structured data.
- Hive
Whereas, it is mostly for structured data.
Applications of Pig
For performing tasks involving ad-hoc processing and quick prototyping, data scientists generally use Apache Pig. More of its applications are:
- In order to process huge data sources like weblogs.
- Also, to perform data processing for search platforms.
- Moreover, to process time sensitive data loads.
So, this was all on Hadoop Pig Tutorial. Hope you like our explanation.
Conclusion – Hadoop Pig Tutorial
Hence, we have seen the whole concept of Hadoop Pig in this Hadoop Pig Tutorial. Apart from its usage, we have also seen where we can not use it. Also, we have seen its prerequisites to learn it well. However, if any doubt occurs, regarding Apache Pig, feel free to ask in the comment section.
Did you like our efforts? If Yes, please give DataFlair 5 Stars on Google




