Apache Zookeeper Workflow: Nodes in a ZooKeeper
In our last ZooKeeper tutorial, we discussed terminologies in ZooKeeper. In this Zookeeper article, we will learn the complete concept of Zookeeper Workflow in detail.
Also, we will see whole about the effect of having the different number of nodes in the ZooKeeper ensemble to understand Workflow of ZooKeeper well.
So, let’s start ZooKeeper Workflow.
What is Zookeeper Workflow?
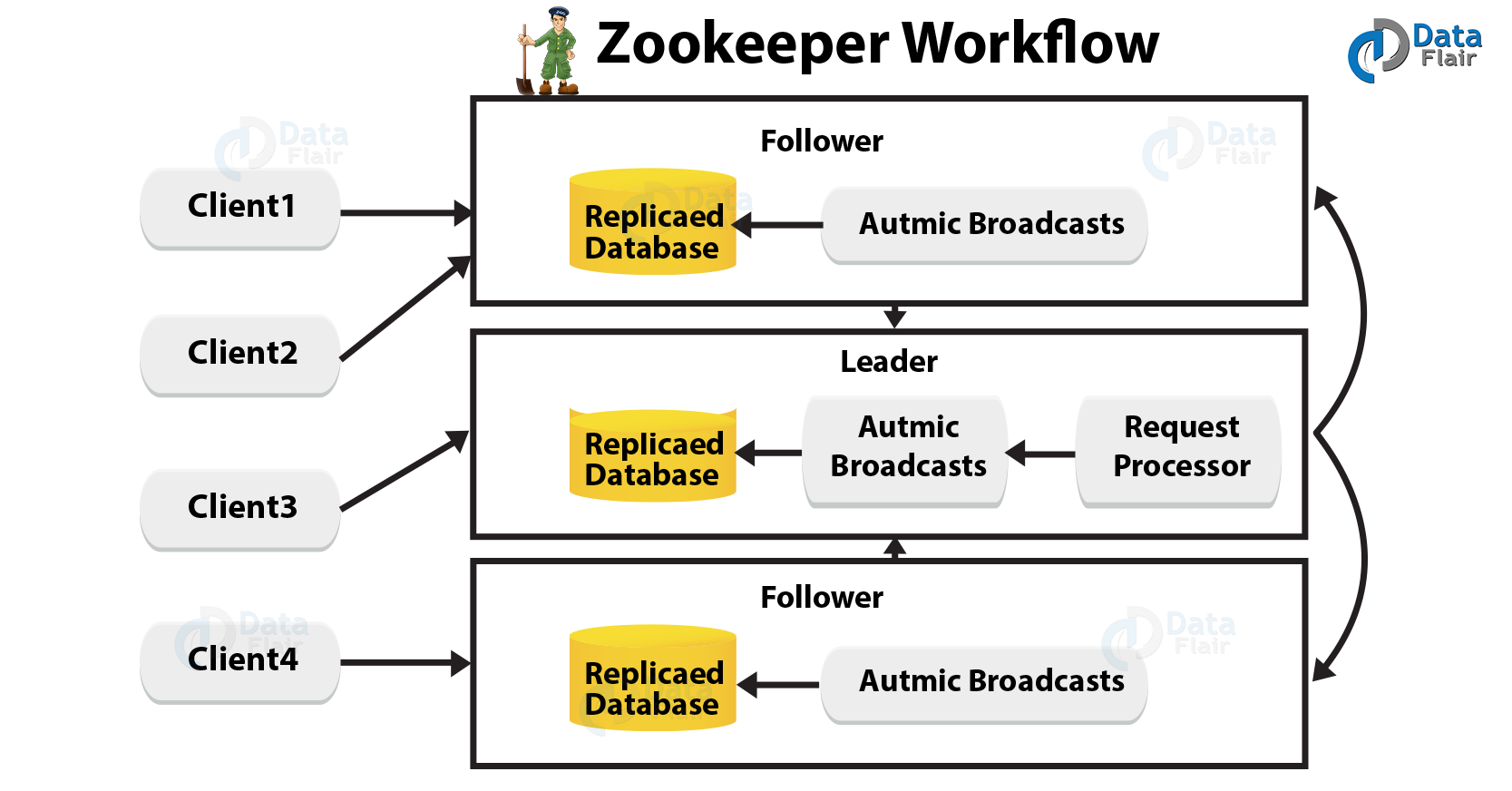
Basically, it works like, Ensemble will wait for the clients to connect, as soon as a ZooKeeper ensemble starts. Hence, in the ZooKeeper ensemble, clients will connect to one of the nodes. Although that node can be a leader or a follower node.
However, the node assigns a session ID to the particular client and sends an acknowledgment to the client, once a client is connected.
Moreover, Client simply tries to connect to another node in the ZooKeeper ensemble, if the client does not get an acknowledgment. Further, the client will send heartbeats to the node in a regular interval to make sure that the connection is not lost, once connected to a node.
Zookeeper Workflow
What is Zookeeper WorkflowDo you know the reason for the popularity of Apache ZooKeeper
In addition, there is a condition like when a client wants to read a particular Znode at that time it sends a read request to the node with the Znode path and the node returns the requested Znode by getting it from its own database. Hence, we can say reads are fast in ZooKeeper ensemble, for this reason.
Moreover, it sends the Znode path and the data to the server, if a client wants to store data in the ZooKeeper ensemble. Furthermore, the leader will reissue the writing request to all the followers just after the connected server will forward the request to the leader.
Also, the write request will succeed and a successful return code will be sent to the client if only a majority of the nodes respond successfully. Else, the write request will fail. Moreover, the strict majority of nodes is what we call a Quorum.
a. Nodes in a ZooKeeper Ensemble
There can be the different number of nodes in the ZooKeeper ensemble. So, let us analyze the effect of changing the nodes in ZooKeeper Workflow:
- The ZooKeeper ensemble fails when that node fails if we have a single node. That’s why it is not recommended in a production environment because it contributes to “Single Point of Failure”.
- We don’t have the majority if we have two nodes and one node fails, because one out of two is not a majority.
- As if one node fails if we have three nodes, then we have the majority which is the least requirement. And to have at least three nodes in a live production environment is mandatory for a ZooKeeper ensemble.
- Four nodes are similar to having three nodes because two nodes fail because if we have four nodes and if two nodes fail, then it fails again. That’s why it is better to add nodes in odd numbers, e.g., 3, 5,7 because extra node does not serve any purpose.
Since all the nodes need to write the same data in its database, a write process is expensive than a read process in the ZooKeeper ensemble. Hence, having a large number of nodes for a balanced environment is better to have less number of nodes (3, 5 or 7).
i. Write
Basically, leader node handles write process. In addition, to all the Znodes, leader forwards the write request and then waits for answers from the znodes. You can be sure about the writing process is complete if half of the Znodes reply.
ii. Read
By a specifically connected Znode, reads are performed internally, hence we do not need interaction with the cluster.
iii. Replicated Database
In zookeeper, to store data we use Replicated Database. However, every Znode has the same data at every time with the help of consistency and each Znode has its own database.
iv. Leader
For processing write requests, the leader is the Znode which is responsible.
v. Follower
Generally, it receives write requests from the clients and then forwards them to the leader Znode.
vi. Request Processor
In the leader node, it is present. And, from the follower node, it governs write requests.
vii. Atomic Broadcasts
The reasons behind changes from the leader node to the follower nodes are Atomic broadcasts.
So, this was all in ZooKeeper Workflow. Hope you like our explanation.
Conclusion
Hence, we have seen the concept of Zookeeper Workflow in detail. Moreover, in this workflow of ZooKeeper, we discussed different nodes in a ZooKeeper assemble. Still, if any doubt occurs regarding ZooKeeper Workflow, ask in the comment tab.
Did you like our efforts? If Yes, please give DataFlair 5 Stars on Google




