Apache Zookeeper Architecture – Diagrams & Examples
Today, in this Apache Zookeeper tutorial, we will discuss ZooKeeper architecture. This architecture of ZooKeeper includes working of ZooKeeper with diagram and different data models.
Moreover, we will learn the design goals of ZooKeeper Architecture, modes and versions in ZooKeeper. We will also saw ZooKeeper Watches and ZooKeeper Quorums.
So, let’s start Apache ZooKeeper Architecture.
What is the Architecture of ZooKeeper?
- ZooKeeper is a distributed application on its own while being a coordination service for distributed systems.
- It has a simple client-server model in which clients are nodes (i.e. machines) and servers are nodes.
- As a function, ZooKeper Clients make use of the services and servers provides the services.
- Applications make calls to ZooKeeper through a client library.
- The client library handles the interaction with ZooKeeper servers here.
Now, the following figure shows the relationship between clients and servers. Here you can see each client imports the client library then further communicate with any ZooKeeper node.
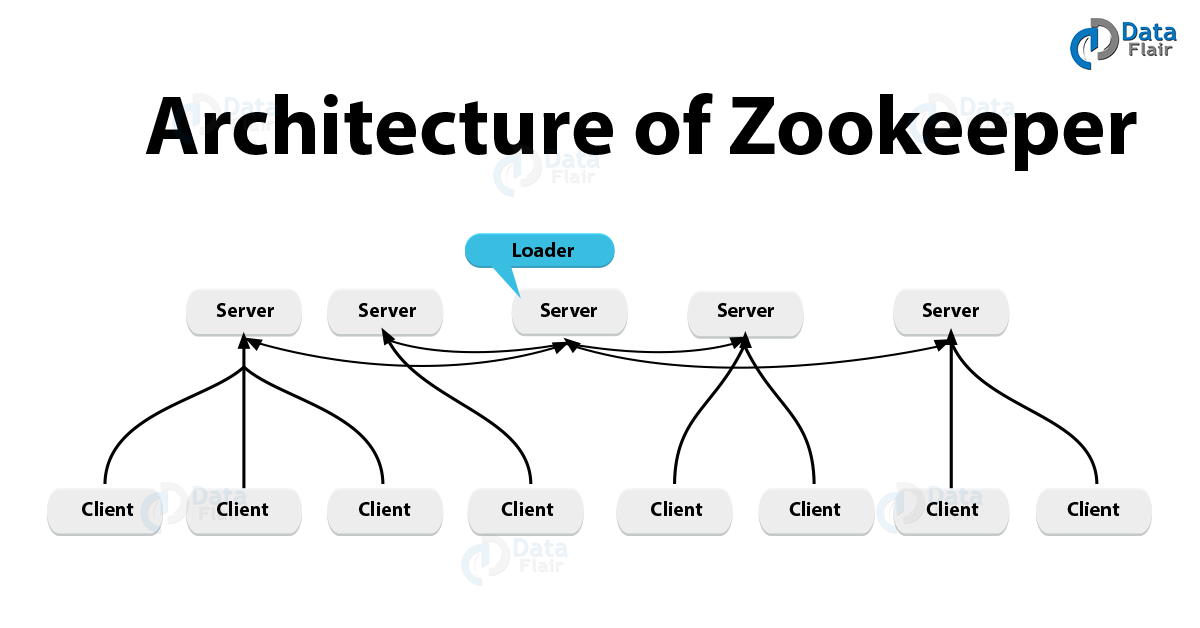
The Architecture of ZooKeeper – ZooKeeper Working
In addition, there are two modes in which Zookeeper runs: standalone and quorum. On defining Standalone mode, it has a single server, and ZooKeeper state is not replicated here.
And, on defining quorum mode, in this mode there is a group of ZooKeeper servers, also what we call it ZooKeeper ensemble, which replicates the state, further, they serve client requests, together.
However, one ZooKeeper client is connected to one ZooKeeper server, at any given time.
As the best feature, each server handles a large number of client connections simultaneously. And, in a periodic manner, each client sends pings to the ZooKeeper server it is connected in order to make sure that it is alive and connected to the server.
Further, with an acknowledgment of the ping, indicating the server is alive as well, the ZooKeeper server responds.
However, the client connects to another server in the ensemble, when the client doesn’t receive an acknowledgment from the server within the specified time. As a result, the client session is transparently transferred over to the new ZooKeeper server.
Design Goals of Zookeeper Architecture
There were some motives behind the design of Zookeeper Architecture:
- ZooKeeper architecture must be able to tolerate failures.
- Also, it must be in the position to recover from correlated recoverable failures (power outages).
- Most importantly it must be correct or easy to implement correctly.
- Additionally, it must be fast along with high throughput and low latency.
Data Model in ZooKeeper
As same as a standard file system, the namespace provided by ZooKeeper. Basically, a sequence of path elements which separates by a slash (/) is what we call a name. In ZooKeeper’s namespace, a path identifies every node.
Moreover, in a ZooKeeper namespace, each node can have data associated with it and its children. As same as a file-system which permits a file to also be a directory.
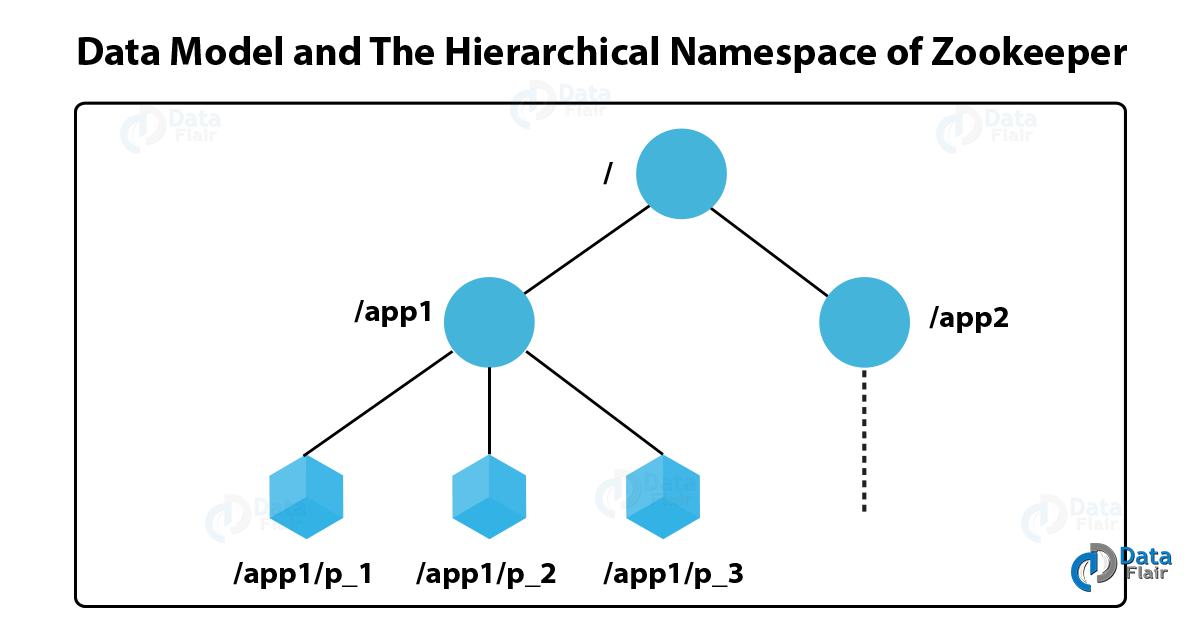
ZooKeeper Data Model
At each ZNode in a namespace, read and write of data is automatically. That says, here Reads get all the data bytes which correspond with a ZNode whereas write replaces all the data. In addition, there is an Access Control List (ACL) with each node that restricts everybody’s work.
Additionally, within each of the ZooKeeper servers, the ZNode hierarchy is stored in memory. Basically, that helps for quick responses to reads from the clients.
This hierarchy can offer reliability, availability, and coordination to our application that’s why we must use it as a storage mechanism for the small amount of data.
a. Information conveyed in ZooKeeper Architecture
The absence of data often conveys important information about a ZNode in ZooKeeper Architecture.
- To all ZNodes representing a worker available in the system, the /workers ZNode is the parent ZNode. So, its ZNode should be removed from /workers, if a worker becomes unavailable.
- Since waiting for workers to execute tasks, the /tasks ZNode is the parent of all the tasks created. In order to represent new tasks and wait for ZNodes representing the status of the task, clients of the master-worker application add new ZNodes as children of /tasks.
- By representing an assignment of a task to a worker, the /assign ZNode is the parent of all ZNodes. Also, it adds a child ZNode to / assigns, when a master assigns a task to a worker.
ZooKeeper Architecture – Modes for ZNodes
We also need to specify a mode, when creating a new ZNode in ZooKeeper architecture. Because different modes explain the behavior of the ZNode:
a. Persistent and Ephemeral znodes
A ZNode can be of any type: either a persistent ZNode or an ephemeral ZNode. Basically, only through a call to delete, we can delete a persistent ZNode/path. And, in contrast, if the client that created it crashes or simply closes its connection to ZooKeeper, an ephemeral ZNode deletes.
Generally, the ZNode stores some data on behalf of an application. Even after its creator is no longer part of the system, and it is a need to preserve its data, in that case, Persistent ZNodes are useful.
Whereas, when some aspect of the application that must exist only while the session of its creator is valid, Ephemeral ZNodes convey information about that.
b. Sequential ZNodes
These ZNodes have a unique, monotonically increasing integer which we further use to create the ZNode. In other words, these offer an easy way to create ZNodes with unique names. Also, offer a way to easily see the creation order of ZNodes.
ZooKeeper Architecture – Versions
There is a version number that associates with every ZNode. Further, that number increases every time its data changes. Especially, at the time when multiple ZooKeeper clients might be trying to perform operations over the same ZNode, the use of versions is important.
ZooKeeper Watches
In order to get notifications about the changes in the ZooKeeper ensemble, ZooKeeper Watches are a simple mechanism for the client. Also, we can say a watch is a one-shot operation, means it triggers one notification.
However, a client can set a new watch upon receiving each notification just to receive multiple notifications over time.
ZooKeeper Quorums
Basically, a ZooKeeper replicates its data a tree across all servers in the ensemble, in quorum mode. Yet, the delays might be unacceptable, if a client had to wait for every server to store its data before continuing.
Generally, a quorum is the minimum number of legislators needs to be present for a vote, in public administration. In Zookeeper also, it is the minimum number of servers that have to be running and available in order, to make Zookeeper work.
a. How to choose an adequate size for the ZooKeeper Quorum
Choosing the adequate size for the quorum in ZooKeeper is a very important step. We must deploy ZooKeeper in a ZooKeeper cluster known as an ensemble for reliable ZooKeeper service.
Although, the service will be available, as long as a majority of the ensemble are up. So, it is best to use an odd number of machines, since Zookeeper requires a majority.
Now, let’s see an example IN ZooKeeper Architecture to understand it well, this example explains, if the quorum is too small, how things can go wrong. Let’s suppose there are five servers and also a quorum which is set of two servers.
Further, assume such servers s1 and s2 both acknowledge that they both have replicated a request in order to create a ZNode /z. Then in order to say that the Znode is created, the service returns to the client.
Further, let’s say for an arbitrarily long time both the servers s1 and s2 have partitioned away from the other servers and also from clients. Even before they have a chance to replicate the new ZNode to the other servers.
Since there are three servers available and it really needs only two according to our assumptions, the service in this state is able to make progress. However, these three servers are new to the new ZNode /z. Accordingly, the request to create /z is nondurable.
Hence, the size of the quorum must be at least three, which is a majority of the five servers in the ensemble, in order to solve this issue. Also, the ensemble needs at least three servers available just to make progress.
So, we are able to tolerate the crash of servers by using such a majority scheme, make sure here f is less than half of the servers in the ensemble. For example, we can tolerate up to f = 2 crashes, if we have five servers.
However, the number of servers in even number actually makes the system more fragile, so the number of servers in the ensemble is not mandatorily odd. So, assume, we have four servers for an ensemble. And, a majority of servers is consists of three servers.
Since a double crash makes the system lose the majority, this system will only tolerate a single crash. Hence, it is the must that we should always shoot for an odd number of servers.
So, this was all in ZooKeeper Architecture. Hope you like our explanation.
Conclusion: Zookeeper Architecture
Hence, in this ZooKeeper Architecture tutorial, we have seen the whole about Architecture of ZooKeeper in detail. Moreover, we discussed the working of ZooKeeper Architecture and different model and nodes in ZooKeeper.
Along with this, we saw ZooKeeper Architecture versions and design goals. Still, if any doubt occurs regarding ZooKeeper Architecture, feel free to ask in the comment section.
Did you like this article? If Yes, please give DataFlair 5 Stars on Google





There is one typo in this blog
Apache Zookeeper Architecture – Diagrams & Examples section : – There should be “We will also see”