PySpark SparkContext With Examples and Parameters
\In our last article, we see PySpark Pros and Cons. In this PySpark tutorial, we will learn the concept of PySpark SparkContext. Moreover, we will see SparkContext parameters. Apart from its Parameters, we will also see its PySpark SparkContext examples, to understand it in depth.
So, let’s start PySpark SparkContext.
What is SparkContext in PySpark?
In simple words, an entry point to any Spark functionality is what we call SparkContext. At the time we run any Spark application, a driver program starts, which has the main function and from this time your SparkContext gets initiated.
Afterward, on worker nodes, driver program runs the operations inside the executors.
In addition, to launch a JVM, SparkContext uses Py4J and then creates a JavaSparkContext. However, PySpark has SparkContext available as ‘sc’, by default, thus the creation of a new SparkContext won’t work.
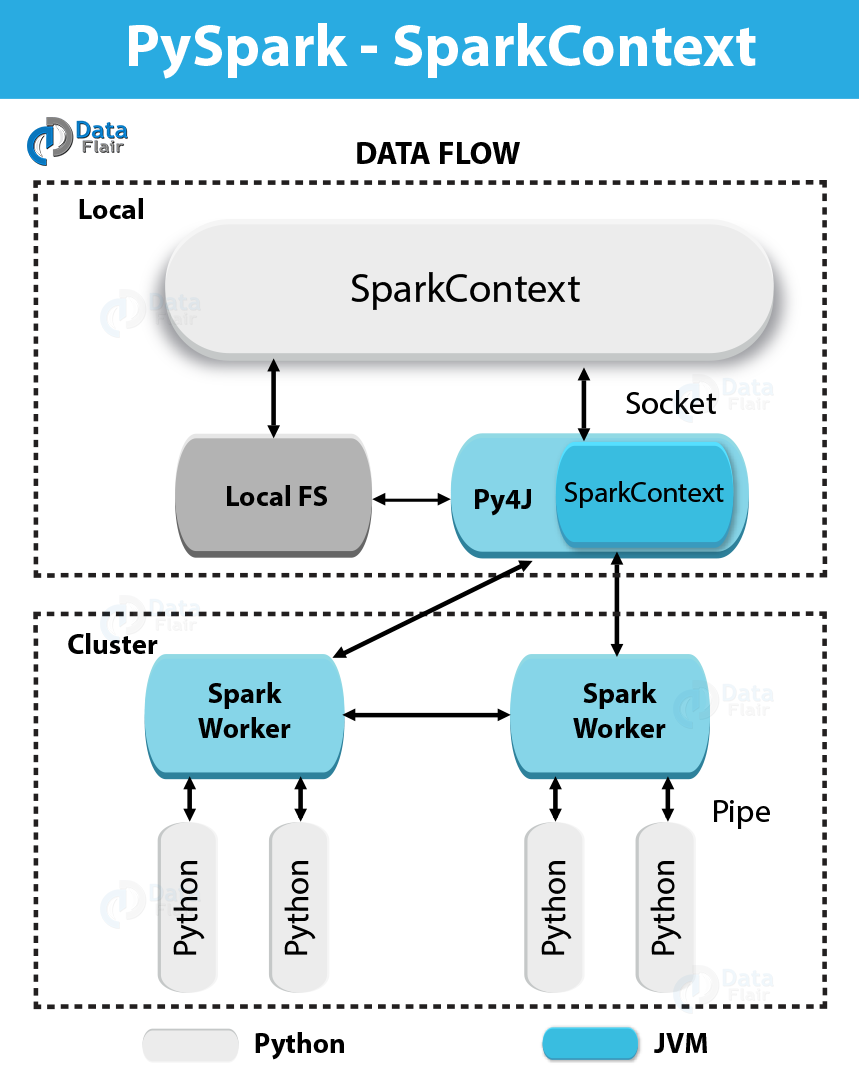
what is PySpark SparkContext
Here is a code block which has the details of a PySpark class as well as the parameters, those a SparkContext can take:
class pyspark.SparkContext ( master = None, appName = None, sparkHome = None, pyFiles = None, environment = None, batchSize = 0, serializer = PickleSerializer(), conf = None, gateway = None, jsc = None, profiler_cls = <class 'pyspark.profiler.BasicProfiler'> )
Parameters in PySpark SparkContext
Further, we are listing all the parameters of a SparkContext in PySpark:
a. Master
This is the URL of the cluster it connects to.
b. appName
Basically, “appName” parameter refers to the name of your job.
c. SparkHome
Generally, sparkHome is a Spark installation directory.
d. pyFiles
Files like .zip or .py files are to send to the cluster and to add to the PYTHONPATH.
e. Environment
Worker nodes environment variables.
f. BatchSize
Basically, as a single Java object, the number of Python objects represented. However, to disable batching, Set 1, and to automatically choose the batch size based on object sizes set 0, Also, to use an unlimited batch size, set -1.
g. Serializer
So, this parameter tell about Serializer, an RDD serializer.
h. Conf
Moreover, to set all the Spark properties, an object of L{SparkConf} is there.
i. Gateway
Basically, use an existing gateway as well as JVM, else initialize a new JVM.
j. JSC
However, JSC is the JavaSparkContext instance.
k. profiler_cls
Basically, in order to do profiling, a class of custom Profiler is used. Although, make sure the pyspark.profiler.BasicProfiler is the default one.
So, master and appname are mostly used, among the above parameters. However, any PySpark program’s first two lines look as shown below −
from pyspark import SparkContext
sc = SparkContext("local", "First App1")SparkContext Example – PySpark Shell
Since we have learned much about PySpark SparkContext, now let’s understand it with an example. Here we will count the number of the lines with character ‘x’ or ‘y’ in the README.md file.
So, let’s assume that there are 5 lines in a file. Hence, 3 lines have the character ‘x’, then the output will be → Line with x: 3. However, for character ‘y’, same will be done .
However, make sure in the following PySpark SparkContext example we are not creating any SparkContext object it is because Spark automatically creates the SparkContext object named sc, by default, at the time PySpark shell starts.
So, If you try to create another SparkContext object, following error will occur – “ValueError: That says, it is not possible to run multiple SparkContexts at once”.
<<< logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md" <<< logData = sc.textFile(logFile).cache() <<< numXs = logData.filter(lambda s: 'x' in s).count() <<< numYs = logData.filter(lambda s: 'y' in s).count() <<< print "Lines with x: %i, lines with y: %i" % (numXs, numYs) Lines with x: 62, lines with y: 30
SparkContext Example – Python Program
Further, using a Python program, let’s run the same example. So, create a Python file with name firstapp1.py and then enter the following code in that file.
----------------------------------------firstapp1.py---------------------------------------
from pyspark import SparkContext
logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"
sc = SparkContext("local", "first app")
logData = sc.textFile(logFile).cache()
numXs = logData.filter(lambda s: 'x' in s).count()
numYs = logData.filter(lambda s: 'y' in s).count()
print "Lines with x: %i, lines with y: %i" % (numXs, numYs)
----------------------------------------firstapp1.py---------------------------------------Then to run this Python file, we will execute the following command in the terminal.
Hence, it will give the same output as above:
$SPARK_HOME/bin/spark-submit firstapp1.py
Output: Lines with x: 62, lines with y: 30
Conclusion
Hence, we have seen the concept of PySpark SparkContext. Moreover, we have seen all the parameters for in-depth knowledge.
Also, we have seen PySpark SparkContext examples to understand it well. However, if any doubt occurs, feel free to ask in the comment tab. Though we assure we will respond.
If you are Happy with DataFlair, do not forget to make us happy with your positive feedback on Google




