Top 30 Apache Pig Interview Questions and Answers (Latest)
Today, in this article, we will discuss “Top 30 Apache Pig Interview Questions and answers”. Here, we are providing Advanced Apache Pig Interview Questions that will help you in cracking your interview as well as to acquire a dream career as Apache Pig Developer.
If we talk about the current world, there are a lot of opportunities in Pig Development in many reputed companies across the world.
However, to go for Pig jobs it is important to learn Apache Pig in deep. So, if you’re looking for Apache Pig Interview Questions & Answers for Experienced or Freshers, you are at right place.
So, let’s explore Mostly Asked Apache Pig Interview Questions
Best 30 Apache Pig Interview Questions and Answers
There are various prominent Apache Pig Interview Questions. So, let’s discuss top 30 Apache Pig Interview Questions along with their answers:
Que 1. Define Apache Pig
Ans. To analyze large data sets representing them as data flows, we use Apache Pig. Basically, to provide an abstraction over MapReduce, reducing the complexities of writing a MapReduce task using Java programming, Apache Pig is designed.
Moreover, using Apache Pig, we can perform data manipulation operations very easily in Hadoop.
Que 2. Why Do We Need Apache Pig?
Ans. At times, while performing any MapReduce tasks, programmers who are not so good at Java normally used to struggle to work with Hadoop. Hence, Pig is a boon for all such programmers. The reason is:
- Using Pig Latin, programmers can perform MapReduce tasks easily, without having to type complex codes in Java.
- Since Pig uses multi-query approach, it also helps in reducing the length of codes.
- It is easy to learn Pig when you are familiar with SQL. It is because Pig Latin is SQL-like language.
- In order to support data operations, it offers many built-in operators like joins, filters, ordering, and many more. And, it offers nested data types that are missing from MapReduce, for example, tuples, bags, and maps.
Que 3. What is the difference between Pig and SQL?
Ans. Here, are the list of major differences between Apache Pig and SQL.
- Pig
It is a procedural language.
- SQL
While it is a declarative language.
- Pig
Here, the schema is optional. Although, without designing a schema, we can store data. However, it stores values as $01, $02 etc.
- SQL
In SQL, Schema is mandatory.
- Pig
In Pig, data model is nested relational.
- SQL
In SQL, data model used is flat relational.
- Pig
Here, we have limited opportunity for query optimization.
- SQL
While here we have more opportunity for query optimization.
Que 4. Explain the architecture of Hadoop Pig.
Ans. Below is the image, which shows the architecture of Apache Pig.
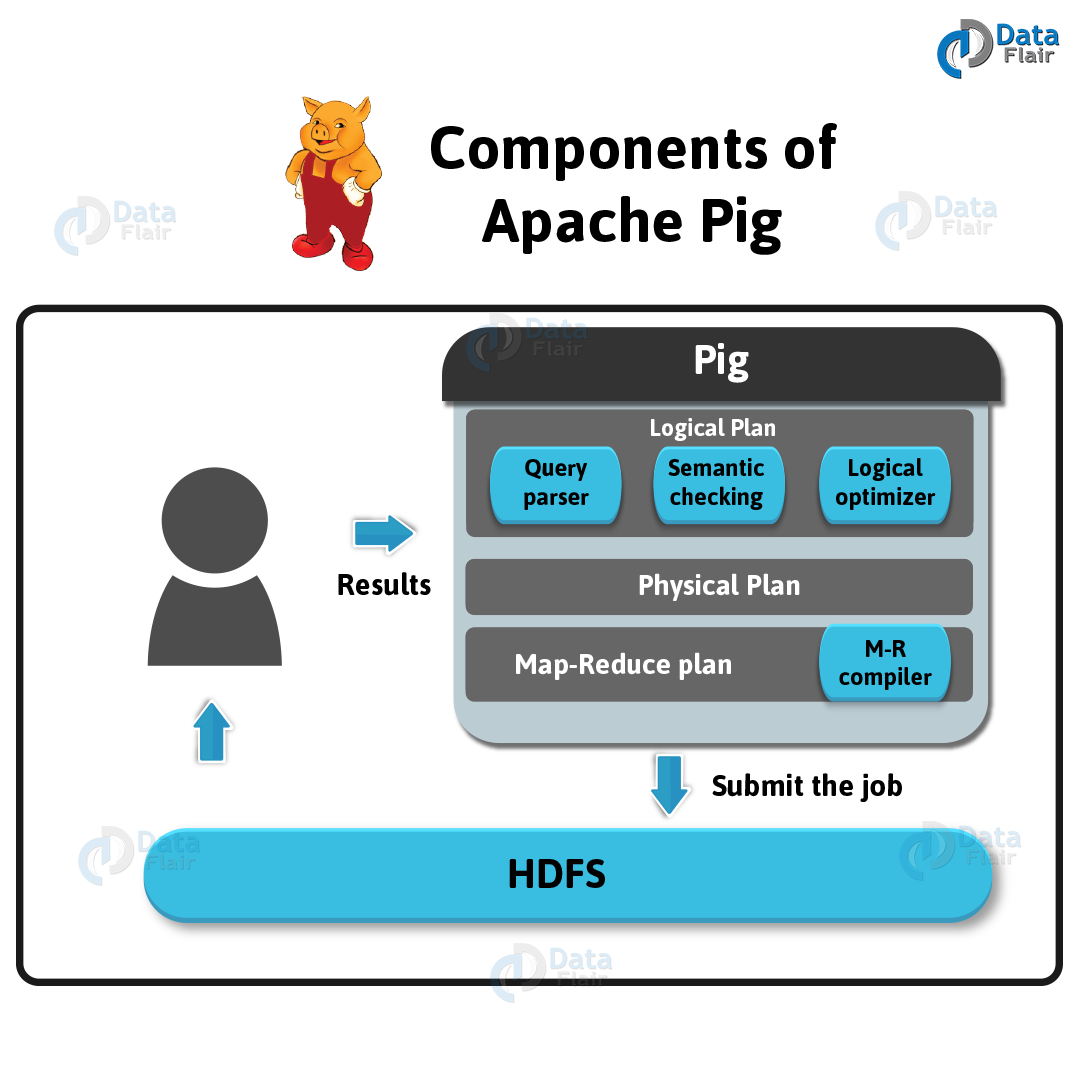
Best 30 Apache Pig Interview Questions and Answers
Now, we can see, several components in the Hadoop Pig framework. The major components are:
1. Parser
At first, Parser handles all the Pig Scripts. Basically, Parser checks the syntax of the script, does type checking, and other miscellaneous checks. Afterward, Parser’s output will be a DAG (directed acyclic graph). That represents the Pig Latin statements as well as logical operators.
Basically, the logical operators of the script are represented as the nodes and the data flows are represented as edges, in the DAG (the logical plan).
2. Optimizer
Further, DAG is passed to the logical optimizer. That carries out the logical optimizations, like projection and push down.
3. Compiler
A series of MapReduce jobs have compiled from an optimized logical plan.
4. Execution engine
At last, these jobs are submitted to Hadoop in a sorted order. Hence, these MapReduce jobs are executed finally on Hadoop, that produces the desired results.
Que 5. What is the difference between Apache Pig and Hive?
Ans. Basically, to create MapReduce jobs, we use both Pig and Hive. Also, we can say, at times, Hive operates on HDFS as same as Pig does. So, here we are listing few significant points those set Apache Pig apart from Hive.
- Hadoop Pig
Pig Latin is a language, Apache Pig uses. Originally, it was created at Yahoo.
- Hive
HiveQL is a language, Hive uses. It was originally created at Facebook.
- Pig
It is a data flow language.
- Hive
Whereas, it is a query processing language.
- Pig
Moreover, it is a procedural language which fits in pipeline paradigm.
- Hive
It is a declarative language.
- Apache Pig
Also, can handle structured, unstructured, and semi-structured data.
- Hive
Whereas, it is mostly for structured data.
Que 6. What is the difference between Pig and MapReduce?
Ans. Some major differences between Hadoop Pig and MapReduce, are:
- Apache Pig
It is a data flow language.
- MapReduce
However, it is a data processing paradigm.
- Hadoop Pig
Pig is a high-level language.
- MapReduce
Well, it is a low level and rigid.
- Pig
In Apache Pig, performing a join operation is pretty simple.
- MapReduce
But, in MapReduce, it is quite difficult to perform a join operation between datasets.
Que 7. Explain Features of Pig.
Ans. There are several features of Pig, such as:
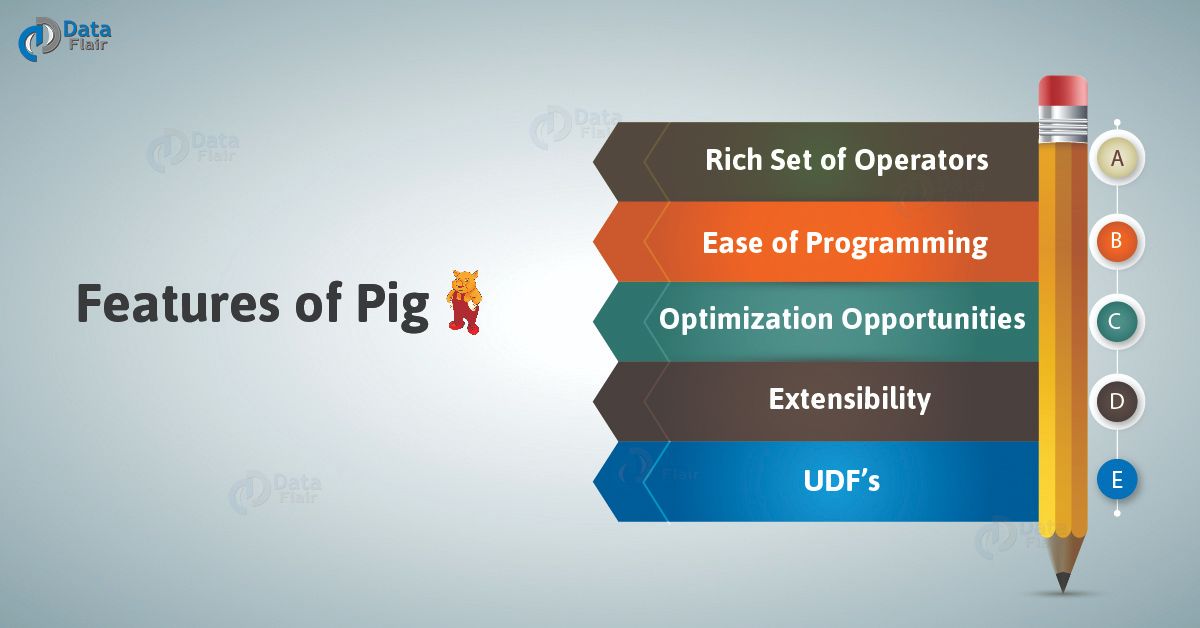
Features of Pig
- Rich set of operators
In order to perform several operations, Pig offers many operators, for example, join, sort, filer and many more.
- Ease of programming
Since you are good at SQL, it is easy to write a Pig script. Because of Pig Latin as same as SQL.
- Optimization opportunities
In Apache Pig, all the tasks optimize their execution automatically. As a result, the programmers need to focus only on the semantics of the language.
- Extensibility
Through Pig, it is easy to read, process, and write data. It is possible by using the existing operators. Also, users can develop their own functions.
- UDF’s
By using Pig, we can create User-defined Functions in other programming languages. Like Java. Also, can invoke or embed them in Pig Scripts.
Que 8. What is Pig Storage?
Ans. In Pig, there is a default load function, that is Pig Storage. Also, we can use pig storage, whenever we want to load data from a file system into the pig.
We can also specify the delimiter of the data while loading data using pig storage (how the fields in the record are separated). Also, we can specify the schema of the data along with the type of the data.
Que 9. While writing evaluate UDF, which method has to be overridden?
Ans. We have to override the method exec() while writing UDF in the Pig. Whereas the base class can be different while writing filter UDF, we will have to extend FilterFunc and for evaluate UDF, we will have to extend the EvalFunc. EvaluFunc is parameterized and must provide the return type also.
Que 10. What are the different UDF’s in Pig?
Ans. On the basis of the number of rows, UDF can be processed. They are of two types:
- UDF that takes one record at a time, for example, Filter and Eval.
- UDFs that take multiple records at a time, for example, Avg and Sum.
Also, pig gives you the facility to write your own UDF’s for load/store the data.
Apache Pig Interview Questions and Answers For Freshers. Q- 1,2,4,7
Apache Pig Interview Questions and Answers For Experience. Q- 3,5,6,8,9,10
Que 11. What are the Optimizations a developer can use during joins?
Ans. We use replicated join, to perform join between a small dataset with a large dataset. Moreover, in the replicated join, the small dataset will be copied to all the machines where the mapper is running and the large dataset is divided across all the nodes. Also, it gives us the advantage of Map-side joins.
If your dataset is skewed i.e. if a particular data is repeated multiple times even if you use reduce side join, the particular reducer will be overloaded and it will take a lot of time. Pig itself, calculates skewed join and the skewed key.
And, if you have datasets where the records are sorted in the same field, you can go for sorted join, this also happens in map phase and is very efficient and fast.
Que 12. What is a skewed join?
Ans. While we want to perform a join with a skewed dataset, that means a particular value will be repeated many times, is a skewed join.
Que 13. What is Flatten?
Ans. An operator in pig that removes the level of nesting, is Flatten. Sometimes, we have data in a bag or a tuple and we want to remove the level of nesting so that the data structured should become even, we use Flatten.
In addition, each Flatten produces a cross product of every record in the bag with all of the other expressions in the general statement.
Que 14. What are the complex data types in pig?
Ans. The following are the complex data types in Pig:

Data types in Pig
- Tuple
An ordered set of fields is what we call a tuple.
For Example: (Ankit, 32)
- Bag
A collection of tuples is what we call a bag.
For Example: {(Ankit,32),(Neha,30)}
- Map
A set of key-value pairs is what we call a Map.
For Example: [ ‘name’#’Ankit’, ‘age’#32]
Que 15. Why we use BloomMapFile?
Ans. In order to extend MapFile, we use the BloomMapFile. That implies its functionality is similar to MapFile.
Also, to provide quick membership test for the keys, BloomMapFile uses dynamic Bloom filters. We use it in HBase table format.
Que 16. How will you explain COGROUP in Pig?
Ans. In Apache Pig, COGROUP works on tuples. On several statements, we can apply operators, which contains a few relations at least 127 relations at every time.
When you make use of the operator on tables, then Pig immediately books two tables and join them through some of the columns that are grouped.
Que 17. What is the difference between logical and physical plans?
Ans. Pig undergoes some steps when a Pig Latin Script is converted into MapReduce jobs. After performing the basic parsing and semantic checking, it produces a logical plan. The logical plan describes the logical operators that have to be executed by Pig during execution.
After this, Pig produces a physical plan. The physical plan describes the physical operators that are needed to execute the script.
Que 18. Does ‘ILLUSTRATE’ run MR job?
Ans. It will pull the internal data, illustrate will not pull any MR. Moreover, illustrate will not do any job, on the console. It just shows the output of each stage and not the final output.
Que 19. Is the keyword ‘DEFINE’ as a function name?
Ans. The keyword ‘DEFINE’ is like a function name. As soon as we have registered, we have to define it. Whatever logic you have written in Java program, we have an exported jar and also a jar registered by us.
Now the compiler will check the function in the exported jar. When the function is not present in the library, it looks into our jar.
Que 20. Is the keyword ‘FUNCTIONAL’ a User Defined Function (UDF)?
Ans. The keyword ‘FUNCTIONAL’ is not a User Defined Function (UDF). we have to override some functions while using UDF. Certainly, we have to do our job with the help of these functions only.
However, the keyword ‘FUNCTIONAL’ is a built-in function i.e a predefined function, therefore it does not work as a UDF.
Apache Pig Interview Questions and Answers For Freshers. Q- 12,13,14,15,16,17
Apache Pig Interview Questions and Answers For Experience. Q- 11,18,19,20
Que 21. Why do we need MapReduce during Pig programming?
Ans. Let’s understand it in this way- Pig is a high-level platform that makes many Hadoop data analysis issues easier to execute. And, we use Pig Latin for this platform. Now, a program written in Pig Latin is like a query written in SQL, where we need an execution engine to execute the query.
Hence, when we write a program in Pig Latin, it was converted into MapReduce jobs by pig complier. As a result, MapReduce acts as an execution engine.
Q 22 What are the scalar data types in Pig?
Ans. In Apache Pig, Scalar data types are:
- int -4bytes,
- float -4bytes,
- double -8bytes,
- long -8bytes,
- char array,
- byte array
Que 23 What are the different execution mode available in Pig?
Ans. In Pig, there are 3 modes of execution available:
- Interactive Mode (Also known as Grunt Mode)
- Batch Mode
- Embedded Mode
Que 24. Whether Pig Latin language is case-sensitive or not?
Ans. We can say, Pig Latin is sometimes not a case-sensitive, for example, Load is equivalent to load.
A=load ‘b’ is not equivalent to a=load ‘b’
Note: UDF is also case-sensitive, here count is not equivalent to COUNT.
Que 25. What is the purpose of ‘dump’ keyword in Pig?
Ans. The keyword “dump” displays the output on the screen.
For Example- dump ‘processed’
Que 26. Does Pig give any warning when there is a type mismatch or missing field?
Ans. The pig will not show any warning if there is no matching field or a mismatch. However, if any mismatch occurs, it assumes a null value in Pig.
Que 27. What is Grunt shell?
Ans. Grunt shell is also what we call as Pig interactive shell. Basically, it offers a shell for users to interact with HDFS.
Que 28. What co-group does in Pig?
Ans. Basically, it joins the data set by grouping one particular data set only. Moreover, it groups the elements by their common field and then returns a set of records containing two separate bags.
One bag consists of the record of the first data set with the common data set, while and other bag consists of the records of the second data set with the common data set.
Que 29. What are relational operations in Pig latin?
Ans. Relational operations in Pig Latin are:
- For each
- Order by
- Filters
- Group
- Distinct
- Join
- Limit
Que 30. How is Pig Useful For?
Ans. There are 3 possible categories for which we can use Pig. They are:
1) ETL data pipeline
2) Research on raw data
3) Iterative processing
Apache Pig Interview Questions and Answers For Freshers. Q- 21,22,25,26,27,28,29,30
Apache Pig Interview Questions and Answers For Experience. Q- 23,24
So, this was all about Apache Pig Interview Questions and Answers Tutorial. Hope you like our explanation.
Conclusion: Apache Pig Interview Questions
Hence, we have covered top 30 Apache Pig Interview Questions. However, if any doubt occurs, feel free to ask through the comment tab.
Also, if you have attended Pig interviews previously, we appreciate you to add your Apache Pig Interview Questions in the comments tab. That will help a lot of your fellow job seekers.
You give me 15 seconds I promise you best tutorials
Please share your happy experience on Google




