Apache Pig Architecture and Execution Modes
In this article, we will cover the Apache Pig Architecture. It is actually developed on top of Hadoop. Moreover, we will see the various components of Apache Hive and Pig Latin Data Model. The Apache Pig provides a high-level language. We will also see the two modes to run this component.
So, let’s start Apache pig Architecture.
What is Apache Pig Architecture?
The language which analyzes data in Hadoop using Pig called as Pig Latin. Therefore, it is a high-level data processing language. While it provides a wide range of data types and operators to perform data operations.
To perform a task using Pig, programmers need to write a Pig script using the Pig Latin language. They execute them with any of the execution mechanisms such as (Grunt Shell, UDFs, Embedded).
These scripts will also go through a series of transformations after execution. Moreover, the Pig Framework produces the desired output.
Apache Pig converts these scripts into many MapReduce jobs. Thus, it makes the job easy for developers.
Components of Apache Pig
There are various components in Apache Pig Architecture which makes its execution faster as discussed below:
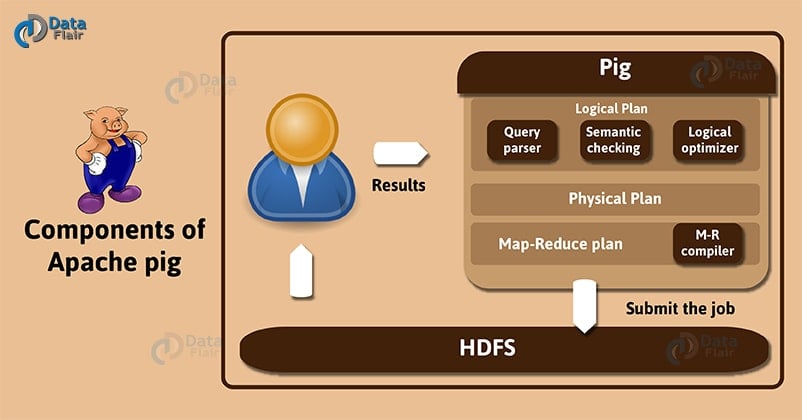
Components of Apache Pig
a. Parser
The Parser handles the Pig Scripts and checks the syntax of the script. It includes type checking with other checks. Therefore, an output of the parser will be a Directed Graph. However, it represents the Pig Latin statements and logical operators.
In the DAG, the script operators are actually represented as the nodes. Moreover, the data flows are eventually represented as edges.
b. Optimizer
The logical optimizer then receives the logical plan (DAG). In fact, it carries out the logical optimization such as projection and push down.
c. Compiler
The compiler converts the logical plan into a series of MapReduce jobs.
d. Execution Engine
In the end, the MapReduce jobs get submitted to Hadoop in a sorted order. Therefore these MapReduce jobs execute on the Hadoop and produce the desired results.
Pig Latin Data Model
There is a complete nested data model of Pig Latin. Meanwhile, it allows complex non-atomic data types such as map and tuple.
a. Field and Atom
Atom is a single value in Pig Latin, with any data type. The storage occurs in form of string and we can also use it as string and number. Various atomic values of Pig are int, long, float, double, chararray, and byte array.
Furthermore, any simple atomic value or data is actually considered as a field.
For Example − ‘dataflair’ or ‘12’
d. Tuples
A record which contains an ordered set of fields is a Tuple. Thus, the fields can be of any type. A tuple is same as the row in a table of RDBMS.
For Example − (Dataflair, 12)
c. Bag
A bag contains an unordered set of tuples. Therefore, a collection of tuples (non-unique) is can be a bag. Each tuple may have any number of fields. We can represent the bag as ‘{}’. It is same as a table in RDBMS.
However, it is not necessary that every tuple contains the same fields. Hence, the fields in the same position (column) may not have the same type.
Example − {(Dataflair, 12), (Training, 11)}
While a bag can be a field in a relation which is an inner bag.
Example − {Dataflair, 12, {1212121212, [email protected],}}
d. Map
A map (or data map) contains the set of many key-value pairs. Meanwhile, the key has to be of type chararray and unique. The value can be of any type. We can represent it by ‘[]’.
Example − [name#Dataflair, age#11]
e. Relation
Furthermore, a relation contains the bag of tuples. There may be no serial order of processing in the relations.
Job Execution Flow
The developer creates the scripts, and then it goes to the local file system as functions. Moreover, when the developers submit Pig Script, it contacts with Pig Latin Compiler.
The compiler then splits the task and run a series of MR jobs. Meanwhile, Pig Compiler retrieves data from the HDFS. The output file again goes to the HDFS after running MR jobs.
a. Pig Execution Modes
We can run Pig in two execution modes. These modes depend upon where the Pig script is going to run. It also depends on where the data is residing. We can thus store data on a single machine or in a distributed environment like Clusters.
The three different modes to run Pig programs are:
Non-interactive shell or script mode- The user has to create a file, load the code and execute the script. Then comes the Grunt shell or interactive shell for running Apache Pig commands.
Hence, the last one named as embedded mode, which we can use JDBC to run SQL programs from Java.
b. Pig Local mode
However, in this mode, pig implements on single JVM and access the file system. This mode is better for dealing with the small data sets. Meanwhile, the parallel mapper execution is impossible. The older version of the Hadoop is not thread-safe.
While the user can provide –x local to get into Pig local mode of execution. Therefore, Pig always looks for the local file system path while loading data.
c. Pig Map Reduce Mode
In this mode, a user could have proper Hadoop cluster setup and installations on it. By default, Apache Pig installs as in MR mode. The Pig also translates the queries into Map reduce jobs and runs on top of Hadoop cluster. Hence, this mode as a Map reduce runs on a distributed cluster.
The statements like LOAD, STORE read the data from the HDFS file system and to show output. These Statements are also used to process data.
d. Storing Results
The intermediate data generates during the processing of MR jobs. Pig stores this data in a non-permanent location on HDFS storage. The temporary location then created inside HDFS for storing this intermediate data.
We can use DUMP for getting the final results to the output screen. The output results stored using STORE operator.
So, this was all in Apache Pig Architecture. Hope you like our explanation.
Conclusion – Apache Pig Architecture
By providing a parallel mechanism and running the jobs across clusters, Pig is popularly used. The high-level scripting language gives developers an interface to get results. Pig also provides the optimization techniques for smooth data flow across a cluster.
Moreover, specific filtering, grouping, and iterations reduce the complexity of the code. They also run in an effective manner.
We work very hard to provide you quality material
Could you take 15 seconds and share your happy experience on Google




